itmo_conspects
Программирование на C++ с элементами многопоточности
- Программирование на C++ с элементами многопоточности
- Лекция 1. Идиомы C++
- Лекция 2. Примитивы синхронизации в C++
- Лекция 3. Общение по протоколам TCP и UDP в Boost
- Лекция 4. Общение по протоколам HTTP и WebSocket в Boost
- Лекция 5. Основные инструменты в Qt
- Лекция 6. Виджеты и локализация в Qt
- Лекция 7. Продвинутые инструменты Qt
- Лекция 8. Упорядочивания в
std::atomicи барьеры памяти - Лекция 9. Другие оптимизации в C++
Лекция 1. Идиомы C++
Идиома RAII
С++ - язык с ручным управлением ресурсами, в нем нужно разработчику управлять выделением и освобождение памяти
Поэтому появилась идиома RAII (Resource Acquisition is Initialization) - “Получение ресурса есть инициализация”
Для некоторых объектов (например, для памяти, файловых дескрипторов) важно гарантировать освобождение ресурса при выходе из области видимости. Идиома утверждает, что ресурсы должны быть выделены, получены при инициализации (в конструкторе) и высвобождены в деструкторе
Принципу RAII соответствуют умные указатели std::unique_ptr и мьютексы std::lock_guard. В случае мьютексов код, не следующии RAII, выглядит так:
{
mutex1.lock()
// критическая секция
// здесь может быть return или throw
mutex1.unlock()
}
Здесь нужно быть внимательным, чтобы mutex1.unlock() однозначно вызвался. std::lock_guard избавляет от этого:
{
std::lock_guard lck(mutex1);
// конструктор делает mutex1.lock()
// критическая секция
// деструктор делает mutex1.unlock()
}
Деструктор вызывается в любом случае при выходе из скоупа, поэтому мьютекс будет однозначно разблокирован
Уникальный указатель std::unique_ptr
Умные указатели std::unique_ptr и пара std::shared_ptr-std::weak_ptr также следуют идиоме RAII и используются для управления памяти
Уникальный указатель std::unique_ptr владеет объектом единолично. Копирование такое указателя запрещено, но разрешено перемещение
std::unique_ptr создается с помощью std::make_unique, а не через конструктор. Рассмотрим такой пример:
Foo(new Bar(), std::unique_ptr<Boo>(new Boo()));
Стандарт C++ не указывает, в каком порядке должны быть созданы объекты-аргументы, поэтому может случиться такая ситуация:
- Создается
new Bar() - Создается
new Boo(), выделив память, конструктор которого вызывает исключение - Создается
std::unique_ptr(new Boo())
Исключение перехватывается на уровне выше по стеку вызовов, но память, выделившаяся в конструкторе new Bar(), не освободиться, поэтому возникнет утечка памяти. Вместо этого лучше использовать std::make_unique:
Foo(std::make_unique<Bar>(), std::make_unique<Boo>());
Разделяемый указатель std::shared_ptr и слабый указатель std::weak_ptr
Разделяемый указатель std::shared_ptr используется, когда объект должен иметь несколько владельцев. Каждый разделяемый указатель увеличивает счетчик ссылок при создании и копировании, уменьшает при уничтожении, а когда счетчик становится равен нулю - объект уничтожается
Рекомендуется создавать std::shared_ptr с помощью std::make_shared по тем же причинам
Вместе с std::shared_ptr в комплекте идет тип слабого указателя. Слабый указатель std::weak_ptr создан для того, чтобы избавиться от кольцевых зависимостей
struct B;
struct A {
std::shared_ptr<B> b;
};
struct B {
std::shared_ptr<A> a;
};
Если A и B ссылаются друг на друга через std::shared_ptr, счетчик ссылок никогда не станет нулем, и возникнет утечка памяти
Слабый указатель weak_ptr используется вместе с shared_ptr, но сам по себе ничего не хранит. Вместо этого можно вызвать метод .lock(), который вернет shared_ptr, если объект существует внутри, или nullptr, если он был уничтожен (то есть больше нет живых std::shared_ptr):
std::shared_ptr<Foo> shptr = std::make_shared<Foo>();
// ...
std::weak_ptr<Foo> wptr = shptr;
if (auto sptr = wptr.lock()) {
// объект еще существует
} else {
// объект уже уничтожен
}
std::shared_ptr при создании через std::make_shared выделяет один непрерывный блок памяти c самим объектом, счетчиком разделяемых указателей и счетчиком слабых указателей. Это эффективнее по памяти и быстрее по времени
Если счетчик std::shared_ptr становится равен нулю, объект уничтожается, но управляющий блок (в котором хранятся счетчики) остается в памяти, пока существуют std::weak_ptr
Если подразумевается, что слабых указателей во время жизни программы будет много, то не рекомендуется использовать std::make_shared
Также копирование и уничтожение разделяемых указателей потокобезопасно, так как инкремент и декремент - атомарные операции, однако доступ к самим данным не является потокобезопасным
Функтор
Также для создания программ на C++ полезны функторы
Функтор (functor) — это объект, который можно вызывать как функцию. Он реализует оператор operator()
Функторы реализуют паттерн «Команда» — объект, хранящий в себе функцию и ее состояние.
Пример:
struct Add {
int x;
Add(int x) : x(x) {}
int operator()(int y) const {
return x + y;
}
};
int main() {
Add number(10);
std::cout << number(5); // 15
}
Потоки
Зачастую количество выполняемых поток превышает число ядр процессора, что позволяет обрабатывать больше вычислений. Это достигается с помощью:
-
Корутин
Корутина (или сопрограмма) - программный модуль, сделанный таким образом, чтобы взаимодействовать с другими по принципу кооперативной многозадачности
По сути корутины исполняются в пределах одного процессорного потока: корутина приостанавливает исполнения там, где она хочет, затем менеджер выбирает следующую корутину для исполнения
Корутины бывает со стеком (stackful), если у каждой из них свой программный стек, и бесстековые (stackless), если у них общий стек с функцией, вызывающей корутины
В стандарте C++20 корутины бесстековые, и тот вид, в которой они представлены, спорен, поэтому рекомендуется их использовать в связке с оборачивающей их библиотекой
-
Hyper-Threading/Simultaneous Multithreading
Hyper-Threading у процессоров Intel и Simultaneous Multithreading у процессоров AMD позволяет производить вычисления двух потоков на одном ядре
Для этого в одном физическом ядре:
- два или более наборов регистров, указателей команд и контроллеров прерываний
- но совместные исполнительные блоки (ALU для целочисленной арифметики, FPU для работы с числами с плавающей точкой)
- совместные блоки кеш-памяти L1, L2, L3
- совместные блоки предсказания переходов
С технологией Hyper-Threading есть два (или более) логических ядра, у которых один и тот же кеш и предиктор, но выполняются они разные вычисления (поэтому увеличивается число промахов в кеш)
Константа
std::hardware_concurrencyпокажет, сколько существует логических ядер процессора -
Потоки операционной системы
В C++ потоки представлены объектом
std::thread, который принимает любой вызываемый объект вместе с аргументами. Возвращаемое значение при этом игнорируется.std::thread t([]{ // код потока });Обычно этот функтор - это лямбда-функция, которая захватывает по ссылке флаг, означающий завершенность потока
std::atomic<bool> flag = true; std::thread t([&]{ // работа потока flag = false; }); while (flag) { // ожидание } t.join();В основной функции происходит ожидание этого флага
В рамках процесса потоками, на уровне которых работает планировщик, память и другие ресурсы общие, поэтому можно производить действия над общими структурами
Для лучшего управления потоками есть объекты
std::futureиstd::promise. Объектstd::promiseпредставляет обещание передать в него значение, аstd::futureпредставляет будущее, из которого значение будет полученоstd::promise<int> p; std::future<int> f = p.get_future(); std::thread t([&]{ p.set_value(42); }); // делает какую-то параллельную работу int result = f.get(); // ждет результат t.join();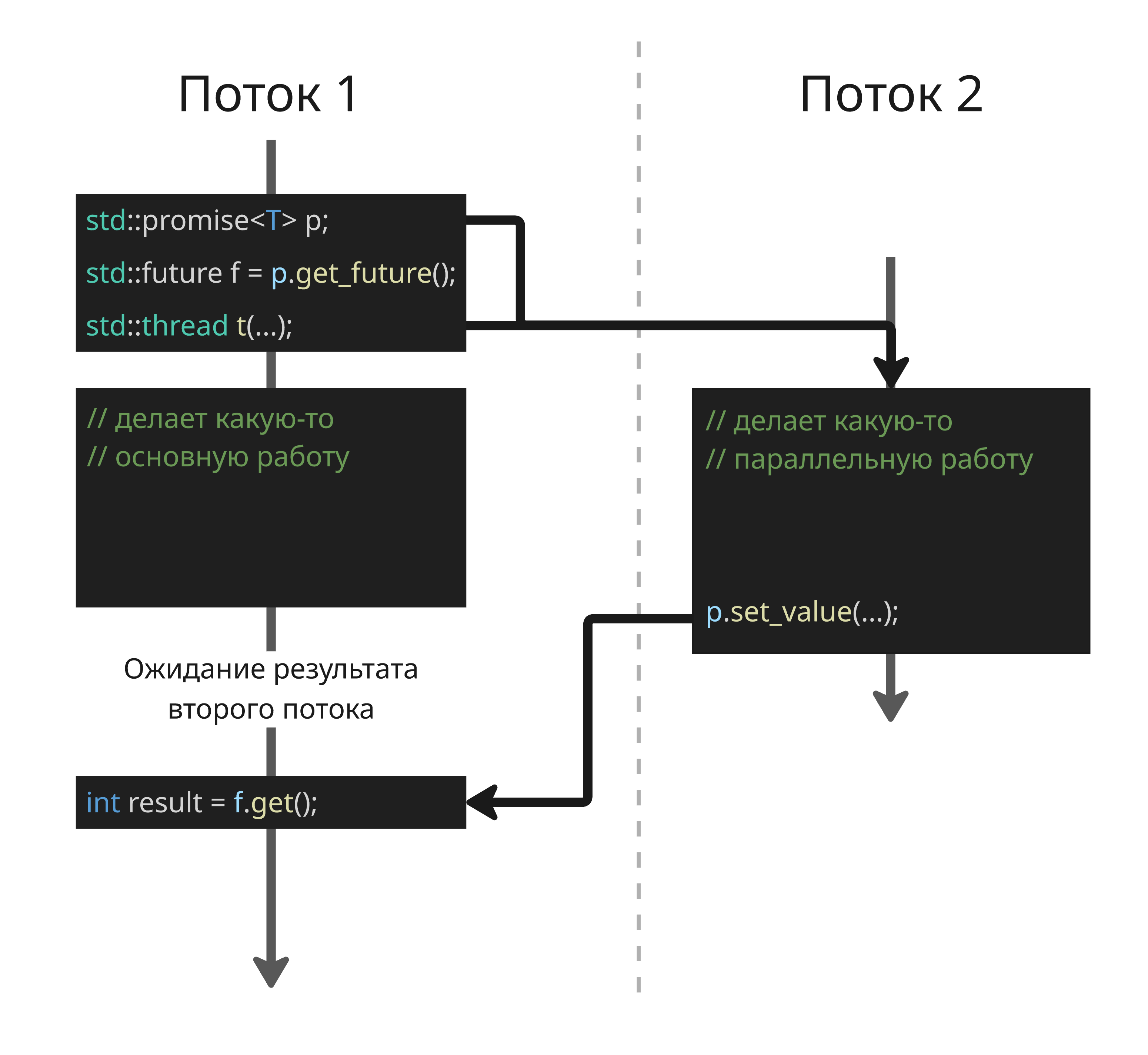
Объект
std::asyncеще сильнее упрощает работу: он создает поток, запускает функцию и возвращаетstd::futureс результатом:auto f = std::async([]{ return 42; }); int result = f.get();Для
std::asyncесть политики запуска:// обязательно создастся новый поток std::async(std::launch::async, func); // ленивый запуск, задача не начинает // выполнение в момент вызова, а в момент получения результата // и в этом же потоке std::async(std::launch::deferred, func);
Лекция 2. Примитивы синхронизации в C++
В качестве объектов для синхронизации потоков используются классы:
std::mutex- базовая реализация мьютекса. Обеспечивает взаимное исключение: только один поток может владеть мьютексом в каждый момент времениstd::lock_guard- обёртка для мьютекса, реализующая принцип RAII. При создании объекта мьютекс захватывается, при уничтожении (выходе из области видимости) - освобождается автоматически
std::mutex m;
int shared_counter = 0;
void increment() {
std::lock_guard<std::mutex> lock(m); // lock() вызывается здесь
++shared_counter;
} // unlock() вызывается автоматически при разрушении lock
Семафоры и другие низкоуровневые примитивы, как правило, не используются в обычном прикладном коде - они появляются преимущественно в системном программировании или при реализации собственных примитивов синхронизации
Также существуют модификация мьютекса – разделенный мьютекс. Разделенный мьютекс (или RW-mutex) std::shared_mutex работает аналогично обычному мьютексу, но допускает несколько одновременных блокировок для чтения и только одну для записи. Это полезно, когда операции чтения значительно преобладают над записью:
| Операция | Обёртка | Метод мьютекса |
|---|---|---|
| Запись (единичный доступ) | std::unique_lock |
lock() |
| Чтение (совместный доступ) | std::shared_lock |
lock_shared() |
Пример:
std::shared_mutex rw_mutex;
std::map<int, std::string> data;
// Читать могут несколько потоков одновременно
std::string read(int key) {
std::shared_lock lock(rw_mutex);
return data.at(key);
}
// Писать может только один поток
void write(int key, std::string value) {
std::unique_lock lock(rw_mutex);
data[key] = std::move(value);
}
Тип std::atomic<T>
Рассмотрим простой счётчик, к которому обращаются два потока:
int counter = 0;
void increment() {
++counter; // НЕ атомарная операция!
}
На уровне машинных инструкций ++counter - это три отдельных шага:
lw a5,-20(s0) # прочитать значение counter из памяти в регистр
addi a5,a5,1 # прибавить 1 к регистру
sw a5,-20(s0) # записать результат обратно в память
Если два потока выполняют эти шаги одновременно, возникает гонка обновлений:
- Поток A:
lw a5,-20(s0)- читает 0 - Поток B:
lw a5,-20(s0)- читает 0 - Поток A:
addi a5,a5,1,sw a5,-20(s0)- пишет 1 - Поток B:
addi a5,a5,1,sw a5,-20(s0)- пишет 1, но должен быть 2
Тип std::atomic<T> позволяет выполнять такие операции над переменной атомарно без явного использования мьютекса:
std::atomic<int> counter{0};
// Безопасно из нескольких потоков без мьютекса
void increment() {
counter.fetch_add(1); // или просто ++counter
}
std::atomic<T> гарантирует, что все операции над переменной выполняются неделимо, без возможности вмешательства другого потока. Под капотом процессор использует специальные инструкции (например, LOCK XADD, CMPXCHG на x86-архитектуре) или шины памяти, которые делают операцию неделимой на аппаратном уровне - без блокировок и переключения контекста
Основные методы:
-
Чтение и запись
std::atomic<int> x{0}; x.store(42); // записать значение int val = x.load(); // прочитать значение int val2 = x; // неявный вызов load() x = 42; // неявный вызов store()storeиloadпредпочтительнее неявных операторов - они явно сигнализируют, что работа идёт с атомарной переменной. -
Обмен
std::atomic<int> x{10}; int old = x.exchange(99); // атомарно: записать 99, вернуть старое значение (10)Полезно, например, для атомарного сброса флага:
std::atomic<bool> flag{true}; if (flag.exchange(false)) { // Только один поток войдёт сюда, даже при гонке } -
Сравнение и замена (Compare-and-swap, CAS) - ключевой механизм для алгоритмов без замков
bool compare_exchange_strong(T& expected, T desired); bool compare_exchange_weak(T& expected, T desired);Атомарно выполняется следующее:
if (x == expected) { x = desired; return true; } else { expected = x; // обновляет expected текущим значением return false; }Разница между сильным и слабым сравнениями:
compare_exchange_strong- гарантирует успех, еслиx == expectedcompare_exchange_weak- может ложно вернутьfalse, зато быстрее на некоторых архитектурах (RISC, ARM), используется в цикле
-
Арифметические операции (только для целых чисел и указателей)
std::atomic<int> x{10}; x.fetch_add(5); // x = 15, возвращает старое значение (10) x.fetch_sub(3); // x = 12, возвращает старое значение (15) x.fetch_and(0xF); // побитовое AND x.fetch_or(0x1); // побитовое OR x.fetch_xor(0x3); // побитовое XOR // Операторы-сокращения (не возвращают старое значение): ++x; x++; --x; x--; x += 5; x -= 3;
Каждый метод atomic принимает опциональный параметр std::memory_order, который управляет тем, как компилятор и процессор могут переупорядочивать инструкции вокруг атомарной операции, например, x.store(1, std::memory_order_relaxed);
| Memory Order | Смысл |
|---|---|
relaxed |
Никаких гарантий порядка - только атомарность самой операции, поэтому максимальная производительность |
acquire |
Все последующие операции с памятью в этом потоке выполнятся после этой загрузки, используется при load |
release |
Все предшествующие операции с памятью в этом потоке выполнятся до этой записи, используется при store |
acq_rel |
Комбинация acquire и release, используется для exchange, fetch_add |
seq_cst |
Полная последовательная согласованность. Самый безопасный, поэтому значение по умолчанию, но самый медленный |
Типичный паттерн acquire/release - передача данных между потоками без мьютекса:
std::atomic<bool> ready{false};
int data = 0;
// Поток A (производитель)
void producer() {
data = 42; // (1) запись данных
ready.store(true, std::memory_order_release); // (2) публикуем флаг
// release гарантирует, что (1) виден до (2)
}
// Поток B (потребитель)
void consumer() {
while (!ready.load(std::memory_order_acquire)); // (3) ждём флага
// acquire гарантирует, что после (3) мы видим (1)
assert(data == 42); // всегда верно
}
Без acquire и release компилятор или процессор мог бы переставить инструкции так, что data читался бы до того, как производитель его записал
Если нет уверенности, какой порядок использовать, то лучше оставить значение по умолчанию seq_cst, так как оптимизировать такое стоит только тогда, когда есть реальная проблема производительности
Тип std::recursive_mutex
Обычный std::mutex вызовет блокировку, если один и тот же поток попытается заблокировать его дважды. std::recursive_mutex решает эту проблему - он позволяет одному потоку захватывать мьютекс несколько раз подряд (и должен освободить его столько же раз)
Типичный случай - это методы класса, которые вызывают друг друга, при этом каждый берёт блокировку:
class SafeCollection {
std::recursive_mutex m;
std::vector<int> data;
public:
void add(int x) {
std::lock_guard lock(m);
data.push_back(x);
}
void add_twice(int x) {
std::lock_guard lock(m); // первый захват
add(x); // второй захват того же мьютекса
add(x);
}
};
С обычным std::mutex вызов add() внутри add_twice() привёл бы к взаимной блокировке, так как поток попытался бы заблокировать уже захваченный им мьютекс
Тип std::scoped_lock
std::scoped_lock - аналог std::lock_guard, но позволяет захватить несколько мьютексов одновременно, избегая взаимной блокировки:
std::mutex m1, m2;
void transfer(Account& from, Account& to, int amount) {
// Захватываем оба мьютекса атомарно
std::scoped_lock lock(m1, m2);
from.balance -= amount;
to.balance += amount;
}
Если бы два потока захватывали m1 и m2 в разном порядке по отдельности - была бы классическая взаимная блокировка, а тип scoped_lock этого не допускает
Spinlock
Spinlock - это мьютекс, который при ожидании не усыпляет поток, а крутится в цикле. Он быстрее обычного мьютекса при очень коротких критических секциях, но сжигает процессорное время впустую при долгом ожидании
#include <atomic>
class Spinlock {
std::atomic_flag flag = ATOMIC_FLAG_INIT;
public:
void lock() { while (flag.test_and_set(std::memory_order_acquire)); }
void unlock() { flag.clear(std::memory_order_release); }
};
Петля событий
Поток, как правило, - тоже ресурс, выделяемый операционной системой. Его создание и освобождение занимают время, поэтому стараются переиспользовать потоки. Из-за этого есть один поток, который принимает задачи в очереди
Создаём поток; если есть разделяемый ресурс (очередь задач) - создаём мьютекс для доступа к нему. Вот как выглядит типичный event loop:
std::queue<std::function<void()>> tasks;
std::mutex m;
Task t;
while (true) {
{
std::lock_guard l(m);
if (!tasks.empty()) {
t = std::move(tasks.front());
tasks.pop();
}
} // мьютекс освобождается здесь
if (t) {
t();
t = nullptr;
}
std::this_thread::sleep_for(std::chrono::nanoseconds(100));
}
Без паузы поток будет непрерывно захватывать и освобождать мьютекс в цикле, не давая другим потокам возможности в него войти, создавая процессорное голодание. Пауза в 100 нс - это компромисс: поток уступает процессор, но очень ненадолго.
std::condition_variable
std::condition_variable позволяет потоку заснуть до наступления условия и быть разбуженным другим потоком
std::mutex m;
std::queue<std::function<void()>> tasks;
std::condition_variable cv;
bool done = false;
// Поток-потребитель
void worker() {
while (true) {
std::unique_lock lock(m); // condition_variable требует unique_lock
// Засыпаем, пока очередь пуста (и не завершаем работу)
cv.wait(lock, [] { return !tasks.empty() || done; });
if (done && tasks.empty()) break;
auto task = std::move(tasks.front());
tasks.pop();
lock.unlock(); // освобождаем мьютекс перед выполнением задачи
task();
}
}
// Поток-производитель
void enqueue(std::function<void()> task) {
{
std::lock_guard lock(m);
tasks.push(std::move(task));
}
cv.notify_one(); // будим одного спящего потребителя
}
Ключевые методы:
| Метод | Описание |
|---|---|
cv.wait(lock, predicate) |
Засыпает, пока предикат не вернёт true. Атомарно освобождает мьютекс при засыпании и снова захватывает при пробуждении. |
cv.notify_one() |
Будит один ожидающий поток. |
cv.notify_all() |
Будит все ожидающие потоки. |
condition_variable::wait должен временно освободить мьютекс, пока поток спит - lock_guard этого не умеет, а unique_lock поддерживает ручное lock() и unlock()
Также важно заметить, что поток может проснуться без вызова notify. Именно поэтому wait принимает предикат - без него нужно писать цикл while (!predicate()) cv.wait(lock); вручную
Лекция 3. Общение по протоколам TCP и UDP в Boost
Boost.Asio - это библиотека для сетевого и низкоуровневого ввода-вывода, которая позволяет писать и синхронные, и асинхронные программы. Главная идея в том, что все операции (чтение, запись, подключения) можно делать без ожидания завершения, а когда операция завершится - вызывается функция-обработчик. Это позволяет обслуживать тысячи соединений в одном или нескольких потоках
Раньше для имитации постоянного соединения с сервером использовали Long polling. Клиент отправлял HTTP-запрос, сервер не отвечал сразу, а держал соединение открытым до появления новых данных, затем отвечал, и клиент тут же делал новый запрос. Это создавало много накладных расходов: постоянные переподключения, HTTP-заголовки, задержки
Позже появились WebSocket - протокол полного дуплекса (full duplex) поверх TCP. После установки соединения и сервер, и клиент могут отправлять данные в любой момент без дополнительных запросов. Это позволяет делать настоящие приложения: чаты, игры, биржевые котировки. В Boost для работы с WebSocket обычно используют Boost.Beast, который построен на основе Boost.Asio
Пространство имён boost::asio::ip содержит классы для работы с адресами и конечными точками (endpoint). Внутри него есть:
boost::asio::ip::tcp- для TCP-соединений: классыsocket,acceptor(для приёма входящих соединений),resolver(разрешение имён). TCP гарантирует доставку и порядок данных, но медленнее, чем UDPboost::asio::ip::udp- для UDP-дейтаграмм: классыsocket,endpoint,resolver. UDP не устанавливает соединение, доставка и порядок не гарантируются, зато низкая задержка
Пример простого TCP-клиента, который подключается к серверу и отправляет сообщение:
#include <boost/asio.hpp>
#include <iostream>
using namespace boost::asio;
using ip::tcp;
int main() {
io_context io;
tcp::socket socket(io);
tcp::resolver resolver(io);
// подключаемся к localhost на порт 12345
connect(socket, resolver.resolve("127.0.0.1", "12345"));
std::string message = "Hello, Boost!\n";
write(socket, buffer(message));
// читаем ответ
char reply[1024];
size_t len = socket.read_some(buffer(reply));
std::cout << "Server replied: ";
std::cout.write(reply, len);
std::cout << std::endl;
return 0;
}
Для защищённых соединений используется boost::asio::ssl. Это обёртка над OpenSSL (или другой библиотекой), которая позволяет делать рукопожатие TLS/SSL и шифрованный обмен. Контекст ssl::context хранит сертификаты и настройки. Поток ssl::stream оборачивает TCP-сокет и предоставляет методы handshake, async_handshake, write, read для защищённой передачи
Пример простого синхронного SSL-сервера, принимающего одно соединение и читающего данные:
#include <boost/asio.hpp>
#include <boost/asio/ssl.hpp>
#include <iostream>
using namespace boost::asio;
using ip::tcp;
int main() {
io_context io;
ssl::context ctx(ssl::context::sslv23);
ctx.set_options(ssl::context::default_workarounds);
ctx.use_certificate_chain_file("server.crt");
ctx.use_private_key_file("server.key", ssl::context::pem);
tcp::acceptor acceptor(io, tcp::endpoint(tcp::v4(), 12345));
tcp::socket socket(io);
acceptor.accept(socket); // ждём подключения
ssl::stream<tcp::socket> stream(std::move(socket), ctx);
stream.handshake(ssl::stream_base::server); // SSL-рукопожатие
char data[256];
size_t len = stream.read_some(buffer(data));
std::cout << "Received: ";
std::cout.write(data, len);
std::cout << std::endl;
stream.shutdown();
return 0;
}
Теперь перейдём к асинхронному серверу. В нём вместо блокирующих операций используются функции, начинающиеся с async_, и io_context.run() запускает цикл обработки событий. Каждая операция принимает обработчик, который будет вызван после завершения. Это позволяет обрабатывать множество соединений одновременно в одном потоке
Пример асинхронного TCP-сервера, который принимает соединения, читает сообщение и отправляет ответ:
#include <boost/asio.hpp>
#include <iostream>
#include <memory>
using namespace boost::asio;
using ip::tcp;
// Класс сессии: владеет сокетом, читает данные, отправляет ответ
class Session : public std::enable_shared_from_this<Session> {
public:
explicit Session(tcp::socket socket) : socket_(std::move(socket)) {}
void start() {
do_read();
}
private:
tcp::socket socket_;
char data_[1024];
void do_read() {
auto self(shared_from_this());
socket_.async_read_some(buffer(data_),
[this, self](boost::system::error_code ec, size_t length) {
if (!ec) {
// обрабатываем полученные данные и шлём ответ
std::string message(data_, length);
std::cout << "Received: " << message;
std::string reply = "Echo: " + message;
async_write(socket_, buffer(reply),
[this, self](boost::system::error_code, size_t) {
// после ответа закрываем соединение
socket_.close();
});
}
});
}
};
// Класс сервера: слушает порт и принимает новые соединения
class Server {
public:
Server(io_context& io, short port)
: acceptor_(io, tcp::endpoint(tcp::v4(), port)) {
do_accept();
}
private:
tcp::acceptor acceptor_;
void do_accept() {
acceptor_.async_accept(
[this](boost::system::error_code ec, tcp::socket socket) {
if (!ec) {
std::make_shared<Session>(std::move(socket))->start();
}
do_accept(); // продолжаем принимать
});
}
};
int main() {
io_context io;
Server server(io, 12345);
std::cout << "Async server listening on port 12345\n";
io.run(); // запуск цикла обработки асинхронных операций
return 0;
}
В этом коде нет блокировок: acceptor_.async_accept сразу возвращает управление, и когда приходит новое подключение - вызывается лямбда. Сессия создаётся через shared_ptr, чтобы объект жил, пока идёт асинхронная операция. Внутри do_read тоже асинхронное чтение, и после чтения асинхронно отправляется ответ. io_context::run() крутит цикл событий до тех пор, пока есть незавершённые операции
Такой асинхронный подход лежит в основе масштабируемых сетевых приложений на Boost.Asio, включая WebSocket-серверы через Boost.Beast
Лекция 4. Общение по протоколам HTTP и WebSocket в Boost
Boost.Beast - это надстройка над Boost.Asio, предоставляющая готовую реализацию HTTP и WebSocket. Классы для работы с HTTP находятся в пространстве имён boost::beast::http, а для веб-сокетов - в boost::beast::ws. Это позволяет быстро создавать сетевые приложения, работающие по этим протоколам, не изобретая разбор заголовков и рукопожатий вручную
- HTTP в
boost::beast::httpумеет формировать запросы и ответы, парсить их, обрабатывать поля заголовков. Можно использовать синхронный и асинхронный ввод-вывод - WebSocket в
boost::beast::wsдаёт классstream, который после выполнения обновления протокола позволяет отправлять и принимать текстовые и бинарные кадры в режиме полного дуплекса
Пример простого HTTP-клиента, который отправляет GET-запрос и выводит тело ответа:
#include <boost/beast/core.hpp>
#include <boost/beast/http.hpp>
#include <boost/beast/version.hpp>
#include <boost/asio/connect.hpp>
#include <boost/asio/ip/tcp.hpp>
#include <iostream>
#include <string>
namespace beast = boost::beast;
namespace http = beast::http;
namespace net = boost::asio;
using tcp = net::ip::tcp;
int main() {
net::io_context io;
tcp::resolver resolver(io);
beast::tcp_stream stream(io);
auto const results = resolver.resolve("example.com", "80");
stream.connect(results);
http::request<http::string_body> req{http::verb::get, "/", 11};
req.set(http::field::host, "example.com");
req.set(http::field::user_agent, BOOST_BEAST_VERSION_STRING);
http::write(stream, req);
beast::flat_buffer buffer;
http::response<http::dynamic_body> res;
http::read(stream, buffer, res);
std::cout << res << std::endl;
beast::error_code ec;
stream.socket().shutdown(tcp::socket::shutdown_both, ec);
return 0;
}
Пример WebSocket-клиента, который подключается к серверу, отправляет сообщение и читает ответ:
#include <boost/beast/core.hpp>
#include <boost/beast/websocket.hpp>
#include <boost/asio/connect.hpp>
#include <boost/asio/ip/tcp.hpp>
#include <iostream>
namespace beast = boost::beast;
namespace ws = beast::websocket;
namespace net = boost::asio;
using tcp = net::ip::tcp;
int main() {
net::io_context io;
tcp::resolver resolver(io);
ws::stream<tcp::socket> ws(io);
auto const results = resolver.resolve("echo.websocket.org", "80");
net::connect(ws.next_layer(), results);
ws.handshake("echo.websocket.org", "/");
ws.write(net::buffer(std::string("Hello, WebSocket!")));
beast::flat_buffer buffer;
ws.read(buffer);
std::cout << beast::make_printable(buffer.data()) << std::endl;
ws.close(ws::close_code::normal);
return 0;
}
Для кастомных протоколов, где сообщения не оформлены как HTTP или WebSocket, часто используют разделители (например, конец строки \n или специальная последовательность байт). Здесь помогает свободная функция boost::asio::read_until. Она читает данные из потока до тех пор, пока во входном буфере не встретится заданный разделитель. Это удобно для текстовых протоколов или бинарных фреймов с известной сигнатурой конца. После завершения операции можно обработать полученные данные
Пример сервера, читающего из сокета строки, разделённые символом перевода строки:
#include <boost/asio.hpp>
#include <iostream>
using namespace boost::asio;
using ip::tcp;
int main() {
io_context io;
tcp::acceptor acceptor(io, tcp::endpoint(tcp::v4(), 12345));
tcp::socket socket(io);
acceptor.accept(socket);
streambuf buf;
// читаем до '\n' включительно
read_until(socket, buf, '\n');
std::istream is(&buf);
std::string line;
std::getline(is, line);
std::cout << "Received: " << line << std::endl;
return 0;
}
Таймеры в Boost
Кроме сетевых операций, Boost.Asio предоставляет таймеры для отсроченных действий. Есть два основных типа:
boost::asio::steady_timer- таймер на основе монотонных часов, которые не подвержены ручному переводу системного времени. Рекомендуется для измерения временных интерваловboost::asio::system_timer- таймер на основе системного времени. Его показания могут скакать при переводе часов или переходе на летнее/зимнее время
У обоих классов схожий набор методов:
wait- синхронно блокирует выполнение до истечения заданного времениasync_wait- асинхронное ожидание; принимает обработчик, который будет вызван, когда таймер сработаетexpires_from_now- устанавливает таймер на срабатывание через указанную длительность относительно текущего моментаexpires_at- задаёт абсолютное время срабатывания (например, конкретную временную точку)cancel- отменяет все ожидающие асинхронные операции таймера; обработчикиasync_waitбудут вызваны с кодом ошибкиoperation_aborted
Пример использования steady_timer с синхронным ожиданием:
#include <boost/asio.hpp>
#include <iostream>
using namespace boost::asio;
int main() {
io_context io;
steady_timer timer(io, chrono::seconds(3));
std::cout << "Waiting 3 seconds...\n";
timer.wait(); // блокировка на 3 секунды
std::cout << "Done.\n";
return 0;
}
Пример асинхронного таймера с async_wait:
#include <boost/asio.hpp>
#include <iostream>
using namespace boost::asio;
int main() {
io_context io;
steady_timer timer(io, chrono::seconds(2));
timer.async_wait([](boost::system::error_code ec) {
if (!ec)
std::cout << "Timer expired!\n";
else
std::cout << "Timer cancelled.\n";
});
std::cout << "Starting async wait...\n";
io.run(); // цикл обработки событий
return 0;
}
Установка таймера через expires_from_now и его последующая отмена:
#include <boost/asio.hpp>
#include <iostream>
using namespace boost::asio;
int main() {
io_context io;
steady_timer timer(io);
timer.expires_from_now(chrono::seconds(5));
timer.async_wait([](boost::system::error_code ec) {
if (ec == error::operation_aborted)
std::cout << "Cancelled.\n";
});
// через какое-то время решаем отменить
timer.cancel();
io.run();
return 0;
}
Использование expires_at для задания абсолютного времени срабатывания:
#include <boost/asio.hpp>
#include <iostream>
using namespace boost::asio;
int main() {
io_context io;
system_timer timer(io);
// сработает через 1 час от текущего системного времени
timer.expires_at(chrono::system_clock::now() + chrono::hours(1));
timer.wait();
std::cout << "One hour passed (or system time changed).\n";
return 0;
}
Лекция 5. Основные инструменты в Qt
Qt - это кросс-платформенный фреймворк на C++ для разработки графических интерфейсов и не только. Центральным классом является QObject, от которого наследуются почти все классы Qt, особенно виджеты и объекты, работающие с сигналами и слотами
QObject поддерживает иерархию родитель-потомок. Когда объект-родитель удаляется, он автоматически удаляет всех своих детей. Это позволяет строить деревья владения и не заботиться о ручном освобождении. Пример:
QObject *parent = new QObject;
QObject *child = new QObject(parent); // child принадлежит parent
delete parent; // child тоже удалится
Сигналы и слоты - основной механизм коммуникации между объектами. Сигнал объявляется в классе с ключевым словом signals, слот - с slots или как обычная функция. У слота не может быть аргументов больше, чем у сигнала, но может быть меньше: лишние аргументы сигнала просто отбрасываются. Соединение выполняется через connect
Новый стиль connect использует указатели на функции. Пример, где сигнал испускается внутри метода, а слот просто печатает значение:
class Sender : public QObject {
Q_OBJECT
public:
void doWork() {
// emit подчёркивает, что испускается сигнал
emit valueChanged(42);
}
signals:
void valueChanged(int newValue);
};
class Receiver : public QObject {
Q_OBJECT
public slots:
void onValueChanged(int val) { qDebug() << val; }
};
Sender sender;
Receiver receiver;
QObject::connect(&sender, &Sender::valueChanged,
&receiver, &Receiver::onValueChanged);
sender.doWork(); // внутри будет испущен сигнал, вызовется слот
Отсоединение выполняется методом disconnect с теми же указателями
Потоковая принадлежность: объект QObject привязан к тому потоку, в котором был создан. Сигналы и слоты могут пересекать потоки: если соединение прямое, слот выполняется в потоке отправителя; если через очередь (QueuedConnection), то вызов слота будет помещён в очередь событий потока-получателя. По умолчанию для межпоточных соединений автоматически выбирается QueuedConnection
moveToThread перемещает объект в другой поток. Объект должен быть без родителя, и его события будут обрабатываться в целевом потоке:
QThread workerThread;
workerThread.start();
Receiver receiver; // без родителя
receiver.moveToThread(&workerThread);
// Теперь receiver живёт в workerThread, его слоты будут выполняться в этом потоке
Слово emit необязательно, но служит для ясности, что вызывается сигнал (обычно его пишут непосредственно перед именем сигнала)
Динамические свойства позволяют во время выполнения добавить к QObject свойство по имени и значению, используя setProperty и property. Это удобно для стилей и анимаций
QPushButton button;
button.setProperty("urgent", true);
QVariant urgent = button.property("urgent");
События в Qt обрабатываются через виртуальный метод event(QEvent*). Обычно виджеты переопределяют конкретные обработчики: mousePressEvent, keyPressEvent и так далее. Если нужно перехватить события до их доставки к целевому объекту, используется фильтр событий. Объект-фильтр переопределяет eventFilter(QObject *watched, QEvent *event) и устанавливается через installEventFilter
class Filter : public QObject {
protected:
bool eventFilter(QObject *obj, QEvent *event) override {
if (event->type() == QEvent::KeyPress) {
// обработать или подавить
return true; // событие перехвачено
}
return QObject::eventFilter(obj, event);
}
};
// использование:
Filter filter;
targetWidget.installEventFilter(&filter);
Преобразование типов в иерархии QObject выполняется с помощью qobject_cast<Type*>(obj), что безопаснее dynamic_cast, если у класса есть макрос Q_OBJECT
Макрос Q_OBJECT обязателен в определении класса для поддержки сигналов, слотов, tr() и другой метаинформации
Фреймворк предоставляет свою реализацию потоков QThread, однако не рекомендуется наследоваться от QThread и переопределять run(). Предпочтительнее создать рабочие объекты и переместить их в QThread через moveToThread
Сборка проектов Qt обычно осуществляется с помощью CMake. Основные директивы:
find_package(Qt6 COMPONENTS Widgets REQUIRED)
qt_add_executable(my_app main.cpp)
target_link_libraries(my_app PRIVATE Qt6::Widgets)
Для проектов с QML добавляют Qt6::Quick и соответствующие модули. QML - декларативный язык для описания интерфейса. Он исполняется в QML-движке. Объекты на C++ могут быть доступны из QML через регистрацию. Пример простого QML-файла:
import QtQuick
Rectangle {
width: 200; height: 100
color: "lightblue"
Text {
anchors.centerIn: parent
text: "Hello, QML"
}
}
В CMake для QML-приложения может потребоваться qt_add_qml_module для регистрации
Лекция 6. Виджеты и локализация в Qt
В Qt все элементы графического интерфейса называются виджетами. Базовым классом для любого виджета является QWidget, от него наследуются кнопки, поля ввода, метки, контейнеры и даже окна
Любой виджет можно встроить в другой виджет, передав родителя в конструктор. Родитель же автоматически удаляет всех детей при своём разрушении
Все виджеты должны создаваться и использоваться исключительно в главном потоке приложения, вызов методов виджета из других потоков приведёт к неопределённому поведению и краху
Взаимодействовать с виджетами можно двумя основными способами:
- Сигналы и слоты - например, нажатие кнопки генерирует сигнал
clicked(), который соединяется со слотом-обработчиком - Перехват событий - можно переопределить виртуальные методы
keyPressEvent,mousePressEventи подобные или установить фильтр событий черезinstallEventFilter
Пример виджета QLineEdit - однострочное поле ввода:
QLineEdit *edit = new QLineEdit(parent);
QObject::connect(edit, &QLineEdit::returnPressed, [edit]() {
qDebug() << "Введено:" << edit->text();
});
Любое окно имеет корневой виджет или корневой макет (layout):
- Если у виджета задан макет, то все дочерние виджеты автоматически размещаются внутри него
- У каждого виджета может быть свой собственный макет, но обычно для главного окна задают вертикальный или сеточный макет
- Внутри основного виджета вложенные элементы выстраиваются в соответствии с макетом, который управляет геометрией
Упрощённо все виджеты в окне образуют дерево:
- Корень - главное окно (
QMainWindowилиQWidget) - Ствол - контейнерные виджеты, на которых установлены макеты
- Листья - кнопки, поля ввода, надписи
Кастомные виджеты создают в основном для группировки элементов и переиспользования. Они наследуются от QWidget, а в конструкторе создаются дочерние виджеты, и сразу им передается this как родителя. Например:
class MyWidget : public QWidget {
public:
explicit MyWidget(QWidget *parent = nullptr) : QWidget(parent) {
auto *layout = new QVBoxLayout(this);
layout->addWidget(new QLabel("Заголовок", this));
layout->addWidget(new QPushButton("Кнопка", this));
}
};
Для локализации используется функция tr() для перевода строк. С помощью утилит lupdate извлекаются строки, переводятся и загружаются через QTranslator
class MyWindow : public QWidget {
Q_OBJECT
public:
MyWindow() {
// будет переведено при загруженном переводе
QPushButton *button = new QPushButton(tr("Hello"), this);
}
};
Для этого Qt использует файлы локализации в формате XML (файлы .ts):
lupdateсканирует исходники и извлекает строки, обёрнутые вtr(), создавая.ts-файлы- Лингвисты переводят их, затем
lreleaseкомпилирует в компактные.qmфайлы - Qt позволяет встраивать эти файлы прямо в исполняемый файл через систему ресурсов Qt Resource System. Для этого
.qm-файлы добавляются в.qrcи загружаются из ресурсов так же, как с диска
CMake для управления переводами предоставляет команду qt_add_translations или ручную обработку
-
Пример сборки с автоматическим добавлением перевода:
find_package(Qt6 COMPONENTS Widgets LinguistTools REQUIRED) qt_add_executable(my_app main.cpp) qt_add_translations(my_app TS_FILES myapp_de.ts myapp_fr.ts QM_FILES_OUTPUT_VARIABLE qm_files ) target_link_libraries(my_app PRIVATE Qt6::Widgets) -
В коде загрузка перевода из встроенных ресурсов:
QTranslator *translator = new QTranslator(qApp); if (translator->load(":/translations/myapp_de.qm")) qApp->installTranslator(translator);
Лекция 7. Продвинутые инструменты Qt
QSS для виджетов - это способ описания внешнего вида элементов интерфейса с помощью правил, похожих на CSS. Строки стилей можно назначать конкретному виджету или всему приложению через setStyleSheet(). Это позволяет отделить оформление от логики и быстро менять тему программы
Правила QSS состоят из селектора и блока объявлений в фигурных скобках. Доступны несколько видов селекторов:
- селектор по классу -
QPushButton { background-color: red; }делает все кнопки красными - селектор по идентификатору объекта -
QPushButton#myButton { border: 2px solid blue; } - псевдосостояния -
QPushButton:hover { background-color: green; }срабатывает при наведении
Стили можно загружать из файла или задавать прямо в коде. Пример применения ко всему приложению:
qApp->setStyleSheet(
"QPushButton { background-color: red; color: white; }"
"QPushButton:hover { background-color: green; }"
);
Пользовательская графика в Qt реализуется через переопределение метода paintEvent и использование класса QPainter. Любой наследник QWidget может рисовать на своей поверхности. Система вызывает paintEvent тогда, когда виджету требуется перерисовка
Внутри paintEvent создаётся объект QPainter painter(this), который предоставляет инструменты для рисования геометрических фигур, текста и изображений:
drawLine(),drawRect(),drawEllipse()- базовые примитивыdrawText()- вывод текстаdrawPixmap()- отрисовка готового растрового изображения
Внешний вид линий и заливок настраивается отдельными объектами. QPen отвечает за контур: цвет, толщина, стиль (сплошной, пунктир, штрихпунктир). QBrush управляет заливкой: можно задать сплошной цвет, градиент или повторяющуюся текстуру. Чтобы заставить виджет перерисоваться, достаточно вызвать update() - он запланирует новый вызов paintEvent. Рисовать можно не только на виджете, но и на любом устройстве вывода из иерархии QPaintDevice, например на QImage или QPixmap:
class MyWidget : public QWidget {
protected:
void paintEvent(QPaintEvent *) override {
QPainter painter(this);
painter.setRenderHint(QPainter::Antialiasing);
QPen pen(Qt::blue, 3);
painter.setPen(pen);
painter.setBrush(Qt::yellow);
painter.drawEllipse(50, 50, 100, 60);
}
};
Фильтр событий - это механизм, позволяющий перехватывать события любого QObject без создания подкласса. Он даёт возможность централизованно обрабатывать события, например, для нескольких однотипных виджетов. Установка фильтра выполняется вызовом target->installEventFilter(this), где this - объект-наблюдатель
Объект-наблюдатель обязан переопределить метод eventFilter(QObject *watched, QEvent *event). Если фильтр возвращает true, событие считается обработанным и не передаётся целевому объекту. Возврат false направляет событие обычным путём - оно попадёт в метод event() целевого виджета
Типичный пример использования - ограничение ввода. Создаётся класс-фильтр, который перехватывает события нажатия клавиш, анализирует вводимый символ и, если тот не соответствует условию (например, не является цифрой), возвращает true, подавляя событие. В противном случае событие пропускается к полю ввода
class DigitFilter : public QObject {
protected:
bool eventFilter(QObject *obj, QEvent *event) override {
if (event->type() == QEvent::KeyPress) {
QKeyEvent *key = static_cast<QKeyEvent*>(event);
if (!key->text().isEmpty() && !key->text().at(0).isDigit())
return true; // событие подавлено
}
return false;
}
};
// Установка фильтра
QLineEdit *edit = new QLineEdit;
DigitFilter *filter = new DigitFilter;
edit->installEventFilter(filter);
Разделение памяти между потоками
Истинное разделение (True sharing) - это ситуация, когда несколько ядер процессора интенсивно читают и/или пишут в одну и ту же кэш-линию из-за доступа к одной и той же переменной. Это вызывает постоянную синхронизацию кэшей по протоколу когерентности, что резко снижает производительность, даже если доступ к переменной защищён мьютексом или она атомарна
Например: два потока увеличивают общий счётчик int counter. Каждый делает 1000 итераций counter++. Из-за того, что счётчик находится в одной кэш-линии, ядра будут постоянно обмениваться этой линией, и в результате время выполнения может быть в десятки раз больше, чем если бы каждый поток работал со своей локальной переменной
Чтобы бороться с истинным разделением, можно:
- Использовать локальные для потока данные (например, с помощью ключевого слова
thread_local) и периодически объединять их - Распределять счётчики по разным линиям
Ложное разделение (False sharing) - это скрытая проблема производительности, когда потоки формально работают с разными переменными, но те попадают в одну кэш-линию процессора. Размер кэш-линии обычно составляет 64 байта. Когда один поток пишет в свою переменную, вся линия помечается изменённой, и другие ядра вынуждены загружать её заново, даже если их собственные данные не менялись. В результате возникает лишний трафик памяти и промахи кэша, замедляющие многопоточную программу
Представьте структуру с двумя счётчиками int a и int b, расположенными рядом. Поток 1 меняет только a, поток 2 - только b. Настоящего конфликта нет, но из-за близкого расположения переменные делят одну кэш-линию. Постоянная синхронизация линии между кэшами ядер приводит к падению производительности. Решением служит разнесение переменных по разным линиям с помощью выравнивания или отступов. Например, можно пометить поля ключевым словом alignas(64) или вставить массив-заполнитель char padding[64] между a и b. Тогда каждая переменная окажется в собственной кэш-линии, и потоки перестанут мешать друг другу
struct Counters {
alignas(64) int a;
alignas(64) int b;
};
Counters cnt;
// Поток 1: cnt.a, Поток 2: cnt.b - false sharing исключён
Лекция 8. Упорядочивания в std::atomic и барьеры памяти
По умолчанию все операции над std::atomic в C++ выполняются с упорядочением memory_order_seq_cst. Это самый строгий и понятный режим: все потоки видят атомарные операции в едином глобальном порядке, как будто они выполняются строго одна за другой. Такой подход гарантирует наименьшее количество сюрпризов, но может ограничивать производительность из-за дополнительных барьеров памяти на аппаратном уровне
Всего режимов 4:
-
memory_order_relaxed- минимальный уровень гарантий. Операция остаётся атомарной, но не создаёт никаких синхронизационных барьеров. Компилятор и процессор могут свободно переупорядочивать окружающие инструкции, не связанные с этой атомарной переменной. Такой режим подходит для счётчиков, где важен только конечный результат, а не момент наблюдения из другого потока, и где не передаётся информация о других участках памяти между потокамиПример счётчика посещений, где не требуется мгновенная видимость:
std::atomic<int> visits{0}; void increment_visit() { visits.fetch_add(1, std::memory_order_relaxed); } -
memory_order_acquireиспользуется при чтении атомарной переменной. Он гарантирует, что все последующие операции с памятью (не только атомарной) не будут переставлены компилятором или процессором до этой точки чтения. Это создаёт барьер “снизу”: послеacquireнельзя поднять более ранние чтения/записи выше негоТакой режим применяется, когда поток должен увидеть все изменения, сделанные другим потоком до соответствующей
release-записи, например:std::atomic<bool> ready{false}; int data = 0; // Поток 1 data = 42; ready.store(true, std::memory_order_release); // Поток 2 while (!ready.load(std::memory_order_acquire)); // Здесь data гарантированно равно 42 -
memory_order_releaseиспользуется при записи. Он гарантирует, что все предыдущие операции с памятью не будут переставлены после этой точки записи. Это барьер “сверху”:releaseне даёт опустить более поздние инструкции ниже себяТакой режим вместе с acquire образует пару синхронизации: если поток, выполнивший
release, записывает значение, а другой поток то же значение читает через acquire, то все записи передreleaseстановятся видимыми читающему потокуstd::atomic<bool> flag{false}; std::string message; // Поток-публикатор message = "Hello"; flag.store(true, std::memory_order_release); // Поток-потребитель if (flag.load(std::memory_order_acquire)) { // message гарантированно содержит "Hello" } -
memory_order_seq_cstсочетает свойстваacquireиrelease, но добавляет требование единого глобального порядка всехseq_cst-операций. Это значит, что все потоки согласны на одну и ту же последовательностьseq_cst-событий, даже если они не связаны явными отношениями синхронизации. В большинстве случаев это поведение соответствует интуитивным ожиданиям, но может быть дороже из-за полных барьеров памятиПример, где
seq_cstдаёт предсказуемый результат даже при неочевидных перестановках:std::atomic<bool> x{false}, y{false}; std::atomic<int> z{0}; // Поток 1 x.store(true, std::memory_order_seq_cst); // Поток 2 y.store(true, std::memory_order_seq_cst); // Поток 3 while (!x.load(std::memory_order_seq_cst)); if (y.load(std::memory_order_seq_cst)) ++z; // Поток 4 while (!y.load(std::memory_order_seq_cst)); if (x.load(std::memory_order_seq_cst)) ++z; // z никогда не будет 0, порядок записи x и y однозначен для всех
Барьеры памяти в C++ представлены функцией std::atomic_thread_fence. В отличие от упорядочения, привязанного к конкретной атомарной переменной, барьер действует как самостоятельная инструкция синхронизации для текущего потока. Есть два режима работы:
std::atomic_thread_fence(std::memory_order_acquire)- все чтения после барьера не поднимутся выше негоstd::atomic_thread_fence(std::memory_order_release)- все записи до барьера не опустятся ниже него
Барьеры полезны, когда синхронизация должна охватить несколько переменных или когда переменная не объявлена атомарной, но доступ к ней защищён отдельным флагом
Пример с флагом, где данные не атомарны, но защищены барьером:
bool ready = false;
int data = 0;
// Поток 1
data = 42;
std::atomic_thread_fence(std::memory_order_release);
ready = true;
// Поток 2
if (ready) {
std::atomic_thread_fence(std::memory_order_acquire);
int v = data; // гарантированно 42
}
SPSC-очередь (Single Producer Single Consumer) - это свободная от блокировок структура данных для передачи сообщений между двумя потоками, где один только пишет, а второй только читает. Она строится на кольцевом буфере фиксированного размера и двух атомарных индексах: head (потребитель) и tail (производитель). Каждый поток модифицирует только свой индекс, поэтому для них достаточно memory_order_relaxed, но передача полезных данных требует синхронизации acquire-release
Производитель:
- помещает элемент, записывает данные в ячейку по индексу
tail - затем сдвигает
tailвперёд сmemory_order_release, чтобы потребитель увидел готовность данных
Потребитель:
- считывает
tailсmemory_order_acquire, чтобы увидеть все произведённые записи до текущего момента - берёт данные из ячейки
head - затем сдвигает
headсmemory_order_relaxed(очистка места не требует синхронизации с производителем, кроме случая, когда буфер пуст)
Пример минимальной реализации на массиве:
template<typename T, size_t N>
class SPSCQueue {
std::array<T, N> buffer;
std::atomic<size_t> head{0}, tail{0};
public:
bool push(const T& item) {
size_t t = tail.load(std::memory_order_relaxed);
size_t next = (t + 1) % N;
if (next == head.load(std::memory_order_acquire)) return false; // буфер полон
buffer[t] = item;
tail.store(next, std::memory_order_release);
return true;
}
bool pop(T& item) {
size_t h = head.load(std::memory_order_relaxed);
if (h == tail.load(std::memory_order_acquire)) return false; // буфер пуст
item = buffer[h];
head.store((h + 1) % N, std::memory_order_relaxed);
return true;
}
};
В этом коде проверка на пустоту/полноту и перемещение индексов используют минимально необходимые барьеры: acquire для чтения чужого индекса, release для публикации обновлённого индекса, relaxed для собственного индекса. Такой дизайн обеспечивает корректную синхронизацию данных без лишних накладных расходов
Лекция 9. Другие оптимизации в C++
Выравнивание данных в структурах влияет на их размер и скорость доступа к полям. Компилятор вставляет пустые байты (то есть делает выравнивание, padding) между полями или в конце, чтобы адреса полей были кратны их размеру. Это ускоряет чтение, но может увеличить общий размер структуры
Оптимизация - перестановка полей так, чтобы уменьшить количество выравнивающих пропусков. Самые большие типы стоит размещать первыми, затем средние, в конце самые маленькие
Пример плохо выровненной структуры и оптимизированной:
struct Bad {
char a; // 1 байт + 3 байта для выравнивания
int b; // 4 байта
char c; // 1 байт + 1 байт для выравнивания
short d; // 2 байта
};
// sizeof(Bad) = 12
// Оптимизированная перестановка
struct Good {
int b; // 4 байта
short d; // 2 байта
char a; // 1 байт
char c; // 1 байт
};
// sizeof(Good) = 8
Разница возникла из-за того, что int (4 байта) выровнен на границу 4, short (2 байта) на границу 2, char может быть по любому адресу. Правильный порядок убирает лишние пропуски
Ещё одна важная оптимизация - использование порядка обхода данных, дружественного к кэшу процессора. Процессор загружает данные из оперативной памяти блоками (кэш-линиями, обычно 64 байта). Если программа обращается к памяти не последовательно, а с большими шагами, происходят кэш-промахи - данные не находятся в быстрой кэш-памяти, и приходится ждать загрузки из медленной оперативной памяти. Это сильно снижает производительность
Классический пример промахов в кэш - умножение матриц при неправильном порядке циклов. Допустим, матрицы хранятся в памяти построчно, рассмотрим два варианта перемножения C = A * B:
Первый вариант - традиционный i-j-k:
for (int i = 0; i < N; ++i)
for (int j = 0; j < N; ++j)
for (int k = 0; k < N; ++k)
C[i][j] += A[i][k] * B[k][j];
Здесь обращение к B происходит по столбцам: B[k][j] меняет k быстрее всего, а значит перебор идёт с шагом N элементов между соседними k. При большом N каждая итерация k скорее всего вызывает кэш-промах при доступе к B, потому что следующая строка k+1 находится далеко в памяти. Это очень медленно
Оптимизированный порядок - i-k-j:
for (int i = 0; i < N; ++i)
for (int k = 0; k < N; ++k)
for (int j = 0; j < N; ++j)
C[i][j] += A[i][k] * B[k][j];
Здесь внутренний цикл идёт по j, что даёт последовательное чтение строки B[k] и обновление строки C[i]. Промахи кэша на B практически исчезают, а обращения к A[i][k] - константа на всю внутреннюю петлю, которая остаётся в регистре. Производительность может отличаться в несколько раз
На небольших размерах разница не так заметна, но при N=1000 время выполнения может уменьшиться с секунд до десятых долей секунды
Можно использовать директиву #pragma pack(1) для плотной упаковки, но это может замедлить доступ, потому что поля перестают быть выровненными на естественные границы. Обычно лучше оставить естественное выравнивание и переставить поля
Вот пример, показывающий влияние перестановки полей на размер:
struct A {
char x; // 1 байт + 7 байт выравнивание
double y; // 8 байт
char z; // 1 байт
// + 7 байт в конце для выравнивания
};
// sizeof(A) = 24
struct B {
double y; // 8 байт
char x; // 1 байт
char z; // 1 байт
// + 6 байт в конце для выравнивание
};
// sizeof(B) = 16
Использование ключевого слова alignas или __attribute__((aligned)) может принудительно менять выравнивание, но это нужно для особых случаев, например, для SSE/AVX инструкций, где данные должны быть выровнены на 16 или 32 байта
Разберём два способа организации коллекции объектов в памяти: массив структур (AoS, Array of Structures) и структура массивов (SoA, Structure of Arrays). Оба подхода влияют на производительность из-за особенностей работы кэша и векторных инструкций
Массив структур заключается в объявлении структуры, содержащей все поля объекта, и массива таких структур. Все данные одного объекта лежат рядом в памяти
struct Particle {
float x, y, z;
float vx, vy, vz;
int health;
};
Particle particles[1000];
Когда процессор загружает в кэш одну частицу, в кэш-линию попадают сразу все её поля: координаты, скорости, здоровье. Это отлично подходит, если программа обрабатывает частицу целиком. Но если нужно часто обновлять только координату x всех частиц, то вместе с x в кэш загружаются и y, z, vx, vy, vz, health, которые сейчас не нужны. Кэш забивается бесполезными данными, полезных данных помещается меньше, чаще происходят промахи
Структура массивов меняет представление: каждое поле объекта хранится в отдельном массиве. Все частицы по-прежнему существуют как единое целое, но физически разнесены
struct Particles {
float x[1000];
float y[1000];
float z[1000];
float vx[1000];
float vy[1000];
float vz[1000];
int health[1000];
};
Теперь при обходе x для всех частиц процессор загружает только массив x, и каждая кэш-линия целиком заполнена нужными координатами. Промахов становится значительно меньше, данные используются максимально эффективно
Важные различия и когда что применять:
- Массив структур удобнее читать и писать в коде:
particles[i].x = 5.0fвыглядит естественно. Подходит для ситуаций, когда объекты обрабатываются целиком (сериализация, создание и удаление) - Структура массивов дружелюбнее к кэшу при массовых операциях над одним полем и обязательна для эффективной векторизации SIMD. Компилятор может загружать четыре
xодновременно в SSE-регистр, потому что они лежат подряд - Если у объектов есть логическая связность, которая требует частого доступа к разным полям одного объекта, массив структур может выиграть, потому что все поля загружаются вместе. Например, физика: обновление позиции через скорость часто требует
x += vx * dt,y += vy * dtодновременно, и массив структур даст локальность - Когда число полей велико и они редко используются вместе, структура массивов экономит пропускную способность памяти и снижает промахи
- Гибридный подход: можно сгруппировать связанные поля в мини-структуры и сделать массив таких структур (например,
struct Vec3 { float x,y,z; }; Vec3 pos[N]; Vec3 vel[N];), частично совмещая преимущества