itmo_conspects
Лекция 5. Архитектура ОС, часть 2
Информационная архитектура
Информационный уровень фокусируется на определении объектов (например, процессы, файлы, структуры данных), взаимосвязей между ними и жизненного цикла этих объектов.
-
Управление процессами
Процесс - специальный объект в ОС, представляющий собой структуру в оперативной памяти. В Linux процессы хранятся в массиве
Управление процессами строится на двух объектах: дескриптор процесса (или PCB, Process Control Block) и очередь
Дескриптор хранит информацию
- об идентификации процесса (PID - Process ID, UID - User ID, PPID - Parent Process ID и другие)
- о ресурсах (выделенные странички в памяти, сокеты и другие)
- об истории (для использования планировщиком)
Очереди же используются для равномерной нагрузки процессора. В теории массового обслуживания, одном из разделов математики, исследуют системы массового обслуживания - в нашем случае, это компьютер или так называемый прибор. Прибору поступает потом требований (задач), задающихся набором характеристик. Поток требований может быть сгущенными или разряженными. Прибор обрабатывает эти требования, при этом время, за которое он их обработает - случайная величина
Если прибор занят одним требованием и не может удовлетворить другое, то другое попадает в очередь На выходе поток требований получается равномерный, который определяется производительностью прибора
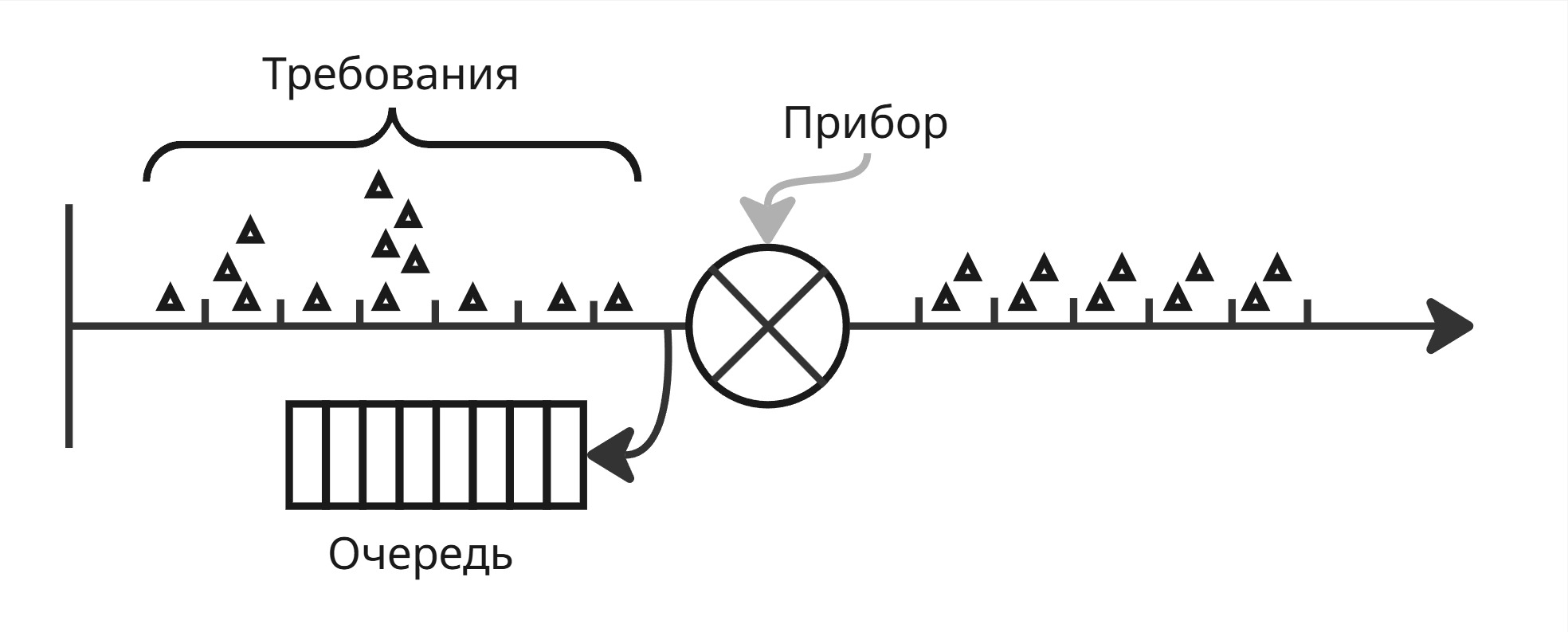
Очередь, сглаживающая поток требований, является фильтром Калмана и используется для равномерного поступления процессов в исполнение процессором
-
Управление памятью
Управление памятью же стоит на виртуальной памяти и защите памяти
Об этом уже было сказано раньше. Виртуальная память - это концепция, позволяющая операционной системе создавать абстракцию адресного пространства, которая отделяет физическую память от логических адресов, используемых программами
Защита памяти - это управление правами доступа к некоторым участкам памяти для процессов
-
Управление файлами
Файловую систему представляют две сущности: файл и каталог
Традиционное определение говорит, что файл - это именованная область данных.
В Linux же файл - это универсальный интерфейс для доступа к даннымВ Windows же каталог и файл - отдельные сущности, а в Linux все - это файл.
В Linux файл может храниться в двух каталогах одновременно - файл определяется при помощи идентификатора, называемого айнодом, и в Linux можно создать два файла с разными именами и в разных каталогах с одним айнодом (так называемая жесткая ссылка)
-
Управление внешними устройствами
Ядро должно знать, с каким железом должно работать. Вместо того, чтобы в ядре писать код для работы со всеми железяками, придумали драйверы - модули, соединяющие операционную систему и аппаратное обеспечение
Лет 20 назад драйвера вручную линковали с ядром, а затем его компилировали
Потом Microsoft, входя в игровую индустрию с разнообразными контроллерами, захотела сделать драйверы более удобными для пользователей. Такая фича стала называться “Plug-And-Play”: при подключении устройство отправляло по проводу свой идентификатор, операционная система считывала его, из своей базы данных доставало нужный драйвер и включало его
-
Защита данных и администрирования
Здесь же используются объекты учетной записи (с концепцией идентификации, аутентификации и авторизации) и аудит, журналирование с анализом и поиском аномалий (подробнее см. курс баз данных)
-
Пользовательский интерфейс
В качестве пользовательского интерфейса выступают CLI и GUI
CLI (Command Line Interface) - интерфейс командной строки. GUI (Graphical User Interface) - графический интерфейс пользователя
В Linux основным является CLI, а в Windows - GUI в качестве нативного для ядра
Системная архитектура
Системная архитектура описывает то, как организован код операционной системы.
Код ядра:
- выполняется в привилегированном режиме (без защиты памяти)
- является резидентом - то есть весь код находится в оперативной памяти в одних и тех же адресах (не использует виртуализацию, что улучшает производительность)
Получается, что ядро со всеми драйверами может занять всю оперативную память. Поэтому нужно принимать решения, что включать в ядро. Со временем выработалось 5 принципов построения архитектуры ОС:
- Модульная организация кода
- Функциональная избыточность - закладываем больше функционала, чем нужно обычному пользователю
- Функциональная избирательность - закладываем возможность отключить ненужные компоненты
- Параметрическая универсальность - не хардкодить константы
- Иерархическая вычислительная система