itmo_conspects
Лекция 13. Методы выделения памяти
Существует множество методов выделения памяти процессу. Процесс же можно воспользоваться этой памятью благодаря адресам, указывающим на какой-то участок памяти. Сейчас принято в языках программирования по адресу возвращать байт, то есть 8 бит, данных - побайтовая адресация (Byte Addressing). Однако раньше это была адресация по слову (Word Addressing) - word, единица данных, выбранная для архитектуры системы; в те времена это было повсеместно 2 байта
Методы выделения памяти делятся на методы, не использующие подкачку, и методы, использующие ее
Подкачка (paging или swapping) - механизм использования жесткого диска для выгрузки нерелевантных данных из оперативной памяти в раздел подкачки (чаще всего находящийся на жестком диске)
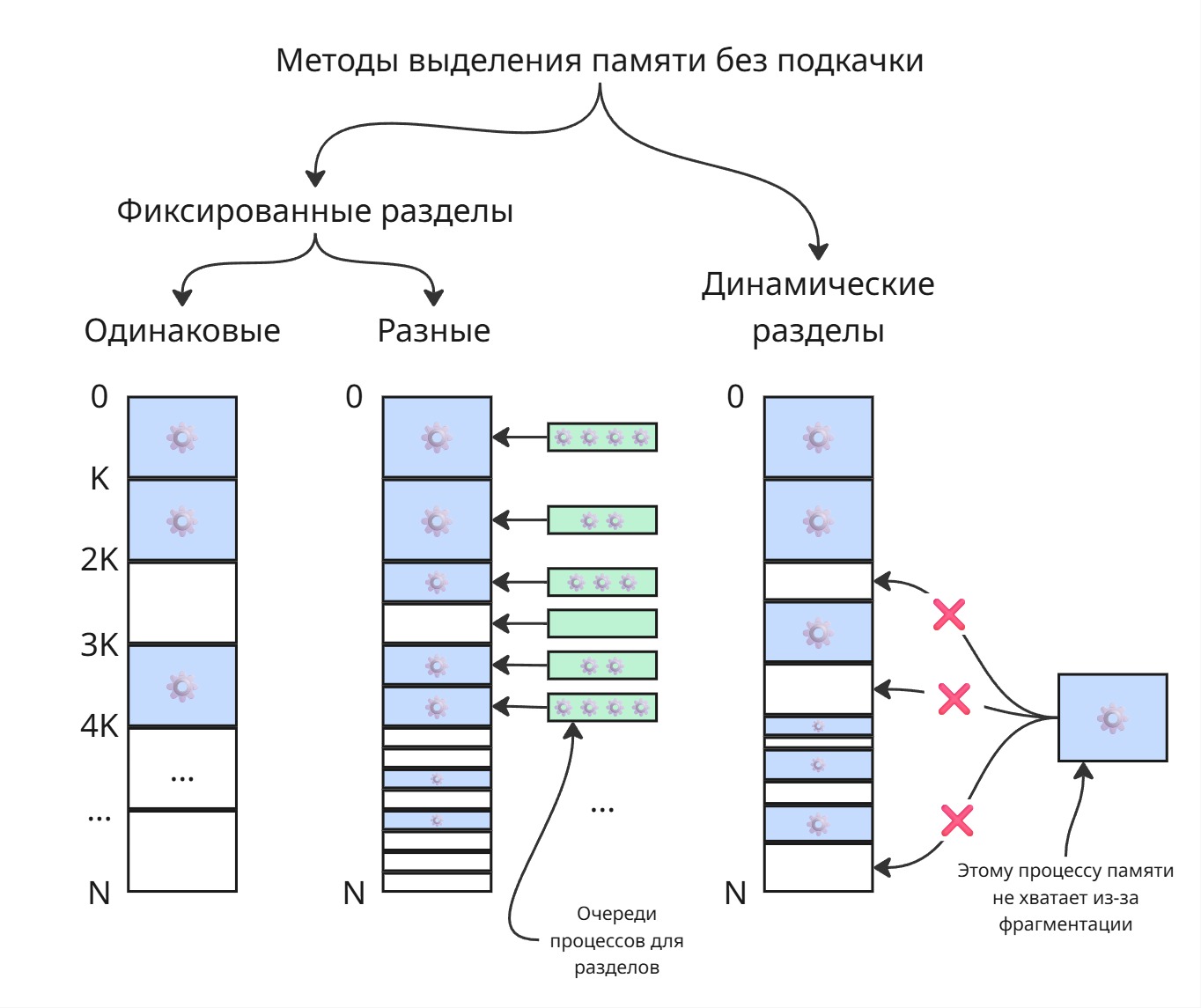
Одинаковые фиксированные разделы
Самым глупым решением является разбиение физической памяти на разделы, равного объема.
Мы можем разбить память на разделы равного размера. Можем каждому процессу присвоить раздел с номером его PID - таким образом, можно будет очень быстро вычислять адрес памяти процесса
Явный недостаток: процессы разные, могут использовать разное количество памяти - маленькие процессы не используют всю выделенную память, а большим процессам ее может не хватать
С таким выделением памяти появился overlaying - подкачка, реализованная процессом. Процесс сам решает в какой момент времени и какие данные ему перемещать на файл в диске
Фиксированные разделы разного размера
Можно сделать разделы разного раздела - тогда для появившегося процесса мы будем пытаться искать ему свободный раздел минимального возможного размера. Размер этот можно определять на этапе компиляции
Недостаток: если все маленькие разделы заняты, то маленькие процессы будут лезть в большие разделы, из-за чего они будут заняты для больших процессов
Тогда для каждого раздела можно сделать очередь из создавшихся процессов. Однако это может вызвать голодание - долгие маленькие процессы могут не давать исполняться быстрым маленьким. Для очередей можно сделать лифт: если процесс сидит долго в очереди, то можно его перенести в очередь большего раздела
Такой подход применяется в облачных виртуальных серверах - память на серверах дробится на разделы, которые даются виртуальной машине. А специальный регистр серверных процессоров хранит смещение раздела, поэтому обращение к памяти в разделе ничего не стоит
Динамические разделы
Зная, сколько памяти нужно процессу, мы можем последовательно выделять им память в физической памяти. Тогда, по мере работы операционной системы, процессы будут умирать, оставляя за собой свободное место. В итоге может оказаться так, что для нового большого процесса суммарно свободное место есть - однако его нельзя выделить непрерывным куском. С увеличением числа завершенных процессов память становится похожей на штрих-код. Такое явление называется фрагментацией памяти
Фрагментацию можно решать перемещением данных так, чтобы они образовывали непрерывную область (процесс дефрагментации). По мере дефрагментации мы должны будем заново пересчитать адреса в инструкциях процессов. Тогда возникают проблемы:
-
Когда вызывать дефрагментацию?
Здесь есть два подхода:
-
По возмущению
Когда хочет родится процесс, а места ему нет, то мы последовательно блокируем и перемещаем существующие процесс. Блокировка процесса нужна, чтобы не нарушать целостность данных (заблокировали один процесс перенесли)
В этом случае сервер будет быстро работать 15 минут, а другие 5 минут остановиться и будет считать адреса
-
В фоновом режиме периодически
При этом подходе сервер будет работать не на всю производительность
-
-
Как ее производить?
Алгоритм дефрагментации может включать в себя динамическое программирование: наша задача состоит в том, что бы за минимальное перемещение процессов в памяти получить блоки максимально возможного размера. В этом случае задачу нельзя решить в фоновом режиме, так как входные условия (то есть процессы) меняются по времени
Динамическое перемещение используется во внутренних системах управления (то есть микроконтроллерах, embedded) - все процессы известны, их потребляемая память тоже, поэтому задача решается легко
Методы выделения без подкачки требуют, что бы процессы знали, сколько им нужно памяти. Поэтому в таких системах становится невозможным использование динамической памяти
Появляются методы выделения памяти, использующие подкачку
Страничный обмен
Давайте процессу давать не один раздел, а несколько. Назовем их страницами. При обращении к памяти по адресу операционная система сама будет решать, в каком порядке нужно склеивать страницы, чтобы получить данные
Пусть в нашей системе есть n-битный процессор; здесь n - размер шины памяти. Тогда доступное нам число адресов памяти - это N = 2^n (для 32-битного процессора ~4 ГБ - максимальный возможный объем для таких систем; в 64-битных процессорах чаще всего используются 48-битные адреса, то есть ~256 ТБ)
Тогда в нашем распоряжении есть N адресов. Часть из них, а именно от 0 до K, существует как физические адреса на оперативной памяти объема K байт. Оставшаяся часть - это раздел подкачки на вторичном хранилище; в полном объеме она может быть и не представлена физически на диске, и обычно ее объем ограничен
Раздел подкачки по сути является отдельной файловой системой, которую реализовывает сама операционная система. Это позволяет предотвратить нежелательно чтение раздела, тем самым повышая безопасность
Эта память разбивается на страницы размера M (для удобства и быстродействия M - степень двойки)
У каждого процесса будет своя виртуальная память от 0 до N. Эта виртуальная память разбивается тоже на страницы размера M. В Linux по умолчанию размер одной страницы - 4096 байтов
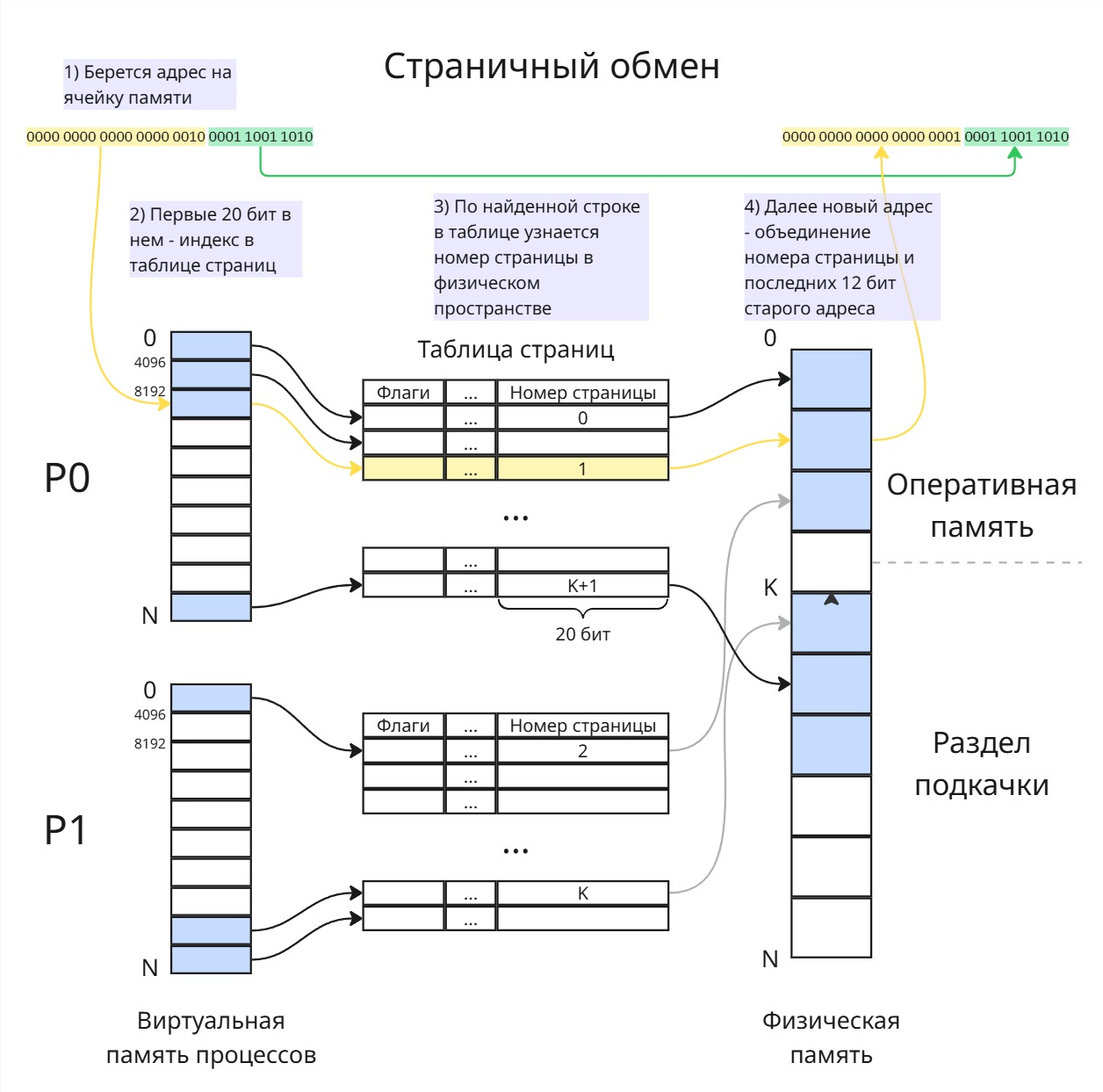
Теперь нужно сопоставить номер страницы в виртуальной памяти процесса к номеру страницы в оперативной памяти. Такой маппинг делается с помощью таблицы страниц (page table). В нашем случае, если n = 32, а M = 4096, то для каждого адреса последние 12 = log2 M бит будут указывать на адрес данных в конкретной странице, а оставшиеся 20 бит указывать на номер виртуальной страницы. Таблица страниц тогда будет массивом 4-байтных целых чисел
По этому номеру виртуальной страницы, как по индексу, мы можем получить нужную строку в таблице страниц. В таблице страниц последние 20 бит будут указывать на номер страницы в физическом адресном пространстве. Тогда вычисление физического указателя происходит так:
- Берется адрес в виртуальном пространстве процесса
- С помощью специального регистра, в котором хранится указатель на таблицу страниц процесса, и первых 20 бит адреса мы получаем строку (4-байтное число) в таблице страниц
- Последние 20 бит этой строки указывают на страницу в физическом пространстве
- Новый адрес получается как конкатенация этих 20 бит и последних 12 бит изначального адреса
Для такого подхода существует множество оптимизаций. Из 4 байт для строки мы использовали только 20 бит для указателя на страницу. Оставшиеся биты можно использовать для флагов оптимизации:
-
Если памяти в ОЗУ не осталось, то операционная система будет выделять страницы, находящиеся в разделе подкачки. Так как раздел подкачки находится на медленном диске, то доступ будет медленным, поэтому нужно сделать подмену страниц
По умолчанию, если обратиться к странице, которая находится за пределами физического адресного пространства, то возникнет прерывание отказа страницы (page fault). Операционная система обрабатывает это прерывание и делает и подмену страниц. В Linux подмену страниц делает демон [kswapd0]
Поимка прерывание - это очень долго, поэтому можно сделать флаг
P(от Present, илиMот Memory). Если он равен 1, то страница находится в ОЗУ, а если 0, то можно без прерывания сразу сделать подмену -
А с какими страницами делать подмену? Как понять, что страница больше не нужна в ОЗУ.
Для этого есть флаг
A(Accessed). Если к странице обратились на чтение или запись, то он становится 1. Следовательно, страницы с 0 можно свободно перемещать на диске, однако это не гарантирует, что ими не воспользуются в ближайшее время. Если же все страницы оказались с 1, то их флаги обнуляютБолее хитрое решение включает в себя цепной список из страниц для каждого процесса. Если был произведен доступ к страницы, то она переходит в конец списка. Таким образом, в начале останется самая невостребованная страница. Вместо списка можно использовать более хитрую структуру данных
-
Когда совершается подмена, то можно ненужную страницу не заменять на нужную на диске, а положить рядом
Тогда введем флаг
D(от Dirty, илиWот Write), который равен 1, если в таблицу была осуществлена запись. Теперь действуем так:- Выгрузили страницу A с ОЗУ на раздел подкачки рядом с B
- Загрузили страницу B на ОЗУ
- Если записи в страницу B не было, то значит ее можно не записывать на диск - так как она уже там есть и с тех пор никак не изменилась
-
Каскадное вычисление
Одна строчка в таблице подкачке обычно размером 4 байта. Несложно догадаться, что размер такой таблицы страниц будет 2^20 * 4 байт = 4 МБ. Такая таблица будет строиться для каждого процесса, значит, если процессов будет 100, то примерно полгигабайта будет тратиться на таблицы
Тогда разделим 20-битный номер страницы на 2 части по 10 бит. Первая часть - это индекс в корневой таблице страниц. С помощью нее мы можем получить номер страницы, где хранится другая таблица страница. В ней при помощи вторых 10 бит мы можем получить номер страницы в физическом пространстве
Тогда каждая такая таблица будет весить 4 КБ
В Linux, например, таких уровней не 2, а 4
Важно, что флаги, размер страницы, структура таблицы страниц может быть другими в зависимости от операционной системы и архитектуры процессора
Сегментно-страничная организация
Обычно виртуальная память процесса организована так:
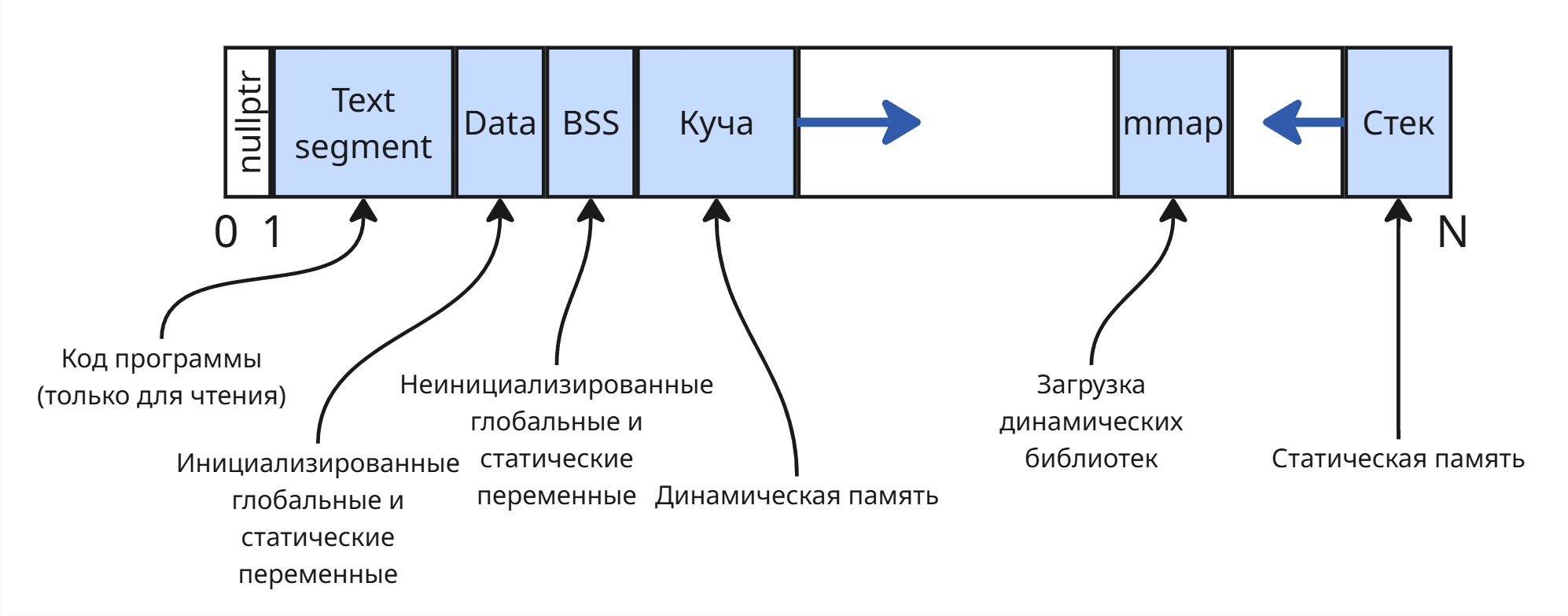
Поэтому в памяти хранятся не 2, а 6 страниц по 4 килобайта (1 - корневая таблица страниц, 2 - локальная таблица страниц, 3 - статичные переменные, 4 - верх стека, 5 - верх кучи, 6 - верх mmap)
Придумали и аппаратно реализовали TLB кеш (translation lookaside buffer, буфер ассоциативной трансляции). По сути это табличка размером 64 строки, где ключ - это номер виртуальной страницы, а значение номер физической страницы.
С помощью специальной инструкции процессора можно быстро получить значение по ключу в этом кеше, чтобы достать номер физической страницы, либо узнать, что ее там нет
Таким образом, можно не обращаться к таблице страниц, а узнавать адрес прямо через кеш
Если процесс меняется, то кеш можно либо удалить (что неэффективно в дальнейшем), либо сохранять кеш вместе с регистровым контекстом (что медленно, так как смена регистра используется очень часто)