itmo_conspects
Web-разработка: Backend
- Web-разработка: Backend
Презентации доступны в репозитории https://github.com/is-web-y25/lectures
Лекция 1. Введение
Как ранее обсуждалось на курсе фронтенд-разработки, сейчас документный обмен через сеть Интернет преимущественно с помощью веб-технологий
Так браузер на компьютере клиента, используя URL, посылает запрос по HTTP-протоколу на сервер, который отвечает набором файлов, которые задает веб-страницу с помощью языков HTML, CSS и JavaScript
Все ресурсы веб-сайтов делятся на два типа:
- Статические ресурсы - файлы данных, к которым есть доступ из сети интернет:
- HTML-документы
- Изображения
- Мультимедиа файлы
- Динамические ресурсы - программные объекты, которые по запросу генерируют ресурс:
- Web-приложения
- Программные модули (exe, dll)
- Шаблоны web-страниц
- Скрипты (.php, .pl и пр.)
Работа веб-сети основана на пяти ключевых стандартах:
- URL - способ задания адресов ресурсов сети
- HTTP - протокол взаимодействия между клиентами и серверами
- HTML - язык описания гипертекстовых документов
- CSS - язык форматирования гипертекстовых документов
- JavaScript - язык описания программ, выполняемых на стороне клиента
Протокол HTTP (HyperText Transfer Protocol, Протокол передачи гипертекста) является ключевым участником взаимодействия всех участников веб-сети
Протокол HTTP:
- является протоколом прикладного уровня на стеке TCP/IP
- повсеместно используется в формате версий HTTP/1.1, HTTP/2 и HTTP/3
- имеет серверный порт по умолчанию 80 (или 443 для защищенных соединений)
Веб-серверы ещё называют HTTP-серверами, браузеры - HTTP-клиентами, но клиентами могут быть и другие программы: прокси-серверы, поисковые агенты и тому подобное
HTTP работает по принципу запрос-ответ (Request-Response): клиент отправляет запрос, сервер возвращает ответ
HTTP-запрос имеет такую структуру:
МЕТОД /[имя-ресурса][?параметры-запроса] HTTP/номер-версии
Имя-заголовка-1: значение
Имя-заголовка-2: значение
[тело запроса, может отсутствовать]
Здесь:
-
МЕТОД- один из поддерживаемых методов. Всего есть 8 методов с разным назначением:Метод Назначение GETПолучение ресурса. Не имеет тела, а параметры передаются в строке URL POSTОтправка данных на сервер, такой метод имеет тело запроса PUTПолное обновление существующего ресурса PATCHЧастичное обновление существующего ресурса DELETEУдаление ресурса HEADАналог GET, но без тела ответа - только заголовкиOPTIONSЗапрос информации о доступных методах для ресурса TRACEДиагностика пути запроса CONNECTУстановка туннеля к серверу Метод
GET- cамый простой и распространённый метод, использующийся при вводе URL в адресную строку и переходе по ссылке. Метод не имеет тела - данные передаются в строке запроса, например:GET /search?query=http&lang=ru HTTP/1.1 Host: example.comДругой распространенный метод
POSTиспользуется для отправки форм и создания ресурсов. Метод имеет тело запроса - данные передаются внутри сообщения, а не в URL:POST /q HTTP/1.1 Host: finance.yahoo.com User-Agent: Mozilla/4.75 Content-Type: application/json Content-Length: 16 {"key": "value"} /имя-ресурса- путь к запрашиваемому ресурсу на сервере[?параметры-запроса]- параметры запросы, хранящиеся в URL, например,https://www.youtube.com/watch?v=dQw4w9WgXcQ&list=RDdQw4w9WgXcQ&start_radio=1– здесь три параметраv,listиstart_radioномер-версии- версия протокола (1.0, 1.1 или 2.0)Имя-заголовка-1: значение- заголовок
Пример запроса:
GET / HTTP/1.1
Host: httpforever.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.0.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: ru
Запрос пишется в текстовом формате, причем конец блока заголовков обозначается последовательностью \r\n\r\n. Запрос также содержит информацию о клиенте - его операционную систему (здесь это 64-битная Windows 10/11), его браузер (здесь это Microsoft Edge на базе Chromium), движок рендера (здесь это AppleWebKit), и принимаемые кодировки (например, можно заархивировать контент), форматы документов и язык контента
Некоторые строки пишутся для соблюдения совместимости. Например, Mozilla/5.0 отправляется потому, что серверы отдавали расширенный контент только браузерам Mozilla
HTTP-ответ выглядит так:
HTTP/1.1 200 OK
Server: nginx/1.18.0 (Ubuntu)
Date: Sun, 08 Mar 2026 15:13:19 GMT
Content-Type: text/html
Last-Modified: Wed, 22 Mar 2023 14:54:48 GMT
Transfer-Encoding: chunked
Connection: keep-alive
ETag: W/"641b16b8-1404"
Referrer-Policy: strict-origin-when-cross-origin
X-Content-Type-Options: nosniff
Feature-Policy: accelerometer 'none'; camera 'none'; geolocation 'none'; gyroscope 'none'; magnetometer 'none'; microphone 'none'; payment 'none'; usb 'none'
Content-Security-Policy: default-src 'self'; script-src cdnjs.cloudflare.com 'self' 'report-sha256'; style-src cdnjs.cloudflare.com 'self' fonts.googleapis.com 'unsafe-inline'; font-src fonts.googleapis.com fonts.gstatic.com cdnjs.cloudflare.com; frame-ancestors 'none'; report-uri https://scotthelme.report-uri.com/r/d/csp/enforce
Content-Encoding: gzip
[[HTML-документ]]
Здесь содержится информация о типе контента, сервере (nginx/1.18.0 (Ubuntu)), нужных для сайту разрешений браузера (например, геолокация - geolocation 'none')
Первая строка HTTP-ответа содержит трёхзначный код состояния, который сообщает клиенту о результате обработки запроса. Коды делятся на пять категорий:
-
1xx- информационныеИспользуются в поясняющих целях, не сообщают об успехе/неуспехе. Чаще всего встречаются при обновлении протокола (например, при подключении веб-сокета)
-
2xx- успешная обработкаСамые популярные из категории:
200 OK- запрос успешно выполнен, ресурс отправлен клиенту201 Created- запрос успешно выполнен, на сервере создан новый ресурс (для методовPUT/POST)204 No Content- запрос выполнен, но тело ответа отсутствует
-
3xx- перенаправлениеКлиенту нужно выполнить дополнительные действия (обычно - повторить запрос по другому URL)
301 Moved Permanently- ресурс перемещён постоянно на новый адрес302 Found- временное перенаправление303 See Other- ресурс доступен по другому URI методомGET304 Not Modified- ресурс не изменился с последнего запроса (то есть кэш актуален)307 Temporary Redirect- ресурс временно перемещён
-
4xx- ошибки клиента400 Bad Request- запрос неправильно сформирован401 Unauthorized- требуется аутентификация (нужен заголовокAuthorization)403 Forbidden- доступ к ресурсу запрещён404 Not Found- ресурс не найден на сервере
-
5xx- ошибки сервера500 Internal Server Error- внутренняя ошибка сервера501 Not Implemented- сервер не поддерживает запрашиваемый метод505 HTTP Version Not Supported- версия протокола не поддерживается сервером
Помимо информации в URL и теле запроса также есть заголовки - метаданные HTTP-сообщений. Они позволяют управлять сессиями, кэшированием, аутентификацией и авторизацией. Заголовки делятся на четыре группы:
-
Общие заголовки. Могут использоваться как в запросах, так и в ответах. Примером может быть заголовок
Connection, у которого есть два значение:keep-alive- сохранить соединение (используется по умолчанию в HTTP/1.1), иclose- закрыть соединение (поведение по умолчанию в HTTP/1.0) -
Заголовки запроса. Клиент передаёт дополнительную информацию о себе и о запросе. Примеры:
Заголовок Описание HostУказывает, какой сайт запрашивается (нужен для виртуального хостинга) User-AgentОписывает программу, отправившую запрос (браузер, версия ОС) RefererURL страницы, с которой пришёл запрос AuthorizationДанные авторизации (имя/пароль). Отправляется после ответа 401 -
Заголовки ответа. Сервер передаёт дополнительную информацию об ответе. Например:
Заголовок Описание ServerИнформация о веб-сервере (необязательный) LocationURL для перенаправления. Используется с кодами 301, 302, 303, 307 WWW-AuthenticateЗадаётся вместе с кодом 401. Браузер запрашивает у пользователя логин/пароль -
Заголовки содержания. Описывают тело сообщения - тип данных, длину, кодировку и так далее
Для работы веб-приложения нужен веб-сервер - серверная программа, работающая в фоновом режиме, которая принимает HTTP-запросы от клиентов и возвращает HTTP-ответы (обычно HTML-документы)
Современные веб-серверы состоят из модулей, каждый из которых отвечает за свою задачу:
- Модуль разрешения запроса (или роутер, Router)
- Определяет тип контента: статический или динамический
- Преобразует URL-адрес в реальный путь в файловой системе
- Проверяет аутентификацию для защищённых ресурсов
- Модуль обработки запроса
- Обрабатывает статический контент (отдаёт файлы напрямую)
- Обрабатывает динамический контент (передаёт запрос на выполнение приложению)
- Управляет состоянием сеанса, очередями, кэшем
- Модуль формирования HTTP-ответа
- Формирует заголовки ответа
- Объединяет заголовки с результатом обработки
- Передаёт ответ клиенту
Важно, что HTTP не поддерживает состояние сеанса. Вся информация о запросе содержится только в самом запросе (заголовках и теле)
Веб-сервер, как программе, нужно оборудование, на котором он будет работать. В качестве такого оборудования, где веб-сервер может хоститься (от host) могут выступать:
-
Выделенный сервер (Dedicated server) - физический сервер в полном единоличном использовании. Для простеньких проектов выделенным сервером может быть старый ноутбук или одноплатный компьютер, например, Raspberry Pi
К нему есть полный доступ управления, но выделенный сервер имеет высокую стоимость и требует навыков для правильной настройки, чтобы соблюсти надежность и безопасность
-
Виртуальный приватный сервер (Virtual Private Server, VPS) - виртуальный сервер с выделенными ресурсами
Виртуальный приватный сервер - это оборудование, доступ к которому осуществляется через операционную систему с помощью виртуализации или контейнеризации
У виртуального приватного сервера есть выделенные ресурсы (то есть соседние процессы не влияют на производительность), полный доступ в качестве суперпользователя, высокая гибкость настройки, однако такое решение все еще требует квалификации для настройки и поддержки
-
Разделенный сервер (Shared Hosting): несколько клиентов используют один физический сервер совместно
Самое дешёвое решение, часто идут бесплатные домены, не требует технических знаний, но сильные ограничения - нельзя настраивать порты и выбирать нестандартные решения
-
Управляемый сервер (Managed Hosting): провайдер предоставляет конкретное веб-приложение с административным доступом, но управление сервером остается за провайдером. Примером управляемого сервера может быть сервис Tilda
Здесь не нужно разбираться в сервере, но сервер ограничен только возможностями конкретного приложения
-
Провайдеры, специфичные для приложений (App-specific providers) - платформы для разработчиков с готовыми компонентами (такими как базы данных, репозитории, деплой, мониторинг). Примеры: Google AppEngine, Heroku, Render, VMware Pivotal Cloud Foundry
У таких платформ нижний порог входа по сравнению с VPS, есть автоматизация многих процессов, но функционал ограничен функциями платформы, а при росте приложения может стать дорого и тяжело мигрировать
Рассмотрим платформу Render, основанную в 2018 году. Render позиционируется как современная замена Heroku и поддерживает Node.js, Python, Go, Ruby, Java, PHP и другие языки
Render используется для:
- Размещения приложений и веб-сервисов без ручной настройки сервера
- Упрощения и ускорения цикла разработки
- Быстрого масштабирования проектов
- Работы с нагруженными приложениями
Приложения запускаются в изолированных контейнерах, при этом одно приложение может использоваться несколькими контейнерами, что обеспечивает лёгкое масштабирование
Лекция 2. Подходы к разработке веб-приложений
Все подходы к разработке веб-приложений можно разделить на 3 категории:
- Программные подходы, основанные на программировании и скриптах, например, плагины для nginx или скрипты на Lua
- Подходы, основанные на использовании шаблонов веб-страниц, включающих вставки кода скриптов, например, скрипты на PHP
- Объектные среды, то есть полноценные веб-фреймворки с ООП, паттернами, абстракцией и прочим
Программные подходы
Программные подходы состояли в создании программой на универсальном языке высокого уровня (или скрипта, который исполнялся с помощью интерпретатора)
Для этого разметка HTML и другие конструкции форматирования встраивались прямо в логику работы программы с помощью операторов вывода
Такой подход ограничивал возможность дизайнерам вносить изменения в оформление или расположение элементов, так как им пришлось открывать исходный код, знать язык программирования и другие инструменты (или помощь программиста🧑💻)
С помощью такого подхода можно динамически формировать содержимое страницы на HTTP-запрос. Первой такой технологией, которая позволила независимо от типа веб-сервера, была Common Gateway Interface (CGI, не путать с Computer-generated imagery), определявшая набор правил для программы, чтобы она могла выполняться для разных ОС и HTTP-серверов
Технология работала так:
- При поступлении HTTP-запроса определялась, какая программа должна быть запущена (чтобы обеспечивать доступ к разным ресурсам)
- Запускался новый процесс этой программы, переменные окружения которой содержали параметры HTTP-запроса
- Запускалась функция
main(), которая в стандартный поток вывода выводила HTML-страницу
Выглядела она так:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
// Получение переменных окружения
char *method = getenv("REQUEST_METHOD");
char *query = getenv("QUERY_STRING"); // данные запроса
// HTTP-заголовок
printf("Content-Type: text/html; charset=utf-8\r\n\r\n");
printf("<html><body>\n");
printf("<h1>CGI Example in C</h1>\n");
// Информация о методе запроса
printf("<p>Request method: %s</p>\n", method ? method : "unknown");
// Обработка GET
if (method && strcmp(method, "GET") == 0 && query) {
printf("<h2>GET parameters:</h2>\n");
printf("<pre>%s</pre>\n", query);
}
else {
printf("<p>No data received or unsupported method.</p>\n");
}
printf("</body></html>\n");
return 0;
}
Технология CGI позволяла использовать любой язык программирования (в том числе скриптовые, такие как Python или Perl), но были недостатки:
- При новом подключении создавался новый процесс - а создание новое процесса обходится ОС намного дороже, чем содержание текущего (надо захватить ресурсы, оперативную память, потом освободить это все)
- Содержать и обновлять такой код рядовому фронтенд-разработчику или дизайнеру было тяжело, так как требовалось знание языка
Следующей попыткой стала технология FastCGI - в ней вместо создания нового процесса появилась возможность использования существующего
Далее для веб-сервера Internet Information Server (IIS) от Microsoft, который поставлялся с операционной системой Windows Server, был разработан интерфейс ISAPI
Этот интерфейс позволял расширить стандартные возможности веб-сервера. ISAPI представлял библиотеку функций, с помощью которой программисты могли создавать веб-приложения в виде DLL-модулей (Dynamic-Link Library), что работало намного быстрее CGI-приложений
ISAPI-расширения могут связываться с вызовом файлов, имеющих специальные расширения или содержащимися в заданных каталогах. Также были фильтры, которые использовались для изменения функциональности сервера ISS
Такие приложения обычно использовали языки С++, Delphi или платформу .NET
Потом компания Sun Microsystems (разработчик Java) создала прикладной интерфейс Java Servlet API, который связывал веб-сервер с JVM. Виртуальная машина отвечала за выполнение сервлетов (компонент расширения функционала) и программы, которая управляла данными
В отличии от ISAPI-расширений сервлеты являются переносимыми между разными серверами, ОС и компьютерными архитектурами. Сервлеты могут исполняться одинаково в любой среде, если в ней был совместимый контейнер сервлетов (такой, как Apache Tomcat)
Подходы, основанные на шаблонах
Подходы на основе шаблонов используют в качестве объектов, доступных по URL, не скрипты, а шаблоны
Шаблоны представляют HTML-страницы, но в которых динамический контент заменен на особые теги. Сервер обрабатывает запрос, исполняет бизнес-логику и решает, что подставить вместо этих особых тегов (например, имя аккаунта или новостную ленту)
Первым таким подход стал Server Side Includes (SSI), которая позволяла встраивать особые инструкции в HTML-код:
<html>
<head><title>hello</title></head>
<body>
<! -- #exec cgi http://mysite.org/cgi-bin/example.cgi -- >
</body>
</html>
Здесь внутри <body> встраивался контент, полученный CGI-программой
Позднее компания Macromedia (разработчик почившей платформы Flash), выкупила технологию Cold Fusion у компании Allaire Corporation братьев Аллейров
Она использовала в качестве особых тегов теги с приставкой cf:
<!DOCTYPE html>
<html>
<head>
<title>Пример</title>
</head>
<body>
<h1>Добро пожаловать!</h1>
<!--- Получаем параметр name из строки запроса --->
<cfparam name="url.name" default="гость">
<p>Привет, <cfoutput>#url.name#</cfoutput>!</p>
</body>
</html>
Далее появился скриптовый язык PHP (рекурсивный акроним от PHP: Hypertext Preprocessor), который мог содержать вставки кода с логикой
<b>
<?php
if ($xyz >= 3) {
$output = $myHeading;
} else {
$output = 'DEFAULT HEADING';
}
echo $output;
?>
</b>
Такие вставки обрабатывались препроцессором PHP на стороне сервера
Далее Microsoft разрабатывает Action Server Pages (или ASP), которая объединила шаблоны и доступ к наборам OLE (Object Linking and Embedding - встраивание и линковка объектов) и COM (Component Object Model - модель компонентных объектов). Они уже позволяли получать данные из базы данных по интерфейсу ODBC (Open Database Connectivity)
В отличие от РНР, ASP не связан с одним конкретным скриптовым языком - в качестве стандартного языка используется язык Visual Basic Scripting Edition (VBScript), но может использоваться и JavaScript
Вставки в ASP оформляются в тегах <% ... %>:
<%@ Language=VBScript %>
<html>
<head>
<title>Пример</title>
</head>
<body>
<h1>Данные из базы данных (ODBC)</h1>
<%
' Создаём объект Connection
Dim conn, rs, sql
Set conn = Server.CreateObject("ADODB.Connection")
conn.Open "DSN=MyDSN;UID=blablabla;PWD=blablabla67;"
' SQL‑запрос
sql = "SELECT EmployeeID, FirstName, LastName, Title FROM Employees WHERE EmployeeID = 127"
' Выполняем запрос, получаем Recordset
Set rs = conn.Execute(sql)
If Not rs.EOF Then
For Each field In rs.Fields
Response.Write "<p>" & field.Value & "</p>"
Next
Else
Response.Write "<p>Нет записей.</p>"
End If
' Закрываем объекты и освобождаем ресурсы
rs.Close
Set rs = Nothing
conn.Close
Set conn = Nothing
%>
</body>
</html>
ASP позволял писать логику и обращение к базе данных прямо в HTML-странице и была встроена в веб-сервер ISS, что делало основным выбором для создания веб-приложения на Windows
SUN в ответ создает Java Server Pages (JSP) для экосистемы Java. Она позволяла встраивать Java-код внутрь HTML-страницы:
<%@ page import="java.io.*" %>
<%! private CustomObject myObject; %>
<h1>My Heading</h1>
<%
for(int i = 0; i < myObject.getCount(); i++) { %>
<p>Item #<%= i %> is '<%= myObject.getItem(i) %>' . </p>
<% } %>
Такой код преобразуется в код сервлета, а HTML-разметка - в операторы вывода. Позже появилась возможность использовать JSP-теги, такие как <jsp:useBean> для внедрения зависимостей и <jsp:getProperty> для получения значения свойства
Подходы на основе объектных сред
Потом придумали объектные среды, такие как фреймворки. Фреймворки представляют платформу, определяющую структуру
Фреймворк разделяет программные модули, ответственные за создание контента (непосредственно бизнес-логика), от модулей, который ответственны за показ этого контента в определенном формате
Сейчас есть два подхода:
-
Подходы, основанные на наборе специальных веб-страниц, связанных с описаниями классов, объекты которых будут создаваться и использоваться при их вызове (например, ASP.Net Web Forms и JSP)
Для их создания используются специальные теги, обрабатываемые на стороне сервера
-
Подходы на основе использования классов, соответствующих архитектурному шаблону MVC - Модель-Представление-Контроллер (Model-View-Controller)
Шаблон MVC состоит из трех модулей:
-
Модель - это набор классов, реализующих бизнес-логику
Эти классы отвечают за обработку сущностей и операции с базой данных
-
Представление - набор шаблонов, отвечающих за взаимодействие с пользователем через интерфейс пользователя
Модуль представления формирует HTML-страницы, в которых тем или иным способом представлены сущности модели
-
Контроллер - связка между модулями модели и представления
Контроллер получает данные HTTP-запроса, передает их в модуль модели для обработки. Далее контроллер выбирает нужный модуль представления и передает ему данные от модели
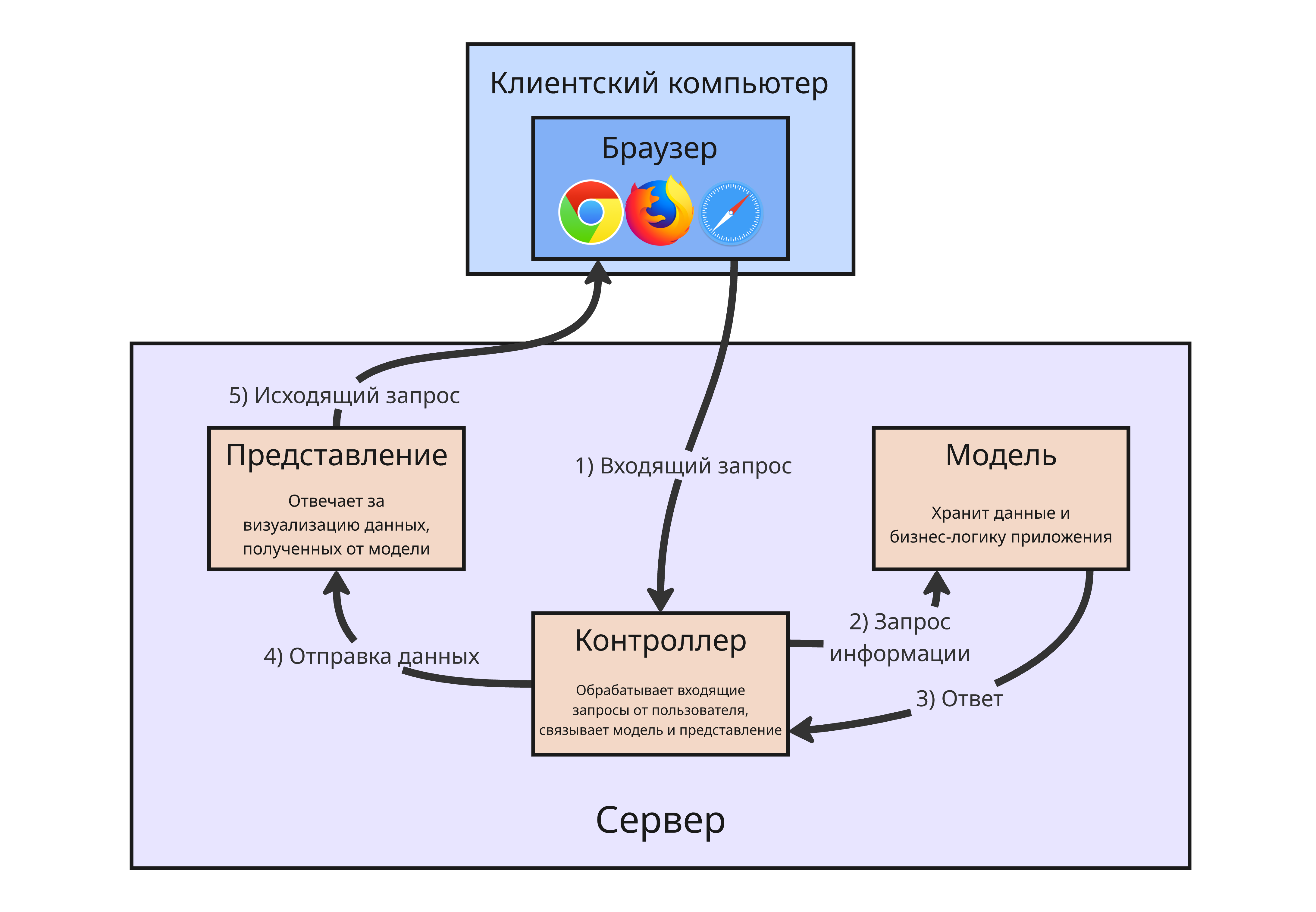
Такое разделение веб-приложения упрощает структуру за счет более строго разделения его уровней
Таким образом, разработчик получает полный контроль над формируемым HTML-документом, и облегчается задача выполнения тестирования приложения
Примерами технологий разработки на основе MVC являются:
- Spring Framework для языка Java
- Технология ASP.Net MVC для платформы .Net Framework
- Технология Ruby on Rails для языка Ruby
Лекция 3. Предметно-ориентированное проектирование
Домен (или предметная область) - это реальная сфера деятельности бизнеса. Модель - это абстракция, которая упрощённо описывает домен, предметы в нем и их взаимоотношений
На этом строится ключевая идея предметно-ориентированного проектирования (Domain-Driven Design, DDD) - приложение должно быть точной моделью реального бизнеса
Такой подход требует дополнительных ресурсов при проектировании архитектуры, однако полученная архитектура получается понятной для разработчиков, которые знакомы с языком домена, и позволяет бизнес-логике не зависеть от технических деталей и реализации
Для начала нужно обеспечить единый, “вездесущий” язык между разработчиками и бизнес-экспертами
Единый язык представляет из себя описание терминов, концептов и того, как бизнес должен работать
Для того, чтобы создать такой язык, для начала нужно посмотреть, как работать бизнес, определить ключевые бизнес-события, команды и процессы, и задокументировать это, используя диаграммы
Иногда домен разделяют и получают ограниченные контексты - четкие границы, внутри которых у модели и понятий единого языка есть точное значение. Так самолет в контексте продажи имеет смысл модели и количество мест в нем; для техобслуживания - это серийный номер и дата последней проверки
Далее из единого языка выделяют сущности - представления вещей в нашей проблемной области
Например, для того, чтобы сделать карту метро, помогающую составить маршрут, нужны сущности:
- Станция
- Линия из станций
- Пассажир
- И маршрут пассажира
Сущность обладает некоторыми свойствами:
- Сущность должна значить что-то клиенту
- Сущность определена с помощью идентичности, которая должна что-то значить клиенту, например, имя станции
- Сущность может изменяться и должна сохранять своей состояние
- Сущность имеет жизненный цикл
Сущности - ключевое понятие в предметно-ориентированном дизайне, но чаще всего на уровне кода разработчики оперируют с объектами со значением (Value Object). Они:
- Определены по их значениям
- Неизменяемы, просты
- Обычно не существуют без сущности, контрпримеры - дата, адрес, денежная сумма
Также сущности содержат бизнес-логику. Модель, где бизнес-логика содержится в сервисах, а не сущностях, называется анемичной и считается анти-паттерном
Также выделяют агрегат - группу сущностей и объектов со значениями, которая должна оставаться последовательно при сохранении
Далее идут сервисы - представления бизнес-процессов в предметной области. Сервис представляют поведения сущностей, у них нет внутреннего состояния, и чаще всего они соединяют множество объектов
Для сохранения состояния сущностей используют:
- Data Mapper - класс, который передает объекты базе данных и изолирует предметную область от базы данных
- Для сохранения агрегатов лучше всего использовать объектно-реляционное отображение (Object Relational Mapping, ORM), которая умеет работать с графами объектов
Также используют репозиторий для связи с агрегатом
Далее идет прикладной слой, который включает прикладные сервисы - они координируют управлением, то есть вызывают репозитории, запускают доменные сервисы, управляют транзакциями
За ним идет инфраструктурный слой. Инфраструктурные сервисы не содержат бизнес-логики, а только базовые инструменты для поддержания инфраструктуры (например, сервис для отправки сообщения по электронной почте)
Лекция 4. Разработка API
API (Application Programming Interface) - программный интерфейс приложения
Здесь интерфейс - это способы взаимодействия с этим приложением, то есть то, что нужно делать, чтобы обменяться данными с приложением или совершить какое-либо действие
Такие способы принято называть контрактом - соглашение, что сторонний разработчик, придерживаясь этих способов, сможет получить то, что предоставляет приложение
Вследствие этого появились 2 подхода к разработке приложения:
- Сначала код (Code first) - сначала создается бизнес-логика, а потом к ней добавляется контракт
- Сначала контракт (Contract first) - сначала описываются способы взаимодействия, а затем пишется код
До появления веб-приложений API были только у программных библиотек: разработчики библиотек на языке программирования задавали интерфейс в виде сигнатур функций и описания классов, благодаря которым, другие разработчики могли воспользоваться функционалом. Такой подход не требует доступа к сети, но требует знания языка программирования
Когда появились веб-сервисы, развитие получили интерфейсы веб-приложений, доступ к которым осуществлялся через Интернет и протокол HTTP, что позволило не зависеть от языка программирования, на котором было создано веб-приложение
Всего выделилось несколько форматов веб-интерфейсов:
-
SOAP API (Simple Object Access Protocol, дословно “Протокол доступа к простым объектами”) - протокол, по которому веб-сервисы используют XML-документы для обмена запросами и ответами
-
RPC (Remote Procedure Call, Удаленный вызов процедуры) - способ вызвать функцию на удаленном компьютере так, будто она вызывается локально
Сам вызов передается в формате XML (тогда интерфейс называется XML-RPC), JSON (тогда JSON-RPC) или другом удобном
Среди реализаций RPC выделяют фреймворк gRPC, созданный Google. В нем данные передаются в формате буферов протокола (Protocol Buffer, или сокращенно protobuf) через протокол HTTP/2, что позволяет сделать передаваемые данные компактнее
-
REST API (REpresentational State Transfer) - стиль, по которому веб-сервисы позволяют отправлять запросы к ресурсам по URL. Нужная операция указывается как HTTP-метод (
GET,POSTи так далее), а путь (так называемая конечная точка или эндпоинт) указывает тип ресурсаВ качестве формата данных используется JSON или XML
-
GraphQL API (от Graph Query Language) - технология, разработанная в Facebook, которая позволяет пользователям получать именно те данные, которые им нужны (например, статьи, созданные пользователями с 1000 или более подписчиками) через один запрос
Чтобы сторонние разработчики могли воспользоваться каким-либо API, нужно им рассказать то, как интерфейс устроен. Для этого существует документация - описание того, что и куда нужно отправить, чтобы получить желаемый результат
Сейчас большинство веб-интерфейсов представлено в архитектурном стиле REST (так называемые RESTful API), который был описан Роем Филдингом в 2000 году
Ключевая идея REST в том, что у всех доступных ресурсов (таких как пользователи, статьи, продукты и так далее) есть свой URL, и над каждым таким ресурсом действие делается через HTTP-метод по соответствующему URL
Например, GET-запрос по URL http://example.com/users?limit=100 вернет первых 100 пользователей приложения. Здесь:
http://example.com- доменhttp://example.com/users- URL ресурса?limit=100- параметры запроса
В качестве формата передачи данных для REST чаще всего используют JSON (так как он удобен для обработки JavaScript-кодом), но ничего не мешает использовать другие форматы
Также Рой Филдинг описал 5 требований к архитектуре REST API:
-
Модель “Клиент-Сервер” - отделение потребности интерфейса клиента от потребностей сервера, хранящего данные, повышает переносимость кода клиентского интерфейса на другие платформы, а упрощение серверной части улучшает масштабируемость.
-
Отсутствие состояния (сессии клиента) - между запросами сервер не должен хранить состояние клиента, то есть запрос сам по себе должен содержать всю необходимую информацию
-
Кэширование - должно быть явное обозначение кэшируемых и некэшируемых ответов, чтобы клиент получал актуальную информацию
-
Унифицированный интерфейс - все ресурсы идентифицируются в запросах; каждое сообщение содержит достаточно информации, чтобы понять, каким образом его обрабатывать; если клиент хранит представление ресурса, включая метаданные, то он обладает достаточной информацией для модификации или удаления ресурса
-
Прозрачность слоев - клиент не способен определить, общается он напрямую с сервером или с промежуточным слоем
Для упрощения документирования REST-интерфейсов разработали спецификации OpenAPI и RAML. Благодаря им, можно описать, что делает каждый метод, какие параметры ему нужны и так далее, а затем сгенерировать готовый документ
Рассмотрим OpenAPI - спецификация позволяет описать API на языке YAML или JSON:
openapi: 3.0.0
info:
version: 1.0.0
title: Swagger Petstore
license:
name: MIT
servers:
- url: http://petstore.swagger.io/v1
paths:
/pets:
get:
summary: List all pets
operationId: listPets
tags:
- pets
parameters:
- name: limit
in: query
description: How many items to return at one time (max 100)
required: false
schema:
type: integer
maximum: 100
format: int32
responses:
'200':
description: A paged array of pets
headers:
x-next:
description: A link to the next page of responses
schema:
type: string
content:
application/json:
schema:
$ref: '#/components/schemas/Pets'
default:
description: unexpected error
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
# ...
components:
schemas:
Pet:
type: object
required:
- id
- name
properties:
id:
type: integer
format: int64
name:
type: string
tag:
type: string
Pets:
type: array
maxItems: 100
items:
$ref: '#/components/schemas/Pet'
Error:
type: object
required:
- code
- message
properties:
code:
type: integer
format: int32
message:
type: string
Здесь описаны:
- URL запросов
- Описание запроса
- Тип данных параметров и моделей
- Возможные ответы (в том числе содержащие ошибку)
Затем такие инструменты, как Swagger, могут сгенерировать HTML-страницу с документацией:
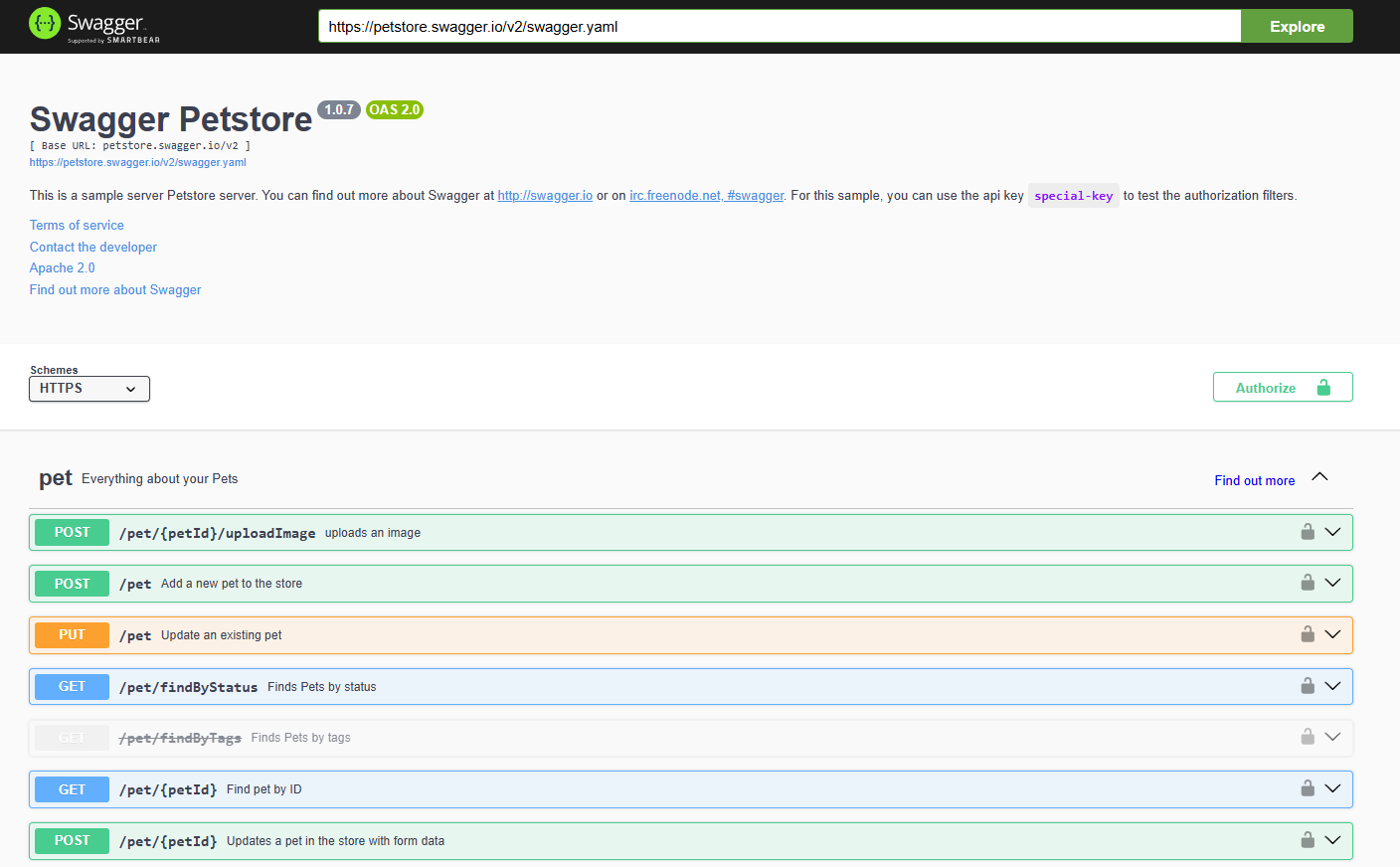
Лекция 5. Бэкенд для фронтенда
Простейшая архитектура веб-приложения часто выглядит так: есть сервер, который отдает готовые HTML-страницы, и есть дополнительные сервисы, например база данных, очередь сообщений, внешние API и файловое хранилище
Такой подход работает, но со временем у него появляются ограничения:
- Один и тот же сервер одновременно отвечает и за бизнес-логику, и за представление данных
- Потребности веб-клиента, мобильного клиента и других интерфейсов начинают смешиваться
- Сервер часто превращается в промежуточный слой, который просто собирает данные из других сервисов
- Фронтенду бывает неудобно получать данные в нужной форме
Но можно внести ряд улучшений:
- Заменить JSON на GraphQL. Таким образом, мы убираем лишнюю логику, отвечающую за представление данных, а клиенты могут выбирать, какие именно данные им нужны
- Вынести рендеринг HTML-документов на отдельный сервер, который будет обращаться за данными к бэкенд-серверу
- Разбить бэкенд на множество микросервисов
В итоге получаем, что в каждом сервисе нет зависимости от языка и от фреймворка, а бэкенд-разработчик не взаимодействует с сервисами, которые ему не требуются
Так появляется архитектурный паттерн “бэкенд для фронтенда” - в нем для каждого уникального фронтенда есть свой бэкенд. Этот бэкенд будет заниматься:
- аутентификацией и авторизацией
- валидацией входных данных
- агрегацией данных из нескольких сервисов
- преобразованием ответа в удобный для клиента формат
- кэшированием
- логированием и трассировкой запросов
Серверный фреймворк Nest для Node.js отлично подходит для этой задачи. Его архитектура включает:
- модули
- контроллеры и сервисы
- контейнер внедрения зависимостей
- промежуточное ПО (middleware), пайпы, охраняющие декораторы (guard), интерцепторы и фильтры
- интеграция с OpenAPI (то есть возможность сгенерировать готовую документацию для Swagger), WebSocket, GraphQL, микросервисами
- удобная структура для тестирования
Также Nest концептуально похож на Angular:
- используется модульность
- активно применяются декораторы
- есть внедрение зависимостей
Базовые элементы Nest
Архитектура Nest строится вокруг модулей. Модуль объединяет связанные части приложения:
- контроллеры
- сервисы
- другие провайдеры
Контроллер принимает HTTP-запрос и возвращает ответ. В нем не стоит хранить сложную бизнес-логику: обычно он лишь принимает параметры, вызывает сервис и возвращает результат.
import { Controller, Get, Param, ParseIntPipe } from '@nestjs/common';
import { UsersService } from './users.service';
@Controller('users')
export class UsersController {
constructor(private readonly usersService: UsersService) {}
@Get(':id')
findOne(@Param('id', ParseIntPipe) id: number) {
return this.usersService.findOne(id);
}
}
Здесь:
@Controller('users')задает базовый путь@Get(':id')связывает метод сGET /users/:idParseIntPipeпреобразует параметр строки в число и выбросит ошибку, если преобразование невозможно
Сервис обычно содержит прикладную или бизнес-логику:
import { Injectable, NotFoundException } from '@nestjs/common';
@Injectable()
export class UsersService {
private readonly users = [
{ id: 1, name: 'Alice' },
{ id: 2, name: 'Bob' },
];
findOne(id: number) {
const user = this.users.find((item) => item.id === id);
if (!user) {
throw new NotFoundException('Пользователь не найден');
}
return user;
}
}
@Injectable() означает, что класс можно зарегистрировать в контейнере зависимостей и внедрять в другие классы
Модуль описывает, какие контроллеры и провайдеры относятся к одной области приложения.
import { Module } from '@nestjs/common';
import { UsersController } from './users.controller';
import { UsersService } from './users.service';
@Module({
controllers: [UsersController],
providers: [UsersService],
})
export class UsersModule {}
Запуск HTTP-приложения обычно происходит в main.ts:
import { NestFactory } from '@nestjs/core';
import { ValidationPipe } from '@nestjs/common';
import { AppModule } from './app.module';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
app.useGlobalPipes(
new ValidationPipe({
whitelist: true,
transform: true,
}),
);
await app.listen(3000);
}
bootstrap();
Глобальный ValidationPipe здесь:
- удаляет лишние поля (
whitelist) - преобразует типы на основе DTO (
transform)
Одна из ключевых идей Nest - внедрение зависимостей. Если сервису нужен другой сервис, его можно не создать вручную, а получить от контейнера:
constructor(private readonly usersService: UsersService) {}
Плюсы такого подхода:
- код слабее связан
- классы проще тестировать
- зависимости удобно подменять
В Nest зависимости обычно называются провайдерами
Для описания входных данных обычно используют DTO (Data Transfer Object)
import { IsEmail, IsString, MinLength } from 'class-validator';
export class CreateUserDto {
@IsEmail()
email: string;
@IsString()
@MinLength(2)
name: string;
}
Использование в контроллере:
import { Body, Controller, Post } from '@nestjs/common';
@Controller('users')
export class UsersController {
@Post()
create(@Body() dto: CreateUserDto) {
return dto;
}
}
Валидация в Nest обычно строится так:
- декораторы из
class-validatorописывают правила ValidationPipeзапускает проверку и преобразование
Пайпы в Nest - это специальные классы, которые могут:
- валидировать данные
- преобразовывать данные
- отклонять некорректный запрос до входа в метод контроллера
Примеры встроенных pipe: ValidationPipe, ParseIntPipe, ParseBoolPipe, ParseUUIDPipe
Продвинутые элементы Nest
Охраняющие декораторы (или гуарды, от guard) проверяют, можно ли вообще выполнять обработчик запроса
Типичный пример - это проверка JWT (JSON Web Token) для авторизации и ролей пользователя
import { CanActivate, ExecutionContext, Injectable } from '@nestjs/common';
@Injectable()
export class AuthGuard implements CanActivate {
canActivate(context: ExecutionContext): boolean {
const request = context.switchToHttp().getRequest();
return Boolean(request.headers.authorization);
}
}
Использование:
@UseGuards(AuthGuard)
@Get('profile')
getProfile() {
return { ok: true };
}
Интерцептор оборачивает вызов обработчика. Он может:
- логировать время выполнения
- менять формат ответа
- добавлять кэширование
- работать с потоками данных через
Observable
import {
CallHandler,
ExecutionContext,
Injectable,
NestInterceptor,
} from '@nestjs/common';
import { map, Observable } from 'rxjs';
@Injectable()
export class ResponseInterceptor implements NestInterceptor {
intercept(
context: ExecutionContext,
next: CallHandler,
): Observable<unknown> {
return next.handle().pipe(
map((data) => ({
data,
timestamp: new Date().toISOString(),
})),
);
}
}
Фильтры перехватывают исключения и преобразуют их в HTTP-ответ:
import {
ArgumentsHost,
Catch,
ExceptionFilter,
HttpException,
} from '@nestjs/common';
@Catch(HttpException)
export class HttpErrorFilter implements ExceptionFilter {
catch(exception: HttpException, host: ArgumentsHost) {
const response = host.switchToHttp().getResponse();
const status = exception.getStatus();
response.status(status).json({
statusCode: status,
message: exception.message,
});
}
}
Это полезно, например, для создания шаблонных страниц с ошибками, такими как HTTP 404
Промежуточное ПО (Middleware) выполняется раньше, чем гуарды и контроллер. Он удобен для:
- логирования
- добавления данных в объект запроса
- общих сквозных действий
import { Injectable, NestMiddleware } from '@nestjs/common';
import { NextFunction, Request, Response } from 'express';
@Injectable()
export class LoggerMiddleware implements NestMiddleware {
use(req: Request, res: Response, next: NextFunction) {
console.log(`${req.method} ${req.originalUrl}`);
next();
}
}
Nest хорошо интегрируется с ORM и драйверами баз данных. Часто используют библиотеки:
- TypeORM
- Prisma
- Sequelize
- Mongoose для MongoDB
Для этого реализуют репозиторий - абстракцию доступа к данным. Репозиторий скрывает детали хранения и предоставляет понятный интерфейс для предметной области. Например:
interface UsersRepository {
findById(id: number): Promise<User | null>;
save(user: User): Promise<void>;
}
При работе с базой данных часто различают два подхода:
- Сначала код (Code first) - сначала описываются сущности и модели в коде, затем по ним создается схема БД
- Сначала база данных (Database first) - сначала существует схема базы данных, а код и модели подстраиваются под нее
Nest поддерживает оба подхода через выбранный инструмент доступа к данным
Кэширование в бэкенде для фронтенда особенно полезно, если один и тот же клиент часто запрашивает одинаковые агрегированные данные. В Nest кэширование можно подключать через менеджер кэширования, а в качестве внешнего хранилища часто используют Redis
Redis полезен, когда нужно:
- хранить кэш между несколькими экземплярами приложения
- быстро читать часто используемые данные
- задавать время жизни для автоматического истечения кэша
Для документирования HTTP API в Nest часто используют Swagger-модуль, который строит OpenAPI-описание
Пример настройки:
import { NestFactory } from '@nestjs/core';
import { DocumentBuilder, SwaggerModule } from '@nestjs/swagger';
import { AppModule } from './app.module';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
const config = new DocumentBuilder()
.setTitle('Users API')
.setDescription('Документация сервиса пользователей')
.setVersion('1.0')
.build();
const document = SwaggerModule.createDocument(app, config);
SwaggerModule.setup('api', app, document);
await app.listen(3000);
}
bootstrap();
Для описания DTO используют декораторы:
import { ApiProperty } from '@nestjs/swagger';
export class CreateUserDto {
@ApiProperty({ example: 'user@example.com' })
email: string;
}
В Nest можно создавать свои декораторы, чтобы повторно использовать типичную логику. Например, чтобы получать текущего пользователя из запроса:
import { createParamDecorator, ExecutionContext } from '@nestjs/common';
export const CurrentUser = createParamDecorator(
(_data: unknown, ctx: ExecutionContext) => {
const request = ctx.switchToHttp().getRequest();
return request.user;
},
);
Использование:
@Get('me')
getMe(@CurrentUser() user: User) {
return user;
}
На практике Nest часто используется как API-слой для фронтенда. Он может:
- отдавать REST API
- отдавать GraphQL API
- агрегировать ответы нескольких внутренних сервисов
- выполнять серверную валидацию
- обеспечивать авторизацию
Для фронтенда это удобно, потому что:
- клиент получает данные в ожидаемом формате
- чувствительная логика не уходит в браузер
- меняется внутреннее устройство сервисов, но контракт BFF можно сохранить стабильным
Лекция 6. GraphQL и Prisma
Prisma
Prisma - объектно-реляционное отображение (Object Relational Mapping, ORM) с открытым исходным кодом для экосистемы Node.js и TypeScript
Prisma состоит из следующих компонентов:
- Prisma Client - автогенерируемый клиент базы данных
- Prisma Migrate - декларативное моделирование данных и миграций с возможностью пользовательского редактирования
- Prisma Studio - пользовательский интерфейс для просмотра и редактирования данных
Prisma упрощает работу с базой данных, а именно моделированием данных, миграцией и написанием запросов
Моделирование данных указывается в файле с расширением .prisma:
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
createdAt DateTime? @default(now()) @map("created_at")
posts Post[]
@@map("users")
}
model Post {
id Int @id @default(autoincrement())
title String
content String?
user User @relation(fields: [authorId], references: [id])
authorId Int? @map("author_id")
published Boolean? @default(false)
createdAt DateTime? @default(now()) @map("created_at")
@@map("posts")
}
Каждая из этих моделей описывает таблицу в соответствующей базе данных и служит основой для сгенерированного доступа к данным с интерфейсом, который предоставляет Prisma Client
Далее Prisma Migrate преобразует эту схему в SQL-запросы, необходимые для создания и изменения таблиц в базе данных. Чтобы сделать миграцию на базе данных, нужно применить команду npx prisma migrate
Например, схема выше превратится в такие запросы на диалекте PostgreSQL:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email VARCHAR(255) NOT NULL UNIQUE,
name VARCHAR(100),
created_at TIMESTAMP DEFAULT NOW()
);
CREATE TABLE posts (
id SERIAL PRIMARY KEY,
title VARCHAR(200) NOT NULL,
content TEXT,
author_id INTEGER REFERENCES users(id),
published BOOLEAN DEFAULT false,
created_at TIMESTAMP DEFAULT NOW()
);
Основным преимуществом работы с Prisma Client является то, что он позволяет разработчикам мыслить объектами и поэтому предлагает привычный и естественный способ рассуждать о своих данных. Prisma Client помогает сформировать запросы к базе данных, которые всегда возвращают простые объекты JavaScript
Помимо этого, если использовать TypeScript, результаты запросов получаются типизированными, что повышает типобезопасность
Отдельное приложение Prisma Studio позволяет управлять базой данных из интерфейса
GraphQL
GraphQL - это язык запросов и манипулирования данными, который позволяет клиенту явно указать, какие данные ему нужны, облегчает агрегацию данных и использует систему типов для описания данных
GraphQL был создан в Facebook в 2012 году и был публично выпущен в 2015. Его основная цель - решить проблемы и ограничения, связанные с интерфейсами в стиле REST
Допустим, что есть авторская статья и список людей, которые лайкнули ее. До появления GraphQL, чтобы получить этот список, нужно было:
- либо сделать эндпоинт, который вместе со статьей выдавал список лайков - тогда при большом числе лайков приложение может работать медленно
- либо сделать два разных эндпоинта, один из которых выдает информацию о статье без списка лайков, а второй - статью со списком лайков (или отдельно сам список)
Такие проблемы, когда сервис возвращает больше данных, чем клиенту нужно (избыточность или overfetching), и когда клиенту нужно несколько запросов, чтобы получить нужные данные (недостаточность или underfetching), присуще REST API
GraphQL способен по схеме запроса, переданной лишь по одному эндпоинту, понимать, какие данных из каких источников нужно взять, и возвращать их
GraphQL API обычно построен из трех компонентов:
-
Запросы
Запросы позволяют клиенту указать, какие данные ему нужны. Такой запрос передает в теле HTTP-запроса, например:
query { post(id: 1) { title author { name } } }Запросы поддерживают вложенность, массивы, фильтрацию
query { posts(onlyPublished: true) { id title author { id name } } }А также можно сделать параметры фильтрации динамическими:
query GetPost($postId: Int!) { post(id: $postId) { id title content } } -
Распознаватели
Распознаватели (Resolver) дают понять, откуда брать запрашиваемые запросом данные
import { Args, Int, Query, Resolver } from '@nestjs/graphql'; import { PrismaService } from '../prisma/prisma.service'; @Resolver() export class PostsResolver { constructor(private readonly prisma: PrismaService) {} @Query(() => Post, { nullable: true }) post(@Args('id', { type: () => Int }) id: number) { return this.prisma.post.findUnique({ where: { id }, include: { author: true, }, }); } } -
Схема
Схема описывает, какие типы данных вообще существуют в API, какие поля у них есть и какие запросы доступны клиенту. Пример схемы:
type User { id: Int! email: String! name: String } type Post { id: Int! title: String! content: String published: Boolean! author: User! } type Query { post(id: Int!): Post posts(onlyPublished: Boolean): [Post!]! }
Кроме чтения данных, GraphQL поддерживает изменение данных через мутации. Пример мутации для создания поста:
mutation {
createPost(
title: "Новый пост"
content: "Текст поста"
authorId: 1
) {
id
title
published
}
}
На практике GraphQL часто используют вместе с Prisma:
- GraphQL отвечает за удобный контракт API для клиента
- Prisma отвечает за удобный и типобезопасный доступ к базе данных
Лекция 7. Аутентификация
Идентификация - процедура распознавания субъекта по его идентификатору
Компьютеры не умеют распознавать людей или другие объекты, поэтому нужна вещь, которая бы олицетворяла субъект в информационной системе. Идентификатором может быть номер телефона, номер паспорта или адрес электронной почты
Аутентификация - процедура проверки подлинности субъекта. Проверить можно тремя способами:
- По тому, что субъект знает, например, пароль или ПИН-код
- По тому, что субъект имеет, например, ключ-карта или цифровая подпись на USB-накопителе
- По тому, что является частью субъекта, то есть биометрия, например, сетчатка глаза, лицо или отпечаток пальца
Авторизация - это предоставление доступа к какому-либо ресурсу, например, к панели управления магазина
Обычно, чтобы усилить безопасность, применяют многофакторную аутентификацию - в ней субъекту нужно несколькими способами подтвердить, что именно он является пользователем. Наиболее распространена двухфакторная аутентификация (2FA или Two-Factor Authentication): например, сначала пользователь вводит пароль от учетной записи, а затем прикладывает отпечаток пальца
Также выделяют многоэтапную аутентификацию - процесс, в котором проверяется подлинность по одному фактору несколько раз, например, по паролю и пришедшему коду на электронную почту
Выбор подхода к тому, как проводить аутентификацию, зависит от желаемой степени защищенности ресурса. Например, если требуется защитить информационный форум, то достаточно будет пароля, однако если потенциальный ущерб от взлома будет большим, то следует внедрить многофакторную аутентификацию
Стандартная схема аутентификации по логину и паролю применительно к веб-приложениям может имплементироваться разными способами
Аутентификация по HTTP
При обращении к защищенному ресурсу сервер отправляет HTTP-ответ, содержащий статус 401 Unauthorized и заголовок WWW-Authenticate, где указана схема аутентификации
Далее браузер отображает свое диалоговое окно, где пользователь вводит логин (например, username) и пароль (password). После этого браузер каждый раз при доступе к ресурсу отправляет эти данные в заголовке Authorization в HTTP-запросе. После этого сервер решает, предоставлять доступ или нет
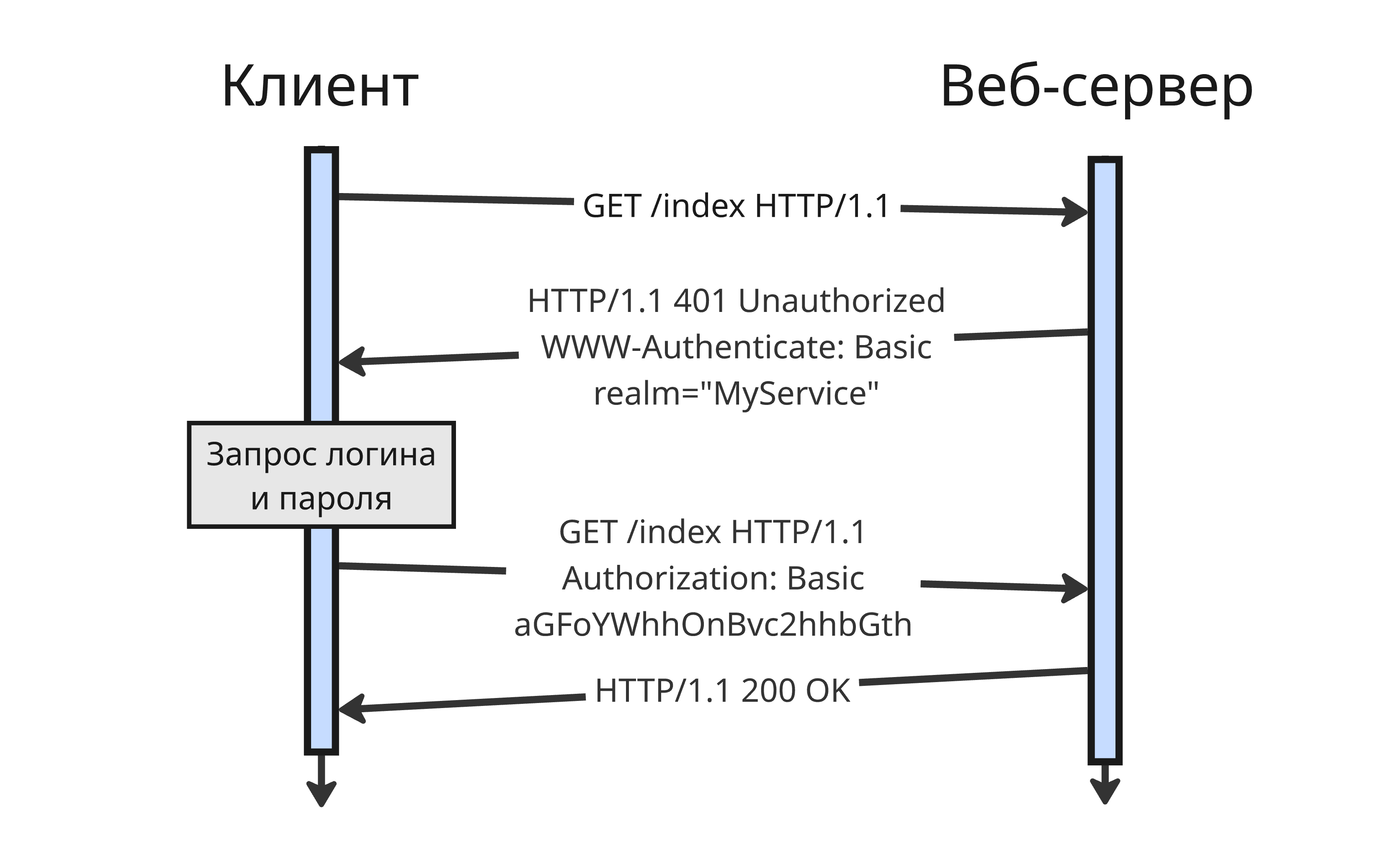
Сами логин и пароль могут храниться внутри заголовка несколькими способами (их называют схемами):
-
Basic (Базовая схема)
В ней данные аутентификации представляются в виде строки
username:passwordв кодировке Base64, использующей буквы латинского алфавита, цифры и 2 специальных символаКодировка Base64 обратима, поэтому, если общение идет через протокол HTTP, то логин и пароль видны всем участникам сети.
По этой причине схему Basic нужно всегда использовать в связке с HTTPS, который шифрует заголовки
-
Digest (от англ. переваривать)
Схема Digest работает так: сервер шлет клиенту уникальное число
nonce, далее клиент используетusername,password,nonce, URI ресурса и другие параметры для вычисления хеша, используя функцию MD5 или SHA-256Такая схема лучше, чем Basic, но уязвима к атакам “человек посередине” (man-in-the-middle attack, MITM): посредник может перехватить ответ сервера, а котором он говорит использовать схему Digest, и отправить клиенту ответ с просьбой использовать Basic, тем самым получив его пароль
-
NTLM (New Technology LAN Manager)
NTLM - семейство протоколов аутентификации, созданный компанией Microsoft
В нем пароль не передается напрямую, а тоже как хеш от пароля и случайного числа сервера
NTLM встроен в экосистему Windows и преимущественно используется для аутентификации пользователей Windows Active Directory
NTLM не защищен к атаке на хеш, ретрансляции аутентификации и подбору пароля
-
HTTP Negotiate
Далее появился протокол Kerberos, который намного безопаснее NTLM, из-за чего появилась схема Negotiate - клиент, отправляя запрос серверу, передает, какой протокол он поддерживает NTLM или Kerberos
HTTP Negotiate также называют SPNEGO (Simple and Protected GSS-API Negotiation Mechanism)
Также Kerberos поддерживает технологию единого входа (Single Sign-On, SSO): при переходе из одного портала в другой пользователь может повторно не проходить аутентификацию, используя токен первого портала
Важно заметить, что при использовании HTTP-аутентификации единственный способ выйти из учетной записи - это закрыть окно браузера
Аутентификация с помощью формы
Далее пришли к тому, что можно создать форму на HTML-странице, где пользователь вводит логин, пароль (и дополнительно другие данные), которые отправляются на сервер для аутентификации. В случае успеха веб-приложение генерирует токен сессии (число, по которому происходит авторизация) и сохраняет его в куки. После этого при каждом запросе клиент отправляет на сервер куки, содержащие токен сессии
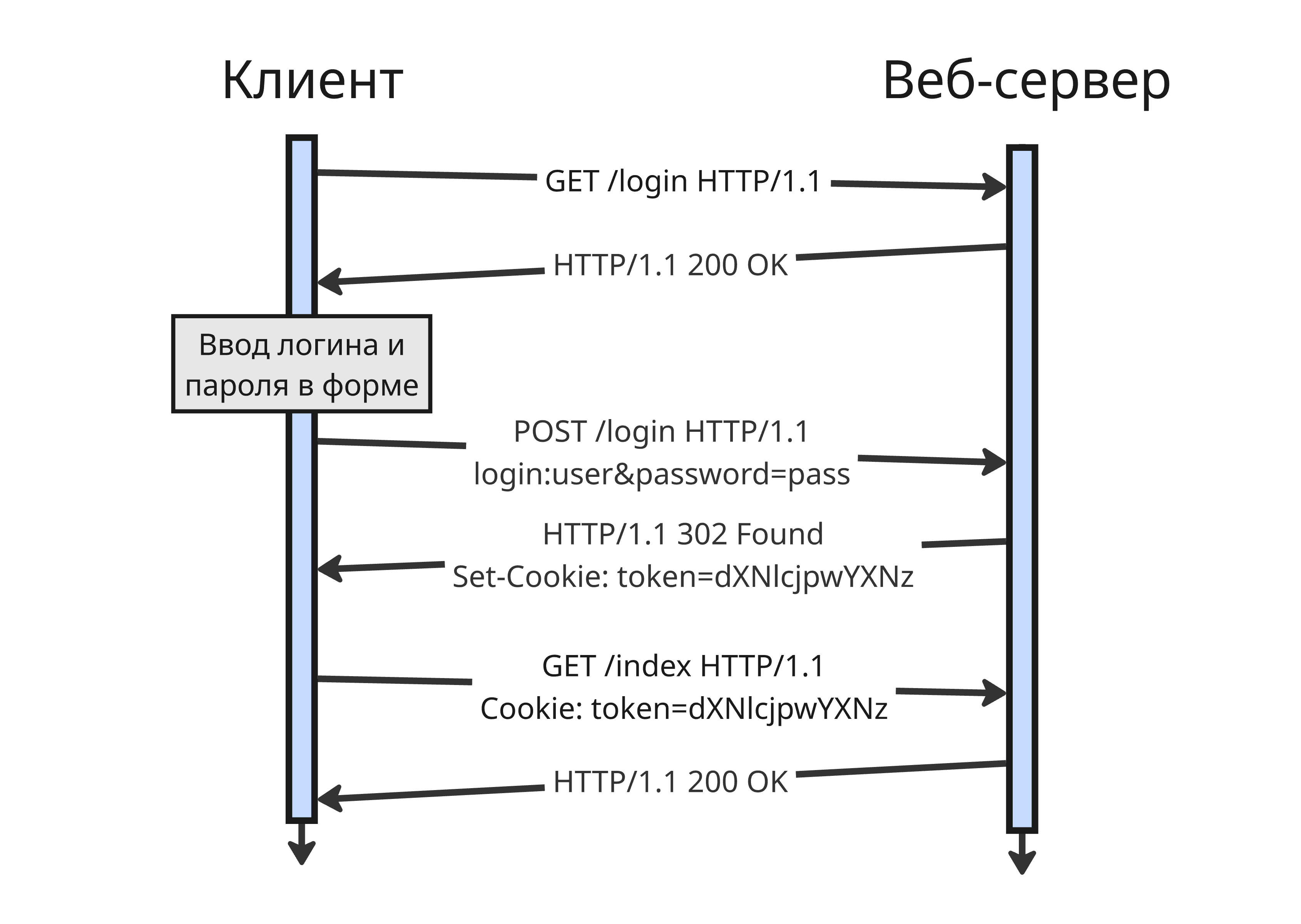
Токен сессии создается двумя способами:
- Как идентификатор сессии, которая хранится в памяти сервера и в базе данных. Сервер содержит всю информацию о сессии (такую, как браузер, устройство, пользователь), а клиент знает только идентификатор
-
Как зашифрованный объект, содержащий данные о пользователе
Такой подход позволяет реализовать stateless-архитектуру сервера (без хранения состояний), однако требует механизма обновления токена по истечении срока действия
Аутентификация по сертификату
Вместо пароля, который задается пользователем и зачастую бывает слишком легким к тому, чтобы его подобрать, можно использовать сертификат. Работает это так:
- Есть центр сертификации (Certificate Authority, CA) - доверенный сервер, который выдает сертификаты. У него есть два ключа - публичный и приватный
-
Клиент (и опционально сервер) имеет свои публичный и приватный ключи
Клиент (или сервер) запрашивает свой сертификат у центра сертификации - для этого создается запрос подписи сертификата (Certificate Signing Request, CSR). Этот запрос подписи подписывается приватным ключом клиента (или сервера): от всего запроса берется хеш, который шифруется с помощью приватного ключа
Центр сертификации, зная публичный ключ клиента, переданный в запросе, может расшифровать хеш и сопоставить с тем, что получился из всего сертификата, чтобы проверить, что клиент является владельцем ключей
- Далее центр сертификации проверяет, является ли клиент (или сервер) владельцем тем, кто указан в запросе. После этого составляется сертификат с уникальным номером, который подписывается приватным ключом центра сертификации
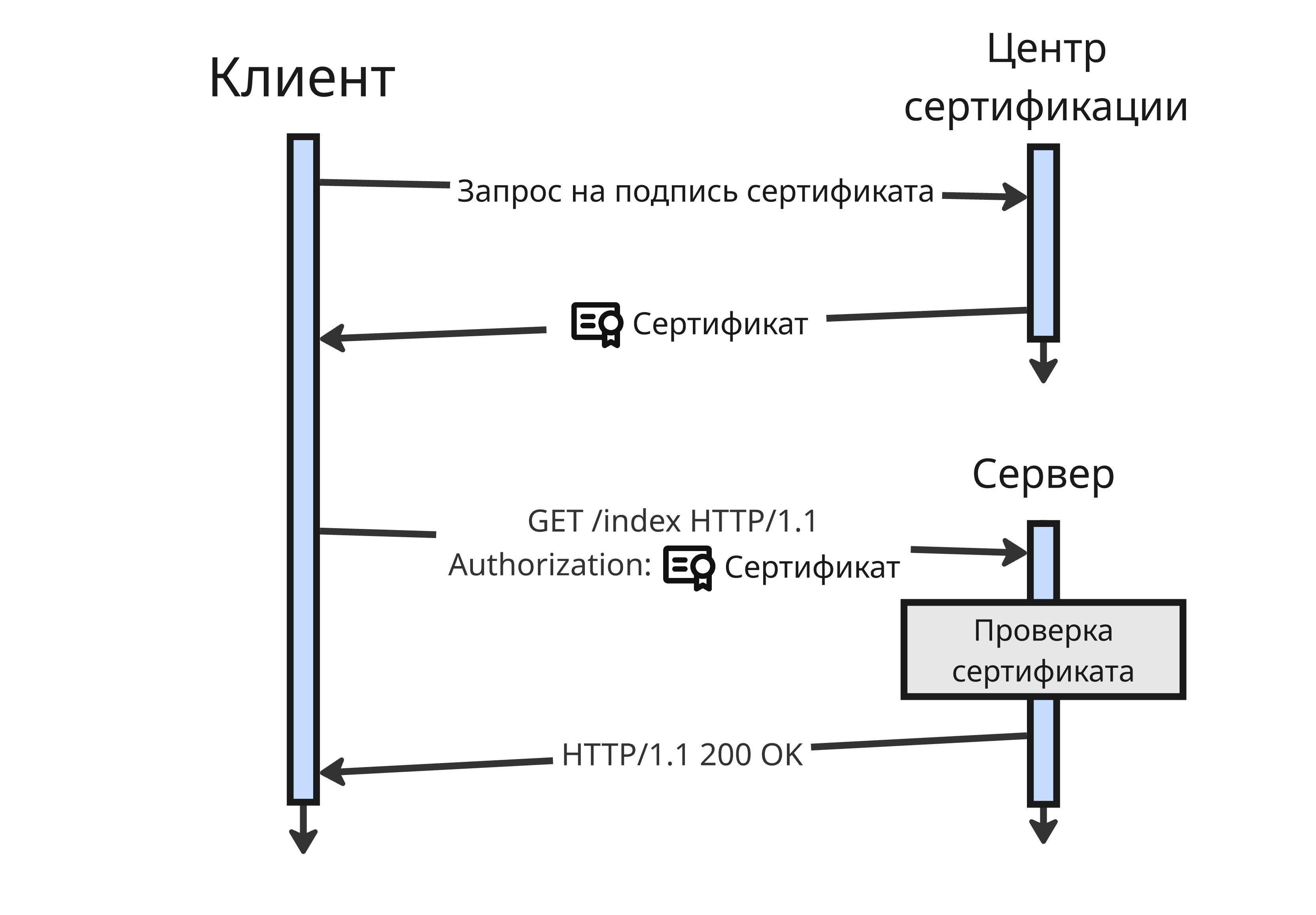
По стандарту X.509 сертификат содержит:
- Данные владельца (Subject) - информация о том, кому принадлежит сертификат, чаще всего это доменное имя сайта или имя пользователя
- Публичный ключ владельца (Subject Public Key Info)
- Информация о центре сертификации (Issuer)
- Срок действия (Validity) - период, в течение которого сертификат считается действительным
- Серийный номер (Serial Number) - уникальный идентификатор, присвоенный сертификату его издателем
- Цифровая подпись центра (Signature) - зашифрованный приватным ключом хеш сертификата
-
Расширения (Extensions) - важные дополнительные параметры, которые определяют, для чего можно использовать данный сертификат. Например:
- Альтернативные доменные имена (Subject Alternative Name, SAN), например,
docs.example.com - Операции использования (Key Usage), в которых можно использовать ключ сертификата
- Альтернативные доменные имена (Subject Alternative Name, SAN), например,
Приватные ключи клиента и центра сертификации остаются на соответствующих устройствах (например, на компьютере или специальной USB-флешке) и не сообщаются никому, тогда как публичные свободно передаются
У такого подхода есть недостатки:
- Компрометация приватного ключа - если злоумышленник получит приватный ключ, то он сможет подделать личность
- Компрометация центра сертификации - если злоумышленник имеет контроль над центром, он может выпускать поддельные сертификаты
- Уязвимости в реализации
Проверка по сертификату используется в протоколе TLS (Transport Layer Security), который основан на устаревшем протоколе SSL (Secure Sockets Layer) и на основе которого работает HTTPS (HTTP Secure):
- Сервер при первом запросе отправляет свой сертификат, подписанный одним из центром сертификации, клиенту
-
Клиент, зная публичные ключи центров, должен проверить, является ли сервер подлинным владельцем сертификата путем проверки:
- ключа центра сертификации
- действительности даты
- и включения в список недействительных сертификатов (если те были отозваны до срока действия)
Аналогично работает mTLS (Mutual TLS) - клиент и сервер обмениваются своими сертификатами, проверив которые, они могут убедиться, что за клиентом стоит подлинный владелец, а сервер не выдает себя за злоумышленника
Аутентификация по одноразовому паролю
Вместе с аутентификацией по паролю для большей безопасности применяют аутентификацию по одноразовому паролю. При таком подходе в случае ввода правильного пароля приложение попросит пользователя ввести одноразовый пароль
Такой пароль может быть создан:
- Аппаратно или программно на основе секретного ключа или на основе времени. Такой способ применяется в приложениях наподобие Google Authenticator, которые раз в 30 секунд генерируют одноразовые 6-значные пароли для аутентификации
- Случайно генерируемые сервером пароли, например, те, что приходят по SMS или электронной почте. Здесь фактор аутентификации - это проверка владения телефоном или почтой
- Пароли, напечатанные на бумаге или скретч-карте, которой владеет пользователь
Одноразовые пароли обычно используются для подтверждения важных операций
Аутентификация по ключу доступа
Для API применяют другой подход: вместо логин и пароля ключ доступа (или API-ключ), который является длинной уникальной строкой и по сути заменяет логин и пароль
При идентификации сервер генерирует такой ключ пользователю, который дальше сохраняет его и пользуется им для доступа к сервису. Сервер же может ввести статистику операций, которые производил пользователь с этим ключом (например, для выставления лимита запросов)
Такой ключ:
- позволяет не передавать пароль сторонним сервисам для доступа к основному
- генерируется рандомно, что увеличивает энтропию ключа и делает подбор невозможным
- при утечке может быть аннулирован, и в последствии выпущен новый
Такой ключ может быть передан в URL-запросе, HTTP-заголовке или в теле запроса и обязательно в безопасном соединении через HTTPS
Для небезопасных соединений ключ состоит из двух частей: приватная и публичная. При запросе сервер отправляет уникальное число nonce (или можно использовать временную метку), которую клиент подписывает своим приватным ключом. Сервер с помощью публичного ключа может проверить подлинность клиента
Аутентификация по токену
В другом подходе применяются токены. Приложение может делегировать аутентификацию другому приложению, а пользователя попросить войти в изначальное приложение через другое (так работает аутентификация через Google и другие сервисы)
Приложение, которое предоставляет аутентификацию (так называемый поставщик идентификации, Identity Provider), предоставляет достоверные сведения о пользователе в виде токена, а стороннее приложение использует этот токен для аутентификации и авторизации. Пользователю, чтобы войти в стороннее приложение, нужно пройти аутентификацию в поставщике идентификации, который генерирует токен для стороннего приложения
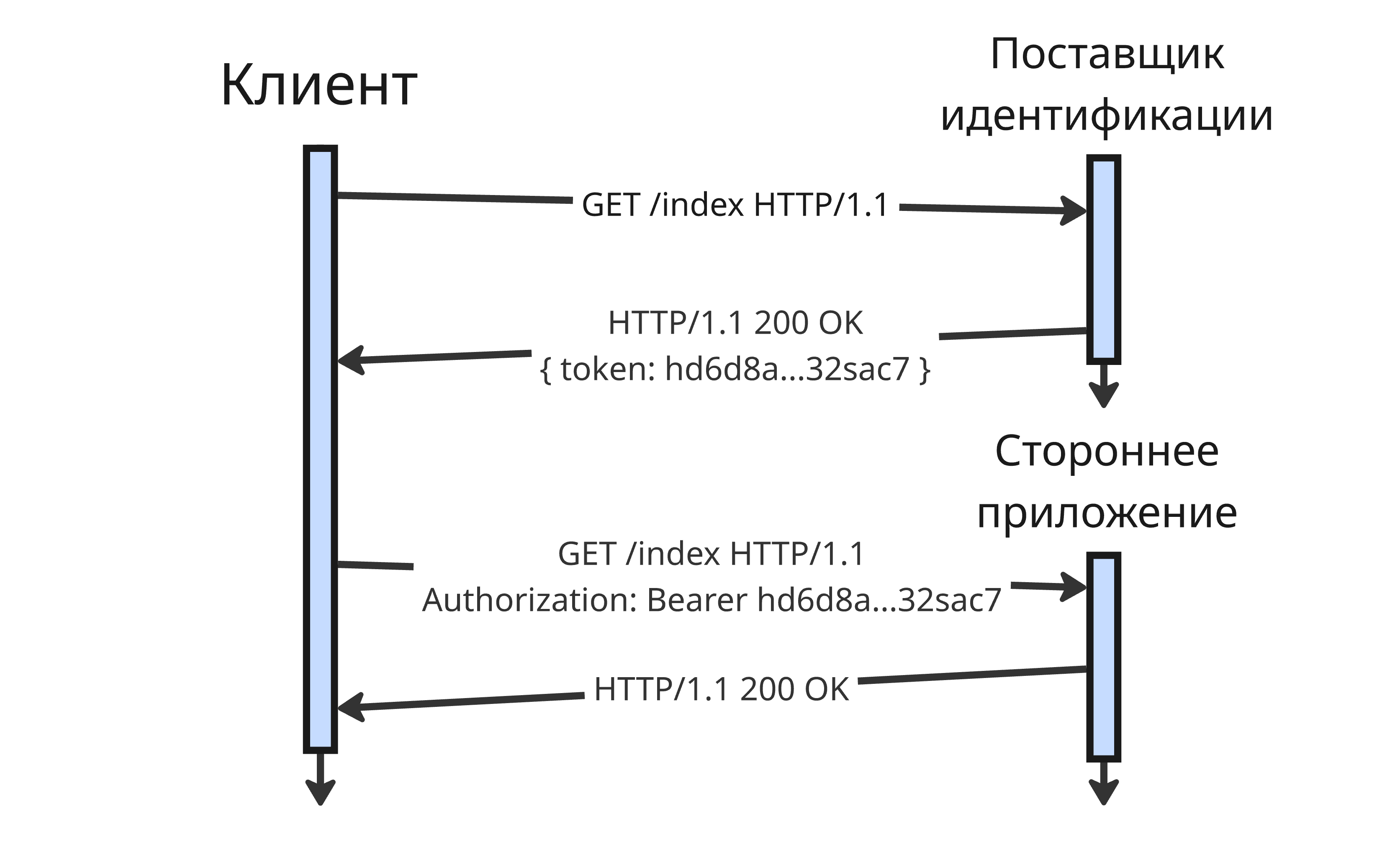
В браузере же веб-приложения способны перенаправлять на сайт поставщика и обратно на сайт стороннего приложения
Сам токен содержит информацию о том, кто его сгенерировал, кто получатель, срок действия и так далее, а также подпись токена. При аутентификации проверяется, что токен выдан доверенным поставщиком идентификации, токен предназначен этому приложению, срок токена еще не истек, а подпись действительна
Есть несколько форматов токена:
-
Simple Web Token (SWT) - формат, состоящий из последовательных пар ключ-значение. Выглядит SWT так:
Issuer=http://auth.myservice.com& Audience=http://myservice.com& ExpiresOn=1435937883& UserName=John Smith& UserRole=Admin& HMACSHA256=KOUQRPSpy64rvT2KnYyQKtFFXUIggnesSpE7ADA4o9w -
JSON Web Token (JWT) - формат, состоящий из трех блоков: заголовка, набора полей и подпись. Заголовок и набор полей представляются в виде JSON, закодированного в кодировке Base64. Набор полей определяет, кто выдал токен, кому и для чего
Выглядит JWT так:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWUsImlhdCI6MTUxNjIzOTAyMn0.KMUFsIDTnFmyG3nMiGM6H9FNFUROf3wh7SmqJp-QV30Блоки разделены между собой точками. При декодировке получается заголовок:
{ "alg": "HS256", "typ": "JWT" }Набор полей:
{ "sub": "1234567890", "name": "John Doe", "admin": true, "iat": 1516239022 }И подпись:
a-string-secret-at-least-256-bits-long -
Security Assertion Markup Language (SAML) определяет токены (так называемые SAML assertions) в формате XML, включающем информацию о токене и набор дополнительных утверждений о пользователе
В отличие от предыдущих форматов, SAML-токены содержат механизм для подтверждения владения токеном, что позволяет предотвратить перехват токенов через атаку “человек по середине” при использовании незащищенных соединений
Разберем стандарты, определяющие аутентификацию по токену, взаимодействие между приложения и протоколы:
-
SAML (Security Assertion Markup Language)
Этот стандарт поддерживает много различных сценариев интеграции систем. Он основан на:
- Собственной формате токенов - SAML Assertions
- Наборе поддерживаемых сообщений между участниками (протоколы)
- Механизмах передачи сообщений через различные транспортные протоколы
- Сценариях использования стандарта (профилях), которые определяют набор формата токенов, протоколов и механизмы передачи. Один из таких сценариев - Web Browser SSO
-
WS-Trust и WS-Federation (от Web services - Security)
Эти стандарты разрабатываются группой компаний Microsoft, IDM, VeriSign и используются преимущественно в корпоративных сценариях
Стандарт WS-Trust описывает интерфейс сервиса авторизации - он работает по протоколу SOAP и поддерживает создание, обновление и аннулирование токенов. При этом стандарт допускает использование токенов различного формата (обычно используется SAML Assertions)
Стандарт WS-Federation касается механизмов взаимодействия сервисов между компаниями, в частности, протоколов обмена токенов. Среди прочего, стандарт WS-Federation определяет формат и способы обмена метаданными о сервисах, функцию единого выхода из всех систем и другое
-
OAuth 2.0 и OpenID Connect
Стандарт OAuth (Open Authorization) определяет механизм получения доступа одного приложения к другому от имени пользователя
Первая версия стандарта разрабатывалась в 2007-2010 годах. Версия 2.0 была опубликована в 2012 году как расширение и упрощение
Процесс аутентификации состоит из нескольких шагов:
- Пользователь (владелец ресурса) дает разрешение приложению на доступ к определенному ресурсу в виде гранта
- Приложение обращается к серверу авторизации и получает токен доступа к ресурсу в обмен на свой грант. При вызове приложение дополнительно аутентифицируется при помощи ключа доступа
- Приложение использует этот токен для получения требуемых данных от сервера ресурсов (например, Google)
Стандарт описывает четыре вида грантов, которые определяют возможные сценарии применения:
-
Код авторизации (Authorization Code) - этот грант пользователь может получить от сервера авторизации после успешной аутентификации и подтверждения согласия на предоставление доступа. Такой способ наиболее часто используется в веб-приложениях
-
Неявный сценарий (Implicit) применяется, когда у приложения нет возможности безопасно получить токен от сервера авторизации (например, JavaScript-приложение в браузере) - в этом случае грант представляет собой токен, полученный от сервера авторизации, без обмена кода авторизации на сам токен. Его использование не рекомендуется
-
Учетные данные паролей владельца ресурса (Resource Owner Password Credentials) - такой грант представляет собой логин и пароль пользователя. Может применяться, если приложение является интерфейсом для сервера ресурсов
-
Учетные данные клиента (Client Credentials) - в этом случае нет никакого пользователя; само приложение собирается получить доступ к своим ресурсам при помощи своих ключей доступа
Стандарт не определяет формат токена, который получает приложение, поэтому ни токен, ни грант сами по себе не могут быть использованы для аутентификации пользователя
Однако если приложению необходимо получить достоверную информацию о пользователе, существуют несколько способов это сделать. Зачастую API сервера ресурсов включает операцию, предоставляющую информацию о самом пользователе (например, эндпоинт
/me). Приложение может выполнять эту операцию каждый раз после получения токена для идентификации клиента - такой метод иногда называют псевдоаутентификациейВместо псевдоаутентификации можно использовать стандарт OpenID Connect, разработанный как слой идентификации поверх OAuth. В соответствии с ним, сервер авторизации предоставляет дополнительный токен идентификации в формате JWT, который содержит набор полей с информацией о пользователе
Лекция 8. Подписочная модель обмена сообщениями
Протокол HTTP устроен так, что взаимодействие между сервером и клиентом инициируется клиентом. Зачастую сервер ничего не знает о том, как подключиться к клиенту
Поэтому есть несколько способов передавать сообщения с сервера клиенту
Частые опросы
Частые опросы (или поллинг, Periodic polling) - самый простой способ
Работает так: надо сказать клиенту, чтобы он отправлял запрос на получение новых сообщений с сервера, например, каждые 10 секунд. В ответ сервер понимает, что клиент находится в сети, и отправляет все уведомления, которые у него накопились на этот момент
У такого подхода есть недостатки:
- Сообщения передаются с задержкой, равной периоду опроса
- Это не очень производительно: если сообщений нет продолжительное время, сервер обязан отвечать на опросы клиента, из-за чего такой метод плохо работает при большом числе клиентов
Длинный опрос
Длинный опрос (Long polling) - простой способ поддерживать соединение с сервером, не используя другие протоколы. Работает это так:
- Клиент отправляет запрос на сервер
- Сервер, не закрывая сетевое соединение, ждет, пока появится сообщение клиенту
- Когда появляется, сервер отсылает его и закрывает соединение
- Клиент отправляет новый запрос
Если соединение в каком-либо случае потеряно (например, при переключении Wi-Fi), то браузер пытается заново открыть соединение с сервером
Клиентский код для длинного опроса может выглядеть так:
async function subscribe() {
const response = await fetch("/subscribe");
if (response.status in [502, 504]) {
// Таймаут соединения
await subscribe();
} else if (response.status != 200) {
// Неправильный код ошибки
console.log(response.statusText);
await new Promise(resolve => setTimeout(resolve, 1000));
await subscribe();
} else {
// Успешная передача
const data = await response.json();
console.log(data);
await subscribe();
}
}
Такой подход хорошо работает, когда сообщения приходят редко
Однако реализация сетевой библиотеки должна поддерживать работу со многими ожидающими подключениями. Например, Node.js не создает поток для каждого нового соединения, что позволяет выделять меньше памяти и не создавать блокирующие потоки для ожидания данных. Это возможно благодаря кроссплатформенной библиотеке LibUV, написанной на C, для работы с сеть
WebSocket
WebSocket (или WS сокращенно) - протокол для совершения постоянного взаимодействия между сервером и клиентом
Протокол WebSocket особенно полезен для сервисов, которые ведут постоянное общение с клиентом, например, игры, торговые площадки и другие
Чтобы создать подключение, нужно
let socket = new WebSocket("wss://example.com")
Здесь протокол wss - это безопасное соединение (от WebSocket Secure) с использованием TLS. Аналогично ws - это протокол без TLS
Далее такой сокет генерирует 4 события:
-
open- открытие соединенияsocket.onopen = function(e) { console.log("Соединение открыто"); socket.send("Hello"); } -
message- прием нового сообщенияsocket.onmessage = function(e) { console.log(e.data); } -
errorsocket.onerror = function(e) { console.log("Ошибка: ", e.message); } -
close- закрытие соединенияsocket.onmessage = function(e) { if (e.wasClean) { console.log("Соединение успешно закрыто"); } else { console.log("Соединение прервано"); } }
Через сокет сообщения можно посылать через метод send
Само соединение устанавливается с помощью протокола HTTP. Клиент отправляет HTTP-запрос с заголовками Connection: Upgrade и Upgrade: websocket, тем самым спрашивая, может ли сервер перейти на общение по протоколу WebSocket. Если сервер поддерживает WebSocket, то он отправляет ответ со статусом 101 Switching Protocols. Такая процедура называется обновлением протокола
Поток данных в протоколе WebSocket состоит из фреймов - фрагментов данных, которые могут быть отправлены любой стороной. Фреймы могут быть:
- текстовыми
- бинарными
- “пинг-понг фреймами”, использующимися для проверки соединения
- фреймами закрытия соединения и другие служебные фреймы
Сам по себе WebSocket не описывает функционал переподключения, аутентификацию и другое, но зато это реализуют библиотеки, например, Socket.IO
Socket.IO - библиотека JavaScript, использующая веб-сокеты или другие технологии (например, Flash Socket), если веб-сокеты не доступны
Также, в отличие от веб-сокетов Socket.IO:
- позволяет отправлять сообщения всем подключенным клиентам
- поддерживает проксирование и балансировщики нагрузки
- поддерживает автоматическое переподключение
Лекция 9. Сборщики
Сборщик (или бандлер, bundler) - это инструмент, который берёт множество файлов проекта (JavaScript-модули, CSS, изображения, шрифты) вместе с внешними зависимостями и объединяет их в один или несколько оптимизированных файлов для отправки клиенту в браузер
Сборщик обладает преимуществами перед обычной отправкой файлов:
- Производительность загрузки - современные приложения состоят из сотен и тысяч модулей, поэтому загружать каждый файл отдельным HTTP-запросом крайне неэффективно; бандлер собирает всё в несколько компактных файлов, сокращая число запросов и ускоряя загрузку страницы
- Совместимость с браузерами - сборщики умеют преобразовывать современный синтаксис (ES6+, TypeScript, JSX) в код, понятный старым браузерам, используя транспиляторы
- Оптимизация кода - а именно минификация, удаление неиспользуемого кода (tree-shaking), разделение кода на чанки, загружаемые по требованию (code-splitting)
- Удобство разработки - горячая замена модулей (Hot Module Reload), сервер для разработки с мгновенным обновлением, поддержка CSS-препроцессоров и других преобразований
Сборщик работает примерно так:
- Разработчик указывает главный файл (например,
index.js) - Бандлер анализирует все
importи строит полное дерево зависимостей модулей - К каждому файлу применяются необходимые трансформации (транспиляция из TypeScript в JavaScript, компиляция SCSS в CSS и тому подобное)
- Все модули объединяются в итоговый бандл (один или несколько файлов)
- Готовые статические файлы сохраняются на сервере, откуда они готовы к отправке клиенту
Рассмотрим несколько популярных сборщиков
Webpack
Webpack - самый популярный и давно существующий сборщик модулей для JavaScript-приложений. Несмотря на появление более быстрых конкурентов, в 2026 году Webpack остаётся стабильным, хорошо поддерживаемым и широко используемым инструментом, особенно в крупных корпоративных проектах
Ключевые особенности:
- Мощная система плагинов и загрузчиков - Webpack даёт полный контроль над процессом сборки, позволяя настроить практически любую кастомную обработку ассетов
- Экосистема - существуют тысячи плагинов, проверенных годами, для самых разных задач
- Стабильность и нейтральность - поддерживается фондом OpenJS Foundation, что гарантирует независимость от интересов отдельных коммерческих компаний
Webpack опубликовал дорожную карту, сфокусированную на трёх направлениях:
- Нативная поддержка CSS Modules - возможность работать с CSS без плагинов
- Универсальная цель сборки - код будет компилироваться в чистый ESM (ECMAScript Modules), работающий в любых средах (Node.js или браузер) без привязки к конкретной среде испольнения
- Встроенная поддержка TypeScript - транспиляция TS без плагина
ts-loader, а также разрешение путей изtsconfigуже без плагинаtsconfig-paths-webpack-plugin - Нативные HTML-входные точки - импорт HTML-файлов как точек входа без плагина
html-webpack-plugin - Улучшения производительности - исследование многопоточного API для задействования многоядерных процессоров
Webpack остаётся выбором для проектов, где требуется максимально тонкая и нестандартная настройка сборки, сложное разделение кода или где уже существует большая кодовая база и экосистема плагинов, которую сложно заменить
Vite
Vite - современный инструмент для фронтенд-разработки, созданный Эваном Ю (автором Vue.js). С момента появления Vite стремительно набрал популярность благодаря молниеносной скорости запуска сервера для разработки и горячей замены модулей
До версии 8 Vite использовал два разных сборщика: esbuild (для быстрой компиляции в режиме разработки) и Rollup (для продакшн-сборки). Такой подход имел минус: два конвейера обработки порождали расхождения и требовали синхронизации
В Vite 8 оба конвейера заменены на единый бандлер Rolldown, созданный командой VoidZero на языке Rust
Ключевые преимущества Vite 8:
- Скорость сборки до 10–30 раз выше по сравнению с Rollup. Реальные проекты показывают сокращение времени сборки с 46 до 6 секунд
- Единая система плагинов - полная совместимость с плагинами Rollup и Vite; большинство существующих плагинов работают без изменений
- Встроенные инструменты разработчика, такие как отладка и профилирование
- Улучшенная поддержка TypeScript
- Улучшенный серверный рендеринг и поддержка Wasm (Web Assembly)
Параллельно с Vite 8 команда VoidZero анонсировала Vite+ - унифицированную платформу, объединяющую сборку, пакетный менеджер и среду разработки в единую экосистему на базе инструментов, написанных на Rust
Vite - идеальный выбор для новых проектов, где важна скорость запуска и мгновенная обратная связь при разработке. Особенно хорошо подходит для одностраничных приложений (Single-page application), приложений на Vue/React/Svelte и любых задач, где не требуется глубокая кастомизация сборочного процесса
Rsbuild
Rsbuild - это слой поверх Rspack (Rust-реализации, совместимой с Webpack), созданный командой ByteDance. Его цель - предоставить максимально быструю сборку при сохранении совместимости с экосистемой Webpack
- Rsbuild работает поверх Rspack - Rust-бандлера, который реализует API, совместимый с Webpack, но при этом значительно (в 5–10 раз) быстрее его из-за использования Rust
- Нулевая или минимальная конфигурация - Rsbuild сокращает объём конфигурации примерно на 90% по сравнению с Webpack, автоматически применяя лучшие практики
- Фреймворк-независимость - через плагины поддерживает React, Vue, Svelte, Solid и другие UI-библиотеки
Ключевые нововведения:
- Основной пакет распространяется только как ES-модуль
- Поддержка Node.js 20 и современных браузеров
- Экспериментальная поддержка React Server Components (RSC) через плагин
rsbuild-plugin-rsc - Теперь возможна отправка целевых сообщений из серверного процесса клиенту без полной перезагрузки страницы
- Новая модель разделения кода через гибкие стратегии разделения чанков (включая выделение каждого npm-пакета в отдельный чанк)
Rsbuild особенно привлекателен для команд, которые хотят мигрировать с Webpack и получить прирост скорости на порядок, но при этом сохранить привычную экосистему плагинов и не переписывать конфигурацию с нуля.
Module Federation
Module Federation - это архитектурный паттерн и технология (изначально представленная в Webpack 5), позволяющая одному JavaScript-приложению динамически загружать код из другого приложения прямо во время выполнения. В отличие от обычного импорта пакета, это обмен компонентами, логикой и ресурсами между независимо развёртываемыми проектами
Цели, которые преследовали разработчики:
- Независимое развёртывание - разные команды могут разрабатывать и развертывать свои микрофронтенды автономно
- Разделение ответственности - каждый микрофронтенд соответствует предметной области и обслуживается отдельной командой
- Общие зависимости - Module Federation умеет дедуплицировать общие библиотеки, чтобы они загружались однократно
Версия Module Federation 2.0 стала результатом переработки внутренней архитектуры командой ByteDance в сотрудничестве с Заком Джексоном (автором оригинальной технологии)
Ключевые новшества:
- Отвязка от Webpack - среда исполнения Module Federation теперь полностью независима от инструмента сборки, что позволяет работать с Webpack, Rspack, Rolldown, Vite и так далее
- Динамические подсказки типов - автоматическая генерация и загрузка типов удалённых TypeScript-модулей, что убирает проблему с
anyи необходимость в отдельных общих пакетах - Манифест (
mf-manifest.json) - структурированное описание экспортов и зависимостей приложения, упрощающее развертывание и управление версиями - Federation Runtime и система плагинов - возможность программного управления загрузкой модулей и встраивания своей логики
- Side Effect Scanner - инструмент, который анализирует сборку и выявляет потенциальные побочные эффекты (глобальные переменные, подписки на события) перед интеграцией модуля
- Chrome DevExtension - визуализация графа зависимостей и загруженных версий библиотек прямо в браузере
На 2026 год Module Federation 2.0 активно используется в экосистеме ByteDance и за её пределами. Для Next.js официальной поддержки пока нет (рекомендуемый фреймворк - Modern.js от той же команды). В планах у разработчиков создание Module Federation 3.0 и Native ESM Federation
Подытожим:
| Инструмент | Сильные стороны | Лучше всего подходит для | |-|-|-| | Webpack | Максимальная гибкость, зрелая экосистема, нейтральное управление | Крупные сложные проекты с нестандартными требованиями | | Vite 8 | Мгновенный старт сервера для разработки, высочайшая скорость сборки | Новые одностраничные приложения, быстрая разработка, Vue/React/Svelte-проекты | | Rsbuild 2.0 | Совместимость с Webpack, но со скоростью языка Rust🦀, минимум конфигурации | Миграция с Webpack, когда нужна скорость и привычный API | | Module Federation 2.0 | Динамическая загрузка кода между приложениями во времени исполнения | Микрофронтенд-архитектуры, независимо развёртываемые команды |