itmo_conspects
Лекция 14. Файловая система
Основная проблема оперативной памяти - ее линейность. Сущности, которые мы хотим моделировать, представляют собой зачастую иерархическую структуру. Поэтому те методы, что мы использовали для оперативной памяти, нельзя применить для хранилищ - с машинными указателями человеку работать плохо, тогда как мы хотим работать с человекочитаемыми именами файлов
Сейчас распространено множество форматов постоянных запоминающих устройств:
-
HDD (Hard Drive Disk) - жесткий диск. Внутри него крутятся с огромной скоростью диски, на которых записаны данные, поэтому, чтобы к ним обратиться, нужно знать:
- номер пластины (и номер головки, если запись идет на две стороны диска)
- кольцевая дорожка на пластине (так называемый цилиндр)
- сектор на этом цилиндре
-
SSD (Solid State Disk) - твердотельный накопитель, использующий полупроводники. В SSD-диске память делится на блоки, которые делятся на странице
-
CD / DVD / Blu-ray диск, которые хранят данные на спиральной кривой, к которой можно обратиться линейно
-
RAID, NAS и другие хранилища
Связь между ОС и устройством образуется при помощи контроллера на устройстве и драйвера устройства на ОС. С помощью них к диску можно обращаться как к линейно адресуемому устройству
Первый слой абстракции - блочное устройство. В Linux блочные устройства представлены как /dev/sda, /dev/sdb и так далее. Блочные устройства разделены на блоки - единицы обмена данными между ОС и физическим устройством. Контроллер на диске и драйвер делают так, чтобы при обращении к блоку возвращались нужные данные, несмотря на физическую адресацию диска
Далее блочное устройство разделяется на разделы. При инициализации диска в начале блочного устройства есть специальные разделы:
- Master Boot Record (MBR) для загрузки операционной системы
- Partition Table - таблица, хранящая структуру разделов на диске
Раздел же представляется как набор блоков. Разделы именуются в формате /dev/sda1. На этом разделе создается файловая система
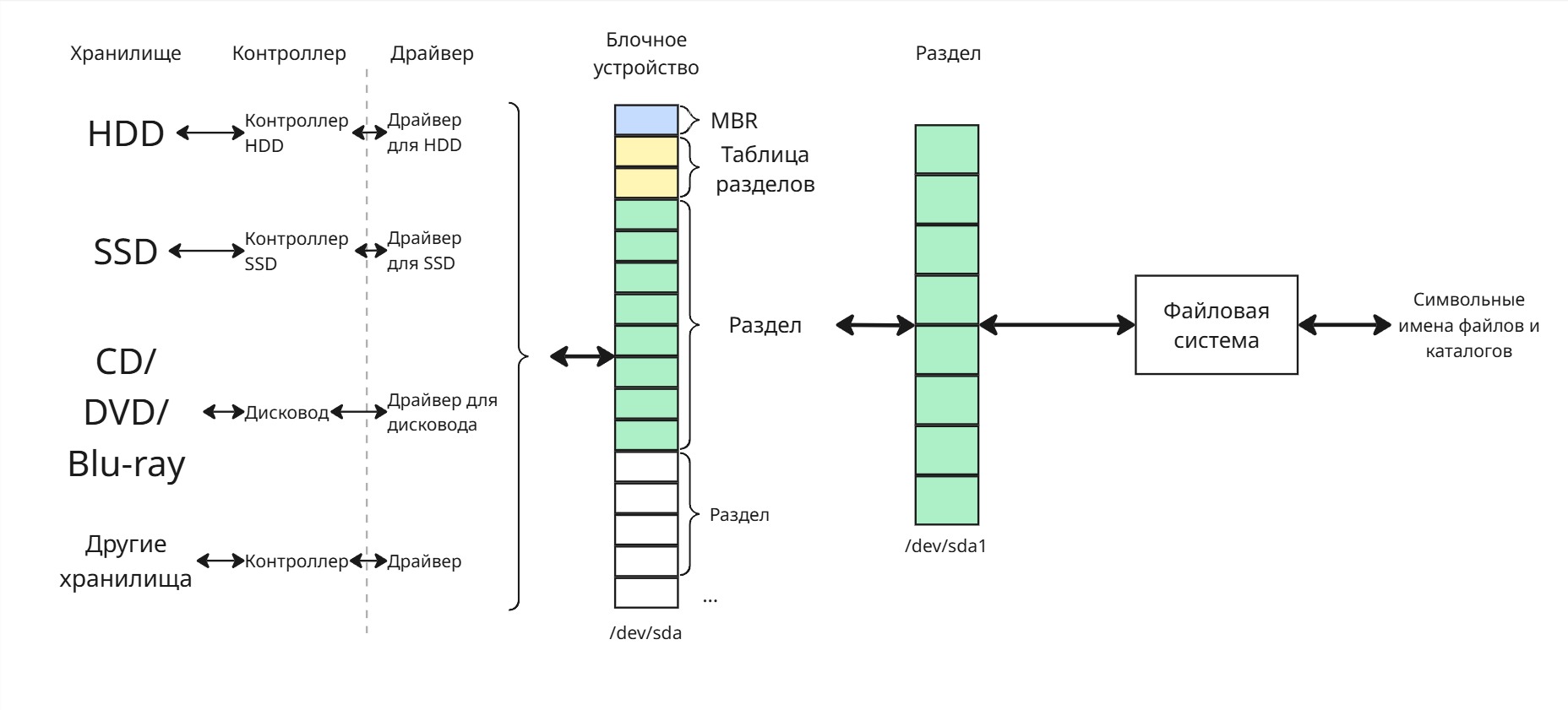
Задача файловой системы преобразовать символьные имена файлов типа /home/user/text.txt в адреса блоков, на которых данные расположены на блочном устройстве. В Linux также есть виртуальная файловая система, реализация которой может преобразовать символьное имя в какое-то действие
Как же сопоставить набор имен файлов с набором блоков?
-
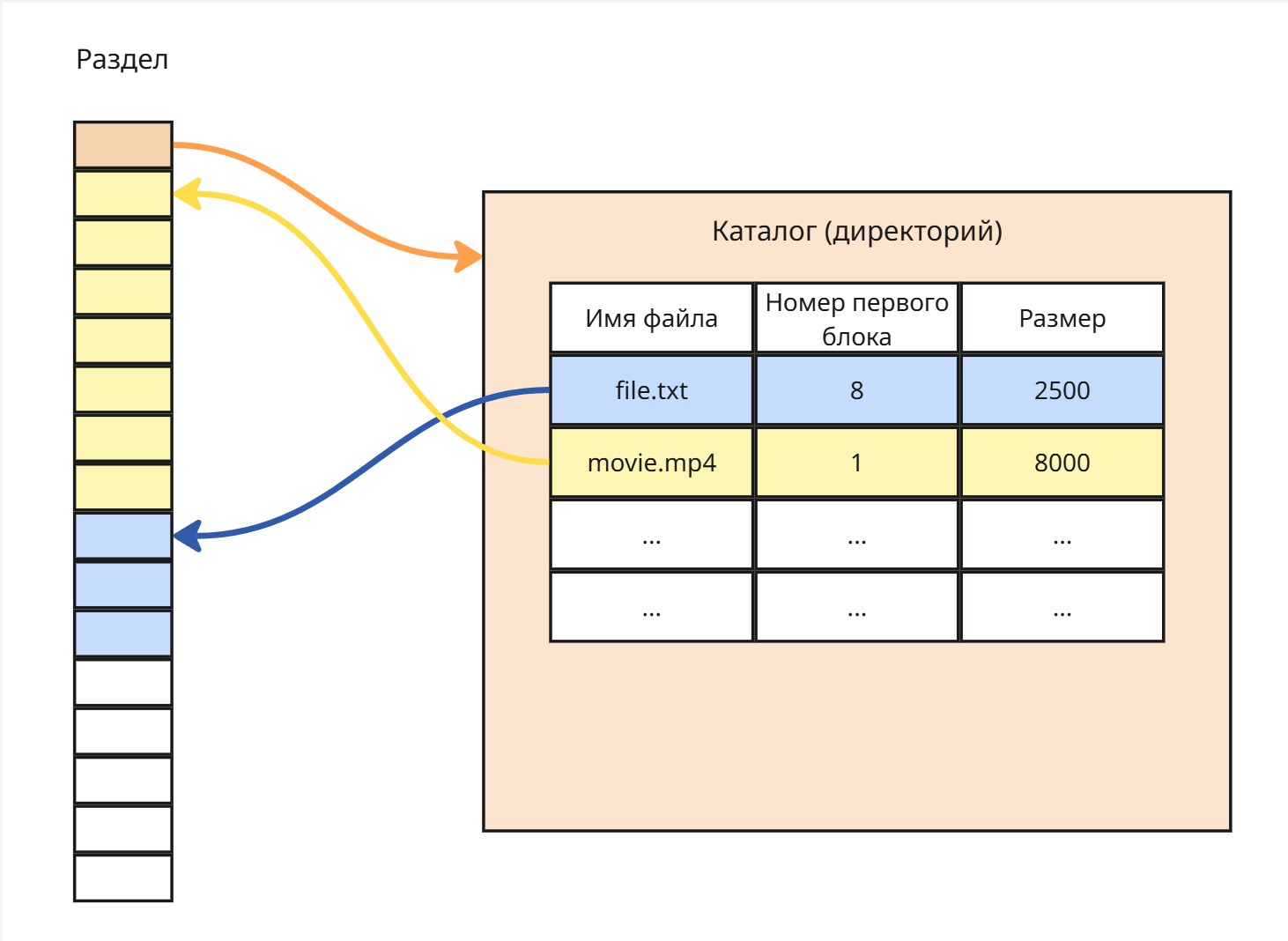
Непрерывная последовательность блоков
Пусть размер блока - 1024 байт, а файл весит 2500 байт. Тогда файл будет занимать 3 блока.
В этом случае мы можем сделать таблицу подобного вида:
Имя файла Номер первого блока Размер файла file.txt8 2500 Плюсы: это просто и быстро
Минусы: диск очень сильно подвержен фрагментации - явлению, когда после продолжительной работы суммарно место на диске есть, но непрерывного участка для хранения нового файла нет
Такая система используется в файловой системе компакт-дисков (CDFS). В конце записывается TOC (Table of Contents, таблица с содержанием). При удалении и добавлении новых файлов создается новый TOC в конце спирали. При первом чтении дисковод идет по спирали и ищет этот TOC. В случае, когда спираль кончается, то можно стереть все данные с диска и записать их непрерывно
-
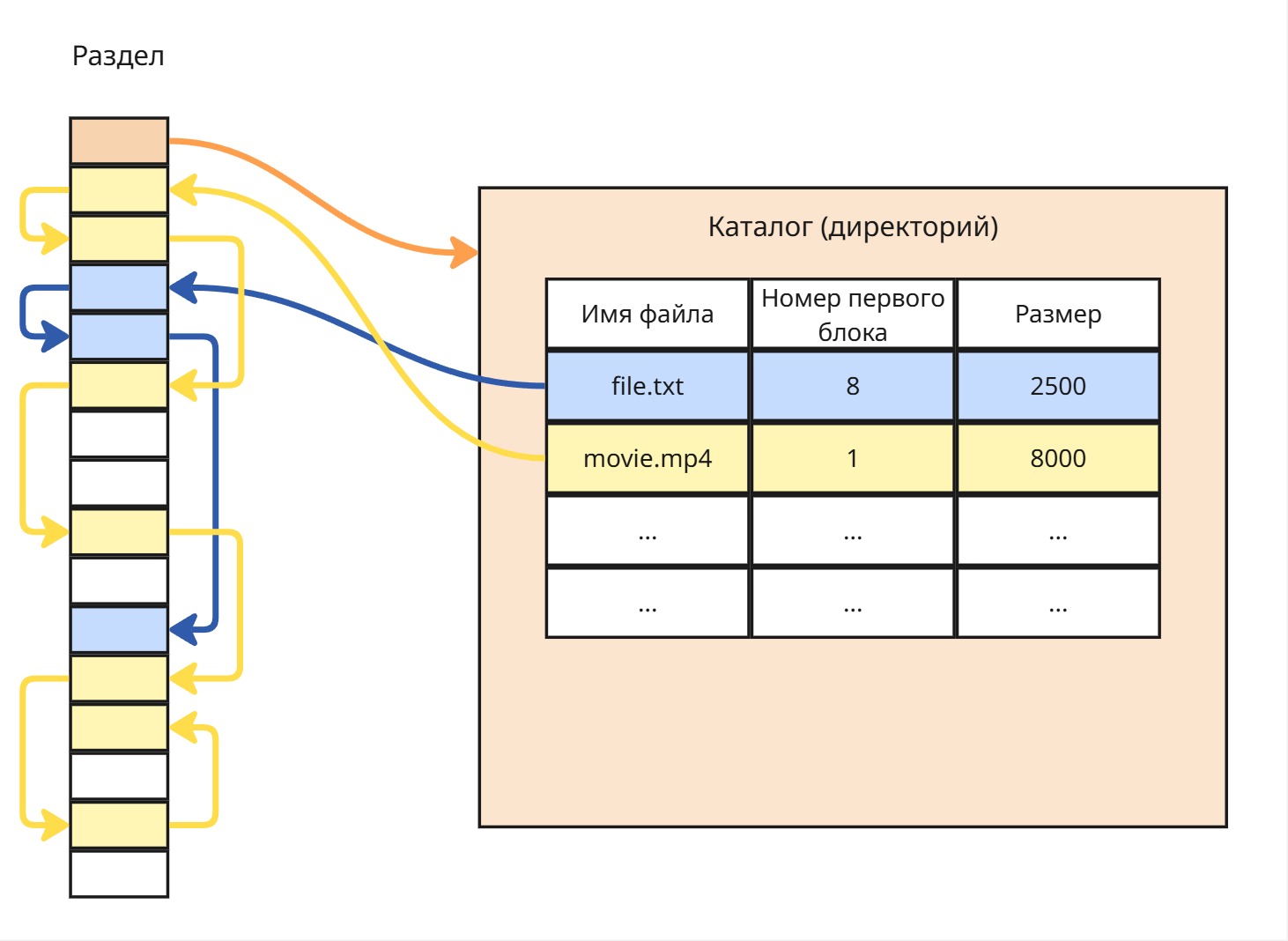
Связный список
Решим проблему с фрагментацией: будет хранить в конце блока ссылку на следующий блок. Таким образом, блоки могут располагать произвольно.
У такого подхода множество недостатков:
-
Размер блока становится некратным
2^k(либо 1020 для данных + 4 для указателя, либо 1024 для данных + 4 для указателя) -
Если потеряется какой-либо блок, то потеряются все последующие блоки
-
Только последовательное чтение - для перехода в случайный блок файла нужно прочитать все блоки перед ним
Однако такой подход используется: при создании файловой системы создается связный список для пустого пространства диска. В пустом пространстве такие недостатки не существенны, поэтому можно отслеживать, какие блоки свободны
-
-
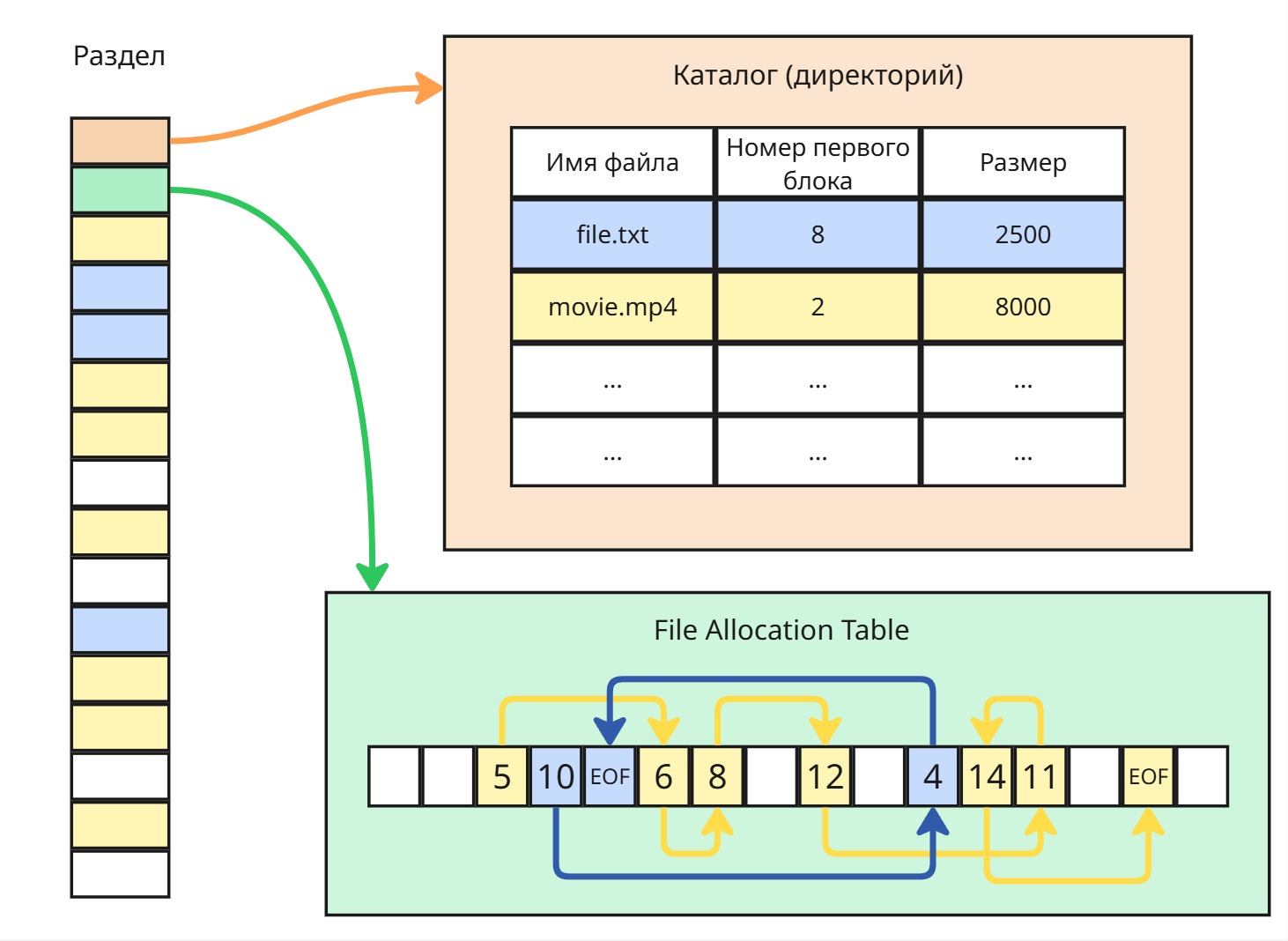
Таблица размещения файлов
Можно хранить этот связный список в отдельном месте в виде линейного массива:
|
NULL|NULL|5|10|EOF|6|8| … | |-|-|-|-|-|-|-|-|Здесь
NULL- это пустой блок, аEOF- конец файла. Таким образом, в блоках не хранятся указатели на следующие блокиПри создании файла в списке ищется максимальное количество подряд идущих пустых блоков
Такая таблица получается название File Allocation Table (FAT)
Преимущество: файловая система все еще очень примитивная
Недостатки:
- таблицы нужно держать в памяти
- если потеряется блок с таблицей, то данные потом никак не восстановить
Когда диски стали большими, то разделы стали разбивать на группы блоков, у каждой из которой есть свой FAT
Помимо этого можно делать несколько копий таблицы - если какая-то из них не совпадает с остальными, то алгоритм решает, какую таблицу считать валидной
-
Индексные дескрипторы
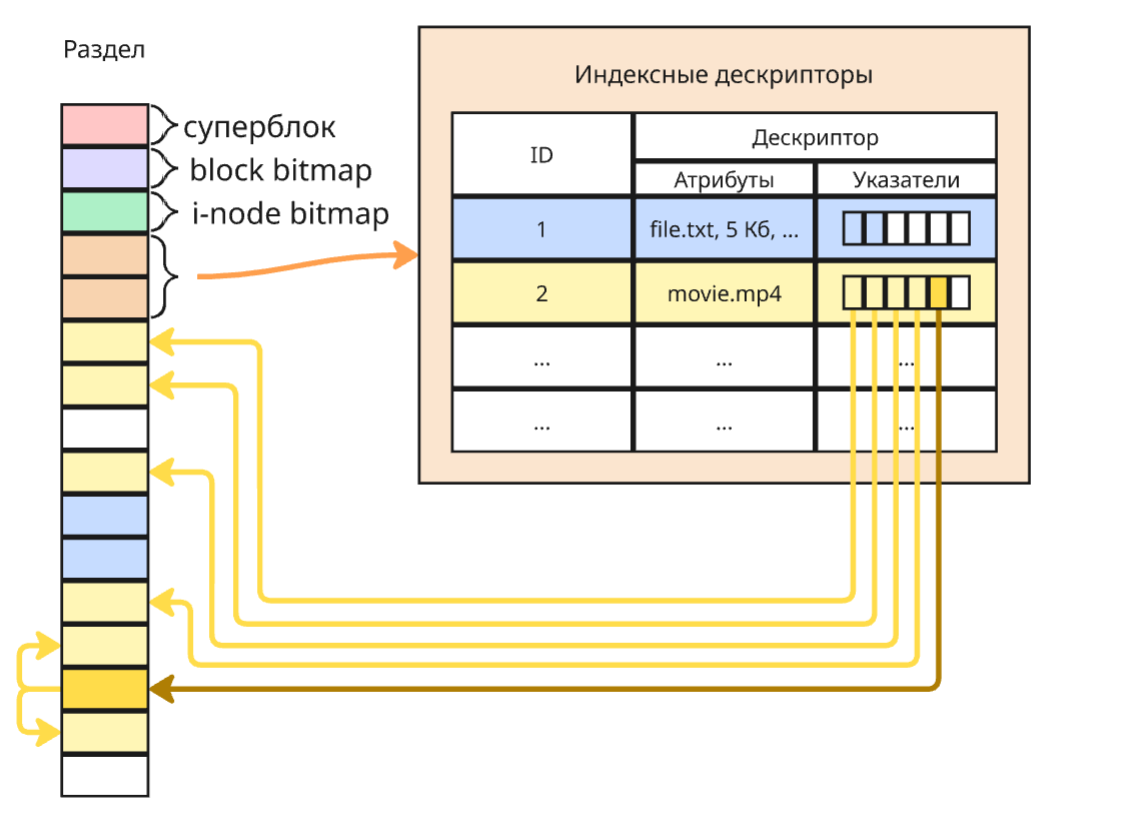
В таком подходе файл сопоставлен индексному дескриптору (i-node). Индексный дескриптор - структура, которая хранит атрибуты файла и блоки, на которых он расположен. Каталог же представляет собой файл, содержащий таблицу с именем файла в каталоге и соответствующий ему i-node
Рассмотрим индексные дескрипторы на примере файловой системы ext2 (от Extended File System). В ext2 при создании в начале раздела создаются специальные участки: суперблок, block bitmap, i-node bitmap и участок для хранения индексных дескрипторов
По умолчанию размер блока в ext2 - 4096 байт, а i-node в ext2 имеет размер в 128 байт, первая часть из которых - атрибуты файла, такие как его имя, дата создания, количество жестких ссылок. Вторая часть - это карта размещения, массив из 15 элементов.
Первые 12 элементов в массиве - номера блоков, на которых расположены файл. Если файл весит больше, чем
12 * 4096 = 48Кб, то для этого используется 13-ый элементНенулевой 13-ый элемент хранит в себе номер блока, в котором хранятся номера последующих блоков файла, то есть следующие
1024 * 4096 = 4Мб файла (так называемая косвенная адресация)Если файла весит больше, чем 4 Мб и 48 Кб, то ненулевой 14-ый элемент массива предоставляет двойную адресацию: повторяем заклинание два раза, получаем 1048 тысяч элементов и файл размером до 4 Гб
Аналогично ненулевой 15-ый элемент дает тройную косвенную адресацию и файл до 4 Тб
Свободные блоки помечаются в block bitmap (битовый массив), а свободные дескрипторы помечаются в i-nodes bitmap. Суперблок хранит статистическую информацию
В ext3 добавилось журналирование на уровне файловой системы. Доступно 3 уровня:
- Journal - самый медленный, но самый надежный журнал. Может быть на другом диске для большей надежности. Сначала в журнал пишутся блоки данных, потом они копируются в нужное место, и изменяется i-node
- Ordered - метаданные записываются в журнал до записи данных на диск, но сами данные на диск отправляются до подтверждения метаданных в дескрипторе
- Writeback - сначала пишем весь файл, а потом изменяем все метаданные в i-node и журнале
На основе ext3 была создана NTFS (New Technology File System), где i-node хранятся в файле, что решает проблему с ограниченностью участков, где хранятся i-node. В Windows этот файл называется
$MFT(Master File Table)Далее появилась ext4. Когда появились распределенные системы, стала важна точность до микросекунд. Когда файлы стали десятки гигабайт - то тройная косвенная адресация стала проблемой медленного доступа к данным.
ext4 должна была решить эти проблемы и не потерять совместимость с ext2. Поэтому в ext4 появился расширенный i-node, который весит 512 байт. В изначальных 128 байт хранятся младшие биты атрибутов, а в других 384 байтах опционально хранятся старшие биты и дополнительные данные
Кроме того, в ext4 ввели поддержку экстентов: в i-node могут вместо указателей на блоки храниться 4 экстента. Экстент хранит номер первого блока и количество блоков последовательно, что снижает дефрагментацию. Если файл весит больше, то экстент вместо блоков хранит указатель на другой экстент. Экстенты представляют собой дерево, которое балансируется для поддержки производительности
При этом есть оптимизация: в конце файла выделяется дополнительно немного места для небольших изменений в конце
Если количество файлов в каталоге чересчур большое, то поиск файла в каталоге может быть медленным (а он линейный). Тогда создается хеш-индекс файлов для каталога