itmo_conspects
Лекция 14. Свёрточные и рекуррентные нейросети
Свёрточная нейросеть
Не все данные эффективно хранить в табличной форме, например, картинки. Отличить кошечку от собачки по одному пикселю на картинке невозможно, поэтому нужно знать контекст - соседние пиксели на картинке
Допустим есть изображение шириной $W$ пикселей, высотой $H$ пикселей и имеет $C$ слоев (например, слой красного, зеленого и синего). Тогда для обычной нейросети потребуется $H \cdot W \cdot C$ входных нейронов, а на следующем слое будет $(H \cdot W \cdot C)^2$ параметров. Такой подход не только замедляет обучение, так еще и не учитывает структуру изображения и трансформации, такие как сдвиги и повороты
Для этого применили подход из фильтров для изображений. Фильтр представляет из себя матрицу множителей, на которые умножаются значения соседних пикселей, в сумме давая результат для исходного:
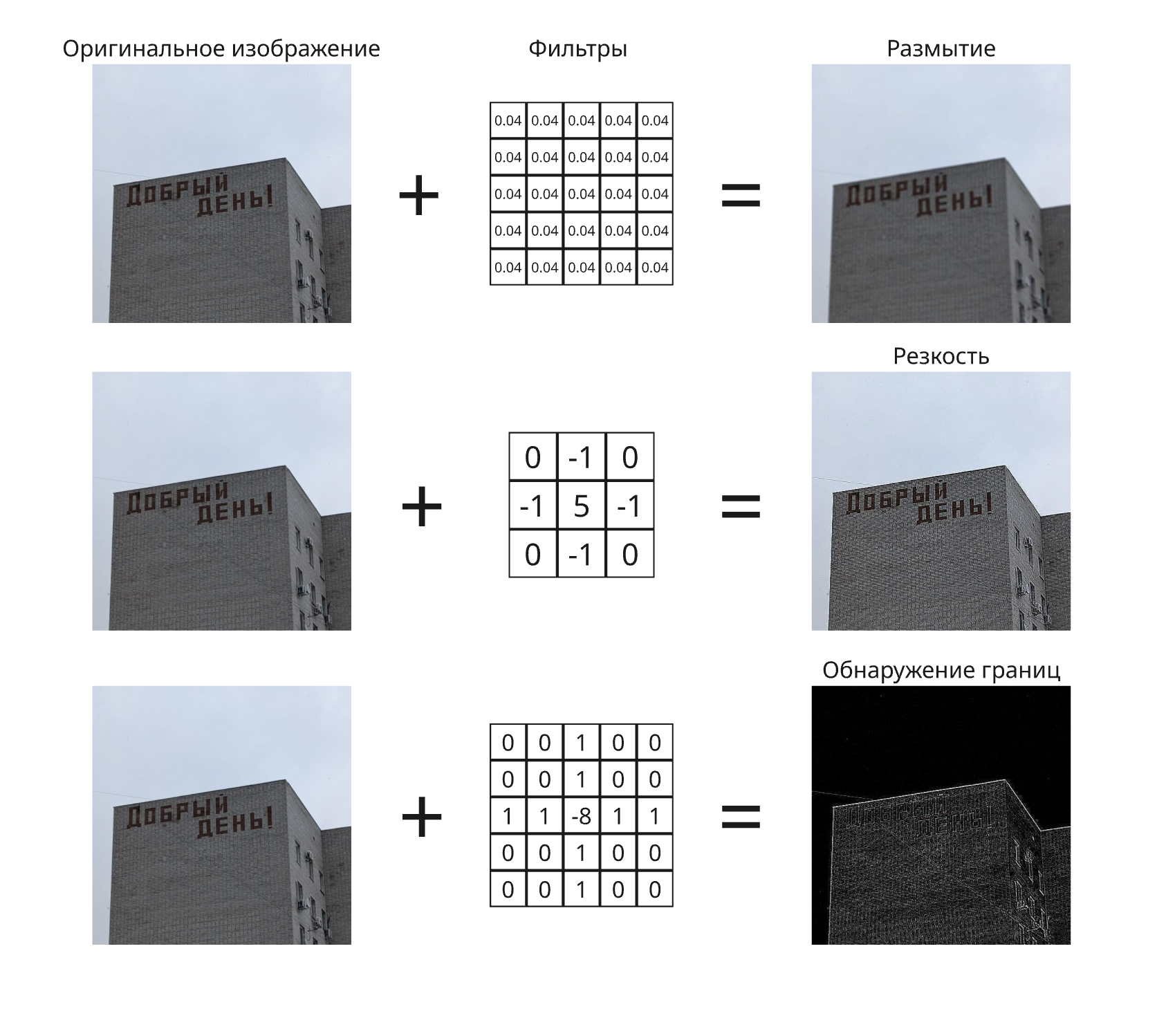
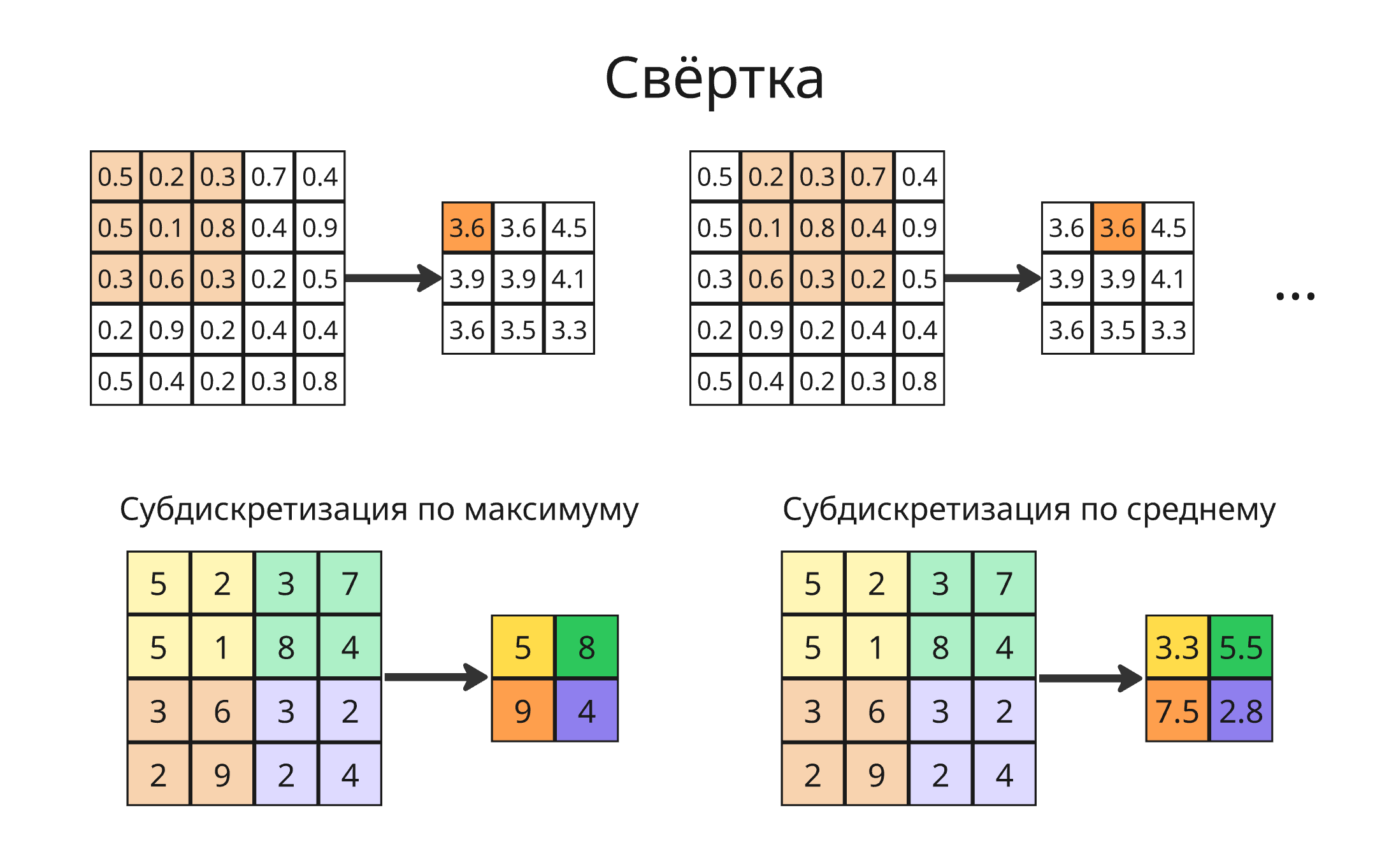
Если множители матрицы сделать обучаемыми параметрами, то после субдискретизации (то есть уплотнения, что делает изображение меньшей размерности) можно уменьшить число нейронов и свести задачу к обычной нейросети. Так получается свёрточная нейросеть (Convolutional Neural Network, CNN)
Первой свёрточной нейронной сетью была LeNet, созданная в конце 1980-ых Яном Лекуном, которая распознавала рукописные цифры. Самая известная версия LeNet-5 вышла в 1998 году и работала так:
- Исходное изображение состояло из $32 \times 32$ пикселей, каждый из которых был оттенком серого
-
Первый слой состоял из свертки - 6 фильтров $5 \times 5$. Такие фильтры называют ядрами свертки. На выходе получалось 6 новых изображений $28 \times 28$, к каждому из которых добавлялось смещение, что дает 156 параметров
-
Второй слой состоял из субдискретизации. Субдикретизация (или пулинг, pooling) состояла из операции усреднения значений пикселей в квадрате $2 \times 2$ (average pooling), что уменьшало высоту и ширину изображения вдвое
Вместо усреднения обычно берут максимум из значений (max pooling). Субдискретизация уменьшает размер и добавляет небольшую устойчивость к сдвигам
-
Третий слой состоял из свертки - 60 ядер $5 \times 5$. Вместе они использовались в свертке тензора $6 \times 14 \times 14$ в тензор $16 \times 10 \times 10$, причем не каждый входной слой участвовал в вычислении выходного
-
Четвертый слой - аналогичная субдискретизация в $16 \times 5 \times 5$
-
Пятый слой - свертка из 120 фильтров $16 \times 5 \times 5$ в вектор размером 120
-
Шестой слой - 84 нейронов, полностью соединенных с предыдущими 120
- Седьмой слой - последние 10 нейронов, полностью соединенных с 84
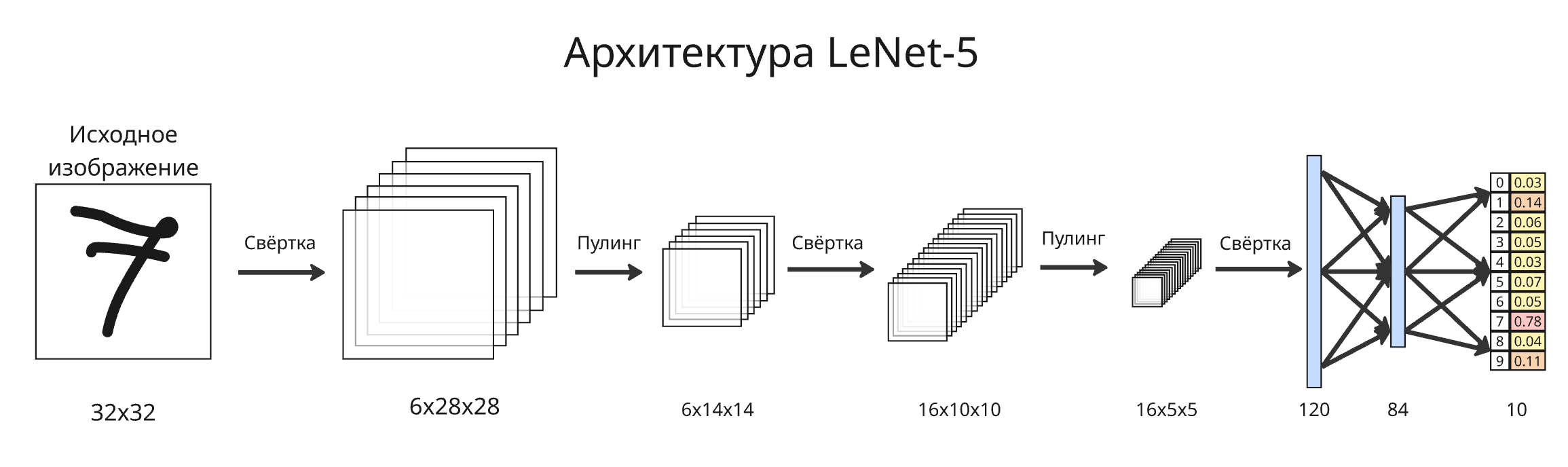
Последние 10 нейронов обозначают вероятность принадлежности картинки к какому-либо классу цифр
Свертка может быть не только из матрицы, но и как массив высокой размерности. Обычно слои могут выстраивать иерархию признаков, например, первые слои обнаруживать простые паттерны, градиенты, края, а глубокие такие формы, как глаза, колесо и другие
Как можно заметить, свертка уменьшает размеры изображения. Если такой эффект нежелателен, то добавляют отступ (padding) от границы изображения перед применением свертки. Используют:
- Заполнение нулями
- Расширение границы - в отступах используются те же значения, что и пограничные
- Зеркальный сдвиг - отступы являются зеркальным отображением значений у границы
- Циклический сдвиг - отступом от границы являются значения с противоположной границы, таким образом зацикливая изображение
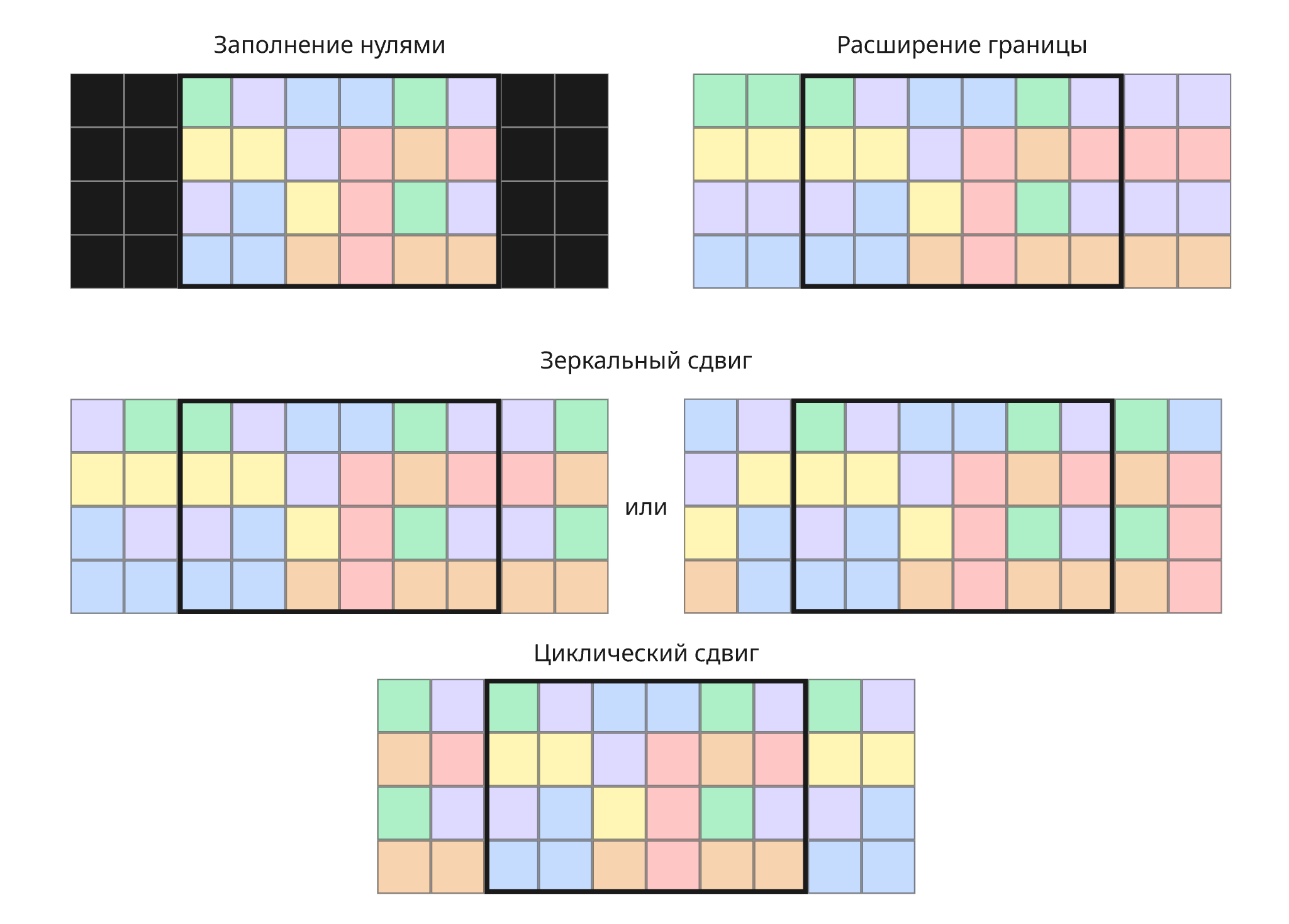
Отступ позволяет учитывать информацию на границах и строить глубокие сверточные нейросети без потери разрешения
Наоборот, для уменьшения размера матрицы используют увеличенный шаг (stride), через который применяется ядро свертки. Помимо уменьшения размера выходного тензора снижаются число весов, пространственная нагрузка и добавляется устойчивость к небольшим сдвигам
Сверточные нейросети используются в компьютерном зрении (классификация изображений, обнаружение объектов, распознавание лиц, эмоций, обработка медицинских изображений и так далее), в анализе временных рядов (например, аудио), генетике, рекомендательных системах и в обработке текстов на естественном языке
Обработка естественного языка
Обработка естественного языка (Natural Language Processing, NLP) - раздел машинного обучения, который изучает анализ и синтез текстов на языках, на которых пишет человек
Допустим у нас есть текст. Простым подходом в его анализе будет подсчет количества слов, входящих в текст, такой подход называется мешком слов (bag-of-words). Мешок слов не учитывает порядок слов и структуру и обычно используется для классификации текстов
Проблему игнорирования контекста решает непрерывный мешок со словами (continuous bag-of-words). В нем каждое слово из словаря представлено вектором (например, с помощью унитарного кода), далее нейросеть, имеющая один скрытый слой, принимает сумму векторов соседних слов на вход и выдает вероятностное распределение слов. Цель - максимизировать лог-вероятность $\sum_i \ln P(w_i \ \vert \ w_{i + j} \ : \ j \in N)$, где $N$ - это множество смещений относительно центрального слова, которое нужно предсказать, например, $N = {-2, -1, 1, 2}$
В другом подходе, Skip-gram, слова также представлены векторами, но вместо предсказывания центрального слова по его контексту задача состоит в том, что найти контекст по заданному слову. Здесь цель - максимизировать функцию $\sum_i \sum_{j \in N} \ln P(w_{i + j} \ \vert \ w_i)$
Когда нейросеть натренирована, получаются матрицы весов $V$ и $V^\prime$, чью столбцы и строки соответственно могут использоваться в качестве словаря
Подобные подходы используются в технике Word2vec для преобразования слов в вектора, которые хранят информацию о слове на основании окружающих слов. Далее, например, можно найти синонимы для данного слова или предлагать дополнительные слова. Слова, появляющиеся в схожих контекстах, отображены в вектора со схожим косинусным расстоянием
Рекуррентная нейросеть
Далее результаты метода Word2vec применялись для создания рекуррентных нейронных сетей
Рекуррентная нейронная сеть (Recurrent neural network, RNN) - нейросеть, где связи между элементами образуют последовательность. Благодаря этому появляется возможность обрабатывать события во времени
Каждый нейрон помимо своих весов хранит скрытое состояние, которое участвует в вычислении значения для следующего ввода. Работает это так:
- Вычисляется произведение $W_i x^{(t)}$, где $W_i$ - веса $i$-ого нейрона, а $x_t$ - $t$-ый входной вектор
- К этому произведению добавляется смещение $b_i$ и взвешенное предыдущего результата $w_i y^{(t - 1)}_i$: $W_i x^{(t)} + b_i + w_i y^{(t - 1)}_i$
- Применяется функция активации, например, ReLU: $y^{(t)}_i = \mathrm{ReLU}(W_i x^{(t)} + b_i + w_i y^{(t - 1)}_i)$
- Значение $y^{(t)}_i$ используется в следующем слое и для вычислении следующего значения этого нейрона
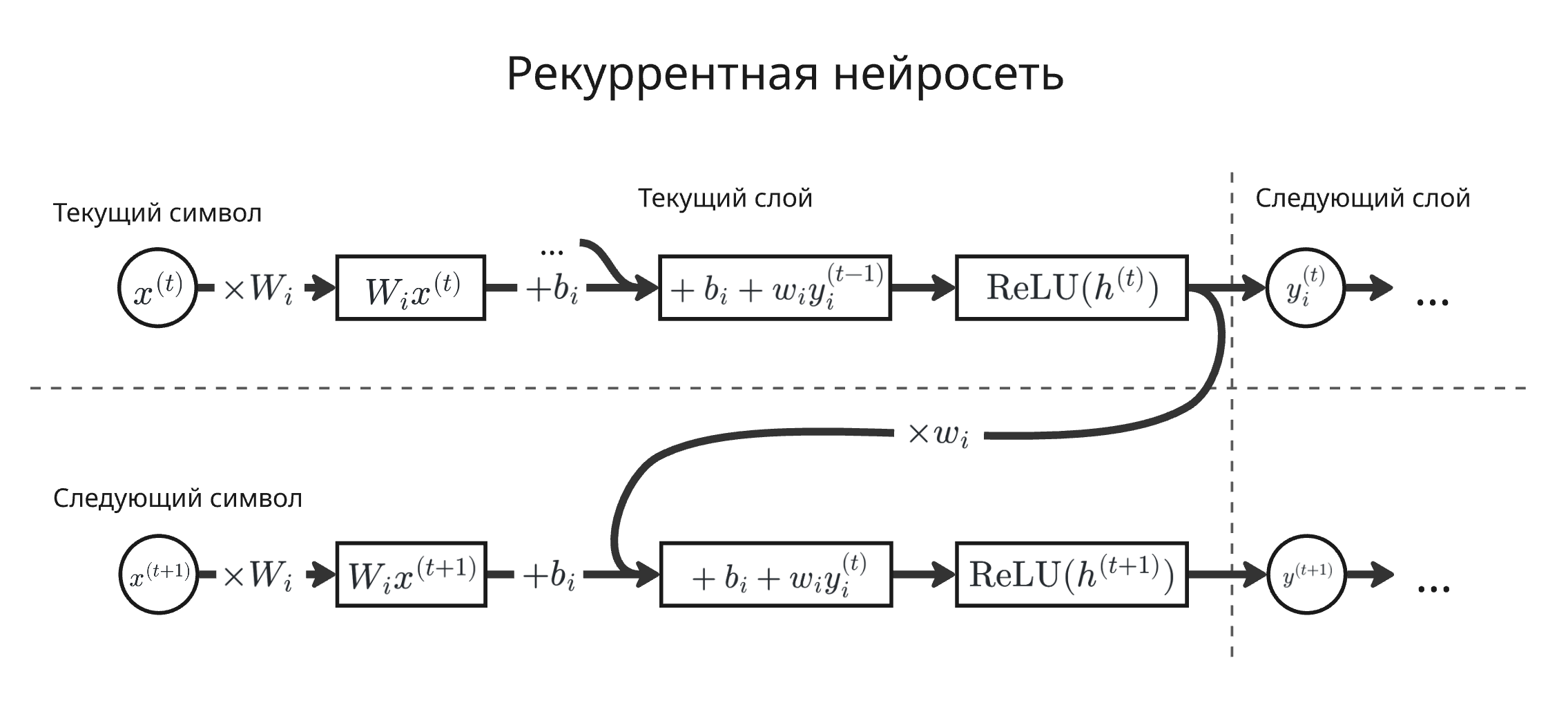
Как можно заметить, рекуррентная нейросеть позволяет обрабатывать последовательность произвольный длины, а в вычислении используются одни и те же веса. Из-за этого возникают проблемы:
- затухающего или взрывающегося градиента - вес $w_i$ может быть либо близок к нулю, либо очень большим, что делает выход нейрона очень незначительным или очень влияющим
- сложно учитывать дальние зависимости
- последовательная обработка приводит к медленному обучению
- плохо масштабируется на длинные последовательности
Помимо предсказывания следующего слова в тексте (такие модели называются языковыми) рекуррентные нейросети способны предсказывать другие временные последовательности: цену акций или следующий семпл в мелодии
Помимо обычной рекуррентной нейросети существуют модификации:
-
Двунаправленная рекуррентная нейросеть (Bidirectional RNN)
Две независимые рекуррентные нейросети используются для обработки одной последовательности, только одна проходит последовательность в прямом порядке, а другая - в обратном. Результатом является конкатенация скрытых состояний двух нейронов
Существуют задачи, в которых важно знать не только предыдущий ввод, но и последующий, например, распознавание речи, машинный перевод или анализ тональности
-
Многослойная рекуррентная нейросеть (Multilayer RNN)
Многослойные рекуррентные нейросети позволяют определять сложные зависимости, однако требует больше мощностей
LSTM
Long Short-Term Memory (LSTM, Долгая краткосрочная память) - архитектура рекуррентных нейронных сетей, предложенная в 1997 году Зеппом Хохрайтером и Юргеном Шмидхубером
LSTM решает проблемы обычные рекуррентных нейросетей путем добавления состояния ячейки в нейроны. Состояние ячейки $c_t$ играет роль долгосрочной памяти, а скрытое состояние $h_t$ - краткосрочной. Далее вычисление значения нейрона делится на три этапа
-
Вентиль забывания (forget gate): $\hat c_t = c_{t - i} \cdot \sigma(W_f h_{t - 1} + U_f x_t + b_f)$
Значение $\sigma(W_f h_{t - 1} + U_f x_t + b_f)$ определяет, какой процент состояния ячейки нужно запомнить
-
Входной вентиль (input gate): $c_t = \hat c_t + \sigma(W_i h_{t - 1} + U_i x_t + b_i) \cdot \mathrm{tanh}(W_c h_{t - 1} + U_c x_t + b_c)$
Здесь решается, какую долю входного значения и скрытого состояния нужно запомнить
-
Выходной вентиль (output gate): $h_t = \mathrm{tanh}(c_t) \cdot \sigma(W_o h_{t - 1} + U_o x_t + b_o)$
Значение $h_t$ передается на следующий слой нейронов или как вывод
Здесь $W_f$, $U_f$, $W_i$, $U_i$, $W_c$, $U_c$, $W_o$ и $U_o$ - вектора весов, а $b_f$, $b_i$, $b_c$ и $b_o$ - смещения. Через их обучение сеть начинает понимать, какие данные запоминать, а какие забывать
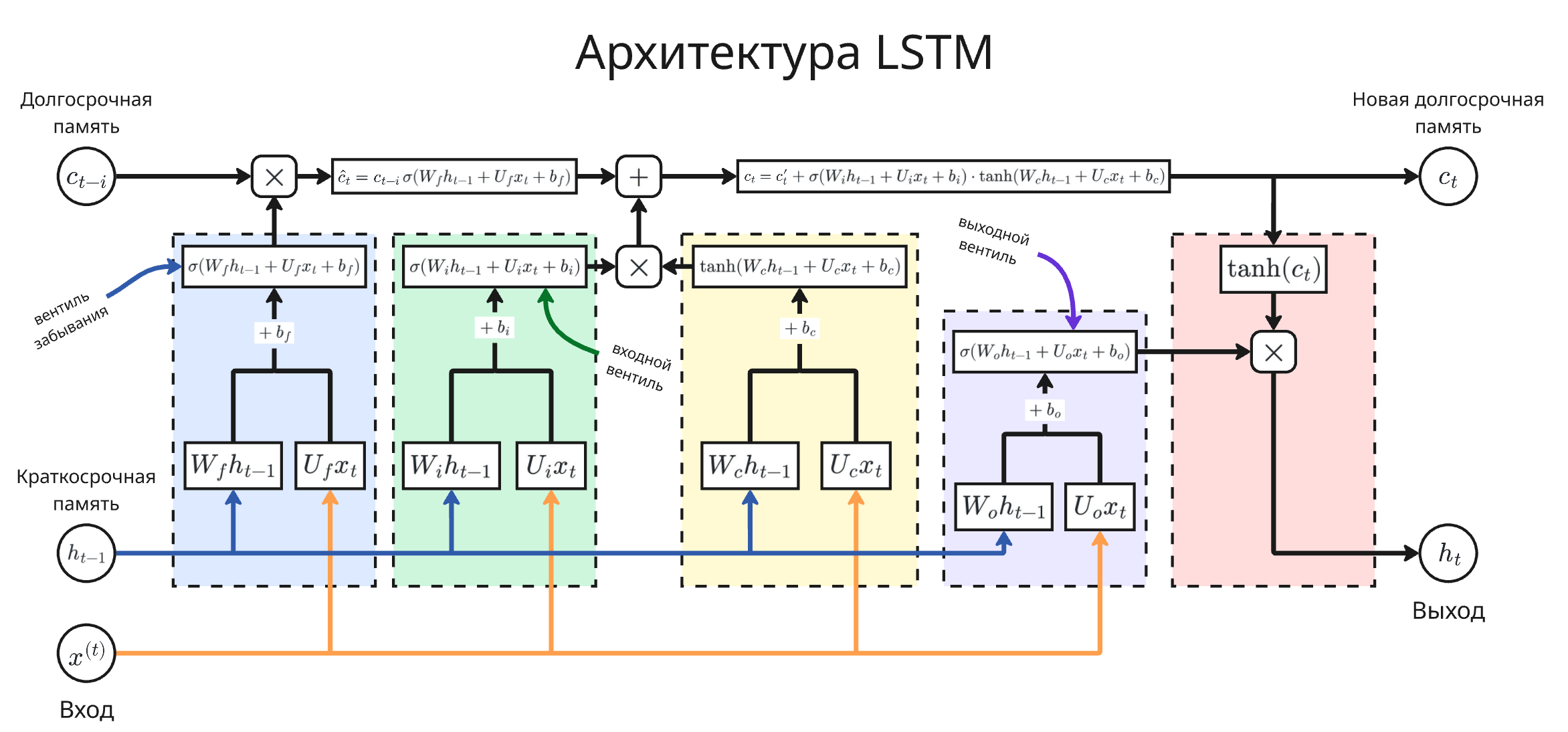
Состояние ячейки $c_t$ обновляется через сложение, что решает проблему взрывающихся и затухающих градиентов. А разделение памяти на долгосрочную и краткосрочную дает большую гибкость
Количество вентилей и другие детали архитектуры могут быть сложнее
В основе LSTM построена архитектура Seq2seq. Она была предложена как решение преобразования одной последовательности в последовательность другой длины (например, для перевода или суммаризации текста)
Для этого одна нейросеть, кодировщик, обрабатывает последовательность. После этого набор скрытых состояний нейронов используется как вектор контекста. Далее другая нейросеть, декодировщик, преобразует этот вектор в выходную последовательность.
Здесь возникает проблема бутылочного горлышка: один вектор контекста не может полностью представить значение очень длинного текста
Для решения этого ограничения был придуман механизм внимания, описанный в знаменитой статье “Attention Is All You Need” (тык). В этом механизме на каждом шаге декодировщика вычисляются веса внимания на основе сравнения текущего состояния декодировщика со всеми состояниями кодировщика. Веса внимания показывают, насколько входное слово важно для генерации выходного. Далее вычисляется взвешенная сумма скрытых состояний кодировщика, которая является контекстным вектором декодировщика для этого шага