itmo_conspects
Технологии программирования на Java
- Технологии программирования на Java
Этот курс будет про работу с языком Java (JVM, ООП на Java), с базами данных, со средствами сборки и тестирования, с микросервисами
Первый модуль будет посвящен изучению Java (дополнительно можно ознакомиться на сайте Георгия Корнеева), второй модуль - Spring и микросервисам
Презентации лекций доступны здесь - https://xrem.github.io/tech/
Лекция 1
До этого появления Java существовали большие компьютеры, кушающие перфокарты; далее появились такие древние языки, как FORTRAN, BASIC и другие
Основной недостаток: ни один из представленных в те времена ЯП не мог удовлетворить одновременно всем критериям:
- простота использования
- предоставляемые возможности
- безопасность
- эффективность
- устойчивость
- расширяемость
Первый таким языком стал C - он был создан для работяг, тогда как более старые языки были созданы в академических целях
Потом появился C++, объединивший в себе ООП, однако C++ - платформо-зависимый язык
К 90-ым годам с распространением компьютеров появились разные платформы. С этим появилась концепция превращения кода в промежуточную стадию, которую можно запускать на процессорах разных архитектур. Ввели термины managed code (управляемый код) и unmanaged code (неуправляемый код). Управляемый код управляется средой выполнения - виртуальной машиной.
В Java код переводится в байт-код, который транслируется в машинные инструкции при помощи Java Virtual Machine (JVM). При этом понимание Java-программисту устройства виртуальной машины также не нужно, как и понимание устройства компилятора C-программисту (*тык*)
Java Runtime Environment (JRE) - среда выполнения для Java, которая содержит библиотеки классов, загрузчик классов и т. д.
Java Development Kit (JDK) - средства, позволяющие разрабатывать на Java
JVM состоит из:
-
спецификации - набором правил, диктующих, как должна быть реализована JVM. “JVM должна правильно запускать программы, написанные на Java”
-
реализации - реальной программы, которая будет запускать и позволять разрабатывать программы, написанные на Java
-
экземпляра - оболочки над вашим кодом, которая его исполняет и заботится о том, как она это делает
Пример кода на Java:
package ru.butenko.springdatatest; // название пакета
import java.time.LocalDate;
public class Dog {
public String name;
private LocalDate birthdate;
public int calculateAge() {
return LocalDate.now().getYear() - this.birthdate.getYear();
}
}
В названии пакета отражается название организации (или индивидуального человека), название проекта и файловая структура проекта
При компиляции класс из файла .java переводится в байт-код .class
Также в Java есть примитивные коллекции, например, Queue, Deque и другие (*тык*)
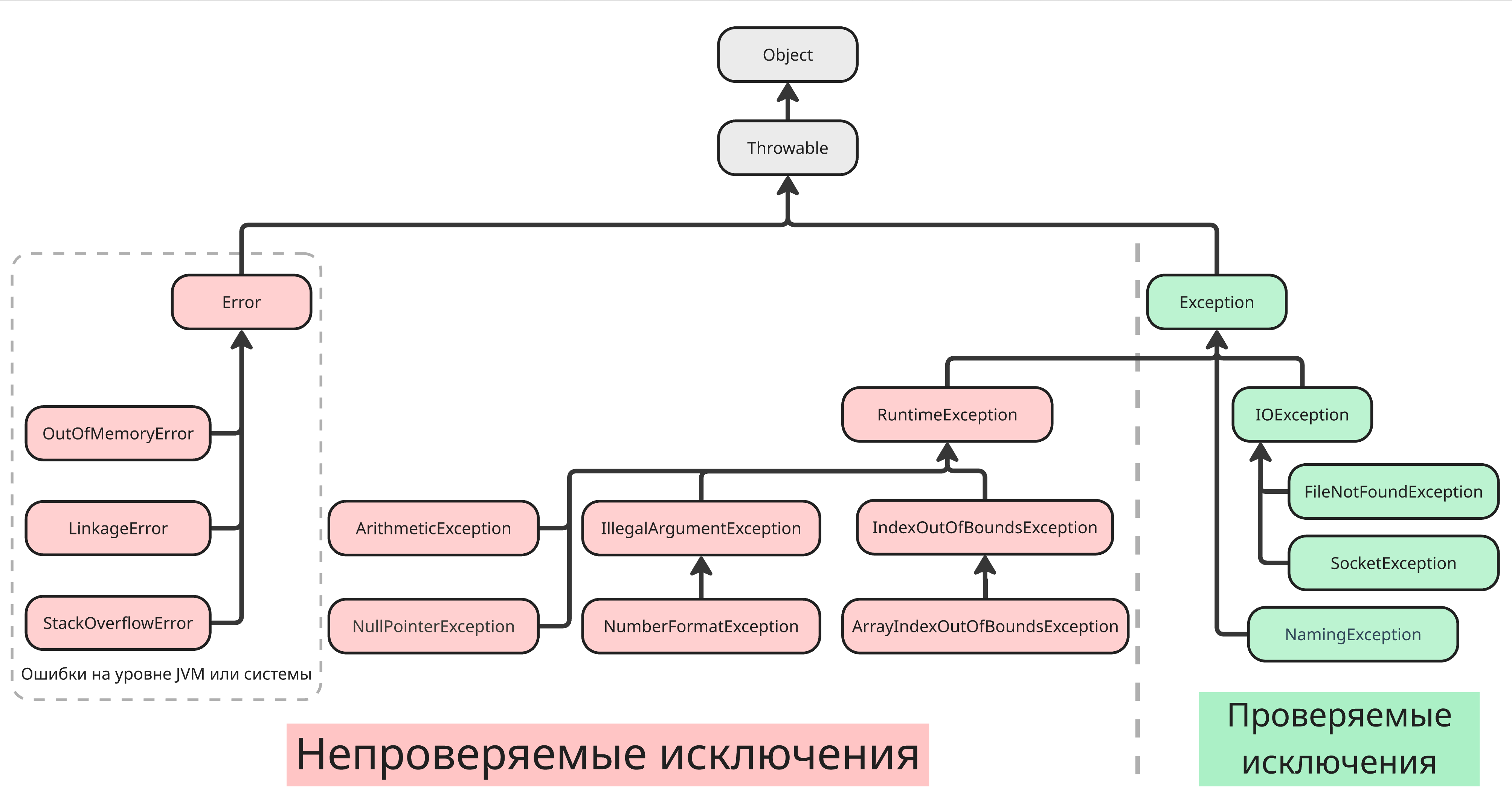
Ошибки в Java делятся на 2 типа:
-
Проверяемые (checked) исключения - такие ошибки возникают в предсказуемых ситуациях, обычно связанных с внешними факторами, и используются для ошибок, от которых программа может восстановиться
Компилятор проверяет, что метод выбрасывает такие исключения, и требует их указания в сигнатуре метода:
public void Do() throws FileNotFoundException { ... } -
Непроверяемые (unchecked) исключения - такие ошибки не проверяются компилятором и обычно возникают из-за ошибок программирования или системных сбоев
Они делятся на два типа:
-
Исключения, наследованные от
Error, - ошибки, связанные с JVM и системой -
Исключения, наследованные от
RuntimeException- исключения, связанные с работой кода (например, выход за пределы массива)
-
Также хорошим тоном будет указывание документации для классов и методов:
import java.time.LocalDate;
/**
* Класс "Собака"🐶
*/
public class Dog {
public String name;
private LocalDate birthdate;
/**
* Метод, вычисляющий возраст собаки
*
* @return int возраст собаки
*/
public int calculateAge() {
return LocalDate.now().getYear() - this.birthdate.getYear();
}
/**
* Метод, дающий собаке новое имя
*
* @param String новое имя собаки
*/
public void setName(String newName) {
name = newName;
}
/**
* Метод, вычисляющий возраст собаки
*
* @throws Exception исключение
*/
public void DoException() throws Exception {
throw new Exception("Yay!");
}
}
Лекция 2
Сейчас версией с долгосрочной поддержкой является Java 21
Разберемся в изданиях Java:
-
Java Platform Standard Edition (Java SE) - стандартная редакция Java, которая использует для разработки простых приложений
-
Java Platform Enterprise Edition (Java EE) - редакция для предприятий
-
Java Platform Micro Edition (Java ME) - редакция для разработки ПО на микроконтроллерах, мобильные платформы и т.д.
Комитет Java Community Process определяет, как будут выглядеть будущие спецификации Java
Классы в Java как правило объединены в пакеты. По умолчанию, стандартная библиотека Java содержит пакеты java.lang, java.io, java.util и другие. Организация классов в пакеты позволяет избежать коллизии имен.
В Java все коллекции представлены в Java Collections Framework наследуются от интерфейса java.util.Collection. Сам интерфейс java.util.Collection наследуется от интерфейса java.util.Iterable, позволяющий итерироваться по коллекции.
В Java в качестве динамического списка используют ArrayList (с произвольным доступом по индексу) и LinkedList (с последовательный доступом)
Vector в Java работает так же, как и ArrayList, но Vector потокобезопасный. Также Vector расширяется вдвое, а ArrayList в 1,5 раза
Помимо них есть:
-
Stack- стек, реализованный наVector -
Queue- односторонняя очередь -
Deque- двухсторонняя очередь -
Set- множество; реализации на хеш-таблицеHashSetи на деревеTreeSet -
Map- словарь; реализации на хеш-таблицеHashMapи на деревеTreeMap
В java.util.concurrent существуют потокобезопасные версии коллекций
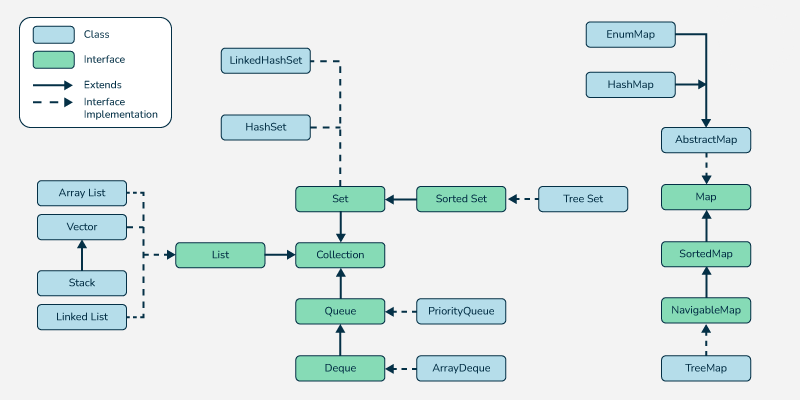
Помимо Java Collections Framework другие фреймворки, такие как Google Guava и Apache Commons Collections, реализуют свои коллекции
Чтобы обрабатывать коллекции, в Java есть Stream API. Работает он как LINQ в C#:
-
Создаем поток из коллекции:
list.stream() -
Применяем промежуточные методы, такие как
filter(),map(),sorted() -
Применяем терминальный метод, например,
count(),findFirst(),toList()
Пример:
list
.stream()
.filter(x -> x.toString().length() == 3)
.forEach(System.out::println);
list.stream().forEach(x -> System.out.println(x));
Лекция 3
По мере роста количества кода появилась потребность в системах сборки, которые связывают необходимые библиотеки с проектом. Впоследствии понадобилась автоматизация сборки, чтобы система сама находила зависимости, скачивала их, прогоняла тесты и деплоила на удаленный сервер
В начале единственным приличным инструментом для сборки был Make, позднее потребовались более функциональные инструменты для сборки. Сейчас можно выделить 3 популярные системы сборки для Java:
- Apache Ant и Apache Ivy
- Apache Maven
- Google Gradle
Apache Ant + Apache Ivy
Ant вышел в 2000 и был первым среди “современных” инструментов сборки. Для описания сборки Ant использует информацию, написанную в build.xml:
<project>
<target name="clean">
<delete dir="classes"/>
</target>
<target name="compile" depends="clean">
<mkdir dir="classes"/>
<javac srcdir="src" destdir="classes"/>
</target>
<target name="jar" depends="compile">
<mkdir dir="jar"/>
<jar destfile="jar/HelloWorld.jar" basedir="classes">
<manifest>
<attribute name="Main-Class"
value="antExample.HelloWorld"/>
</manifest>
</jar>
</target>
<target name="run" depends="jar">
<java jar="jar/HelloWorld.jar" fork.="true">
</target>
</project>
Позднее для управления зависимостями появился Apache Ivy. Ivy автоматически ищет в указанном репозитории указанные зависимости и скачивает их.
Во время сборки Ant делает 4 вещи (фазы, цели):
- clean - очистка предыдущих файлов сборки
- compile - компиляция
- jar - упаковка в jar архив
- run - запуск JVM
Apache Maven
Maven вышел в 2004 и стал преемником Ant и Ivy, сочетая в себе функционал этих инструментов. Maven умеет управлять зависимостям, которые загружены на репозиторий Maven Central
В отличии от Apache Ant, Maven требует строгой файловой структуры проекта:
project
|_ src
| |_ main
| | |_ java
| | |_ resources
| |_ test
| |_ java
| |_ resources
|_ target
|_ pom.xml
Управлять сборкой в Maven можно с помощью pom.xml файла (Project Object Model). В ней
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.O"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.O.O
http://maven.apache.org/xsd/maven-4.O.O.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>example.com</groupId>
<artifactId>example</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
</project>
Тег modelVersion указывает на версию Maven, теги groupld, artifactId, version указывают название и версию нашего артифакта (артифактом будем называть приложение, модуль, библиотему, jar-файл и прочее). В теге dependencies в том же формате указаны зависимости нашего проекта, которые будут загружаться из Maven Central
Чтобы изменить структуру проекта, в Maven придумали архетипы - шаблоны проектов. С помощью архетипов можно создать готовые шаблоны проектов для библиотек, для веб-приложений, для плагина и т.д.. Чтобы посмотреть доступные архетипы, можно выполнить команду mvn archetype:generate
Так же как и Ant, Maven обладает своим жизненным циклом
| Фаза | Описание |
|---|---|
| validate | Проверка корректность метаинформации о проекте |
| compile | Компиляция файлов |
| test | Проверка тестов на скомпилированных файлах |
| package | Упаковка в артефакт вида jar, zip и т.д. |
| verify | Проверка артефактов |
| install | Коммит артефакта в локальный репозиторий |
| deploy | Деплой на продакшен или удаленный репозиторий |
Жизненный цикл можно расширять при помощи плагинов. Плагины устанавливают при помощи изменения pom.xml:
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-checkstyle-plugin</artifactId>
<version>2.6</version>
</plugin>
</plugins>
Google Gradle
Google Gradle был выпущен в 2008 году для облегчения разработки Java-приложений на Android. Вместо громоздкого XML система сборки Gradle поддерживает два языка для описания сборки: предметно-ориентированные языки Groovy и Kotlin.
В качестве репозитория зависимостей Gradle поддерживает репозитории Ivy, Maven Central и другие.
Так как Gradle постоянно меняется и может не иметь совместимость между собой, существует Gradle Wrapper: скрипт grablew автоматически скачивает нужную версию Gradle, которая указана в build.gradle. Сам build.gradle, информация о проекте, выглядит так:
plugins {
id 'application'
}
repositories {
mavenCentral ( )
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter:5.9.1'
implementation 'com.google.guava:guava:31.1-jre'
}
application {
mainClass = 'demo.Арр'
}
tasks.named('test') {
useJUnitPlatform()
}
Или же можно создать build.gradle.kts, где указать то же самое, только на Kotlin:
plugins {
application
}
repositories {
mavenCentral ( )
}
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.9.1")
implementation("com.google.guava:guava:31.1-jre")
}
application {
mainClass.set("demo.Арр")
}
tasks.named<Test>("test") {
useJUnitPlatform()
}
Как и Maven, Gradle поддерживает плагины и имеет похожий цикл сборки
Лекция 4
Сборка мусора - процесс восстановления заполненной памяти среды выполнения путем уничтожения неиспользуемых объектов
В таких языках, как C и C++, программист сам отвечает за жизненный цикл объектов. В случае, если выделенная память для созданного объекта в конце его жизненного цикла не освобождается, то возникает утечка памяти:
void foo() {
// выделили память для 100 символов
char* array = new char[100];
// выделили память еще раз, перезаписали старый указатель,
// те самым потеряв к старому массиву доступ
array = new char[100];
}
Чтобы облегчить жизнь программиста и направить всю его концентрацию на создание бизнес-логики, придумали автоматическое управление памятью
В Java автоматическим управлением памятью занимается среда JVM. JVM по надобности выделяет нужный участок памяти на куче, в которой хранятся переменные, созданные программистом, и занимается сборкой мусора, то есть освобождением памяти уже ненужных переменных.
Перед сборщиком мусора (Garbage Collector) стоят 2 задачи:
- Обнаружение мусора
- Очистка мусора
Мусором мы будем считать объекты, ссылки на которые были утрачены, то есть доступ к нему невозможен
Обнаружение мусора
Есть 2 способа обнаруживать мусор:
- Счетчик ссылок (Reference counting)
- Трейсинг (Tracing)
Счетчик ссылок считает количество живых ссылок на объект. Если число ссылок достигает 0, то объект удаляется (подобно shared_ptr в С++). Несмотря на простоту, счетчик ссылок плохо сочетается с многопоточностью и без дополнительных алгоритмов не может выявлять циклические ссылки (объекты ссылаются друг на друга => счетчики не нулевые)
Трейсинг основан на графе объектов и его обхода. Для начала вводится понятие корневой точки (GC Root). Корневой точкой мы будем считать локальные переменные, статические переменные, потоки, ссылки из Java Native Interface и т.д.. Затем строится дерево ссылок. Мусором считается тот объект, до которого нельзя попасть из корневых точек.
Компилятор знает, когда заканчивается скоуп, в котором живет переменная, поэтому при выходе из скоупа (тела функции, цикла и т.д.) корневые точки прекращают свое существование (за исключением тех, что были возвращены функцией). Пример:
public House doSomething(string[] args) {
Person person = new Person("Ivan");
person.setHouse(new House());
person.getHouse().setRoof(new Roof());
person.getHouse().setDoor(new Door());
Person person1 = new Person("Michael");
Person person2 = new Person("John");
person1.setFriend(person2);
person2.setFriend(person1);
return person;
}
Получаем такой лес объектов:
person
|- house
|- roof
|- door
person1
|- person2
|- ...
person2
|- person1
|- ...
После return объект person остается жить, потому что он был возвращен, а person1 и person2 - нет. Несмотря на то, что количество ссылок на них ненулевое количество, из корневых точек в них попасть мы не можем (а таковым они перестают считаться после return)
Очистка мусора
От сборщика мусора нам нужно, что бы он:
- за предсказуемое время завершал свою работу (Latency and Responsiveness)
- не потреблял много оперативной памяти (Memory Footprint)
- не требовал большего количества вычислительных ресурсов (Throughput)
Добиться всех трех свойств нереально, поэтому то, что сейчас есть - это компромиссы между ними
Существует несколько алгоритмов очистки мусора. Один из них - копирующая сборка
Для копирующей сборки память условно делится на две части: from-space и to-space. Сначала объекты попадают в from-space. Когда она заполняется, происходит stop-the-world (остановка мира), сборщик мусора проходится по объектам, копирует нужные объекты в to-space, а ненужные высвобождаются. После этого области памяти from-space и to-space меняются местами (свапаются указатели)
Stop-the-world гарантирует, что во время очистки не выделится память для новых объектов, тем самым граф объектов будет заморожен
Другим методом является “отслеживание и очистка” (Mark and Sweep). При помощи трейсинга сборщик мусора помечает живые объекты и во время остановки мира пробегается по всем объектам и удаляет те, которые не были помечены живыми. После очистки объекты могут располагаться по всей памяти, тем самым фрагментируя ее. Дополнительно может производиться дефрагментация памяти (такой алгоритм называют Mark and Sweep Compact): сдвиг живых объектов в самое начало. Заметим, что дефрагментация - очень дорогая операция.
Еще один алгоритм основывается на так называемой “слабой гипотезе о поколениях”. В процессе наблюдения заметили, что объекты либо живут очень мало, либо очень много, причем чаще всего объекты из одной группы почти никак не связаны с объектами из другой.
Будем говорить, что быстроживущие объекты принадлежат младшему поколению (young generation), а долгоживущие - старшему поколению (old generation). Наблюдения привели к тому, что большинство объектов принадлежат младшему поколению (итераторы, локальные переменные и т.д.), тогда как если объект принадлежит старшему поколению, то ненужным он будет совсем не скоро.
Поэтому имеет смысл сделать три типа очистки:
- minor - очистка объектов из младшего поколения
- major - очистка объектов из старшего поколения
- full - очистка всех объектов
Сразу оговоримся, что мы рассматриваем алгоритм, реализованный в HotSpot JVM. Реализация может очень сильно отличаться от виртуальной машины и выбранного сборщика мусора.
Тогда мы можем разделить нашу память на 3 части:
- Эдем (Eden) - здесь хранятся только что созданные объекты
- Пространство выживших (Survivor Space) - здесь хранятся объекты, выжившие одну очистку мусора и перешедшие сюда из Эдема. Survivor Space делится на 2 части, S0 и S1, между которыми работает копирующая сборка
- Хранилище (Tenured) - здесь хранятся объекты старшего поколения
До Java 8 память JVM выглядела так:
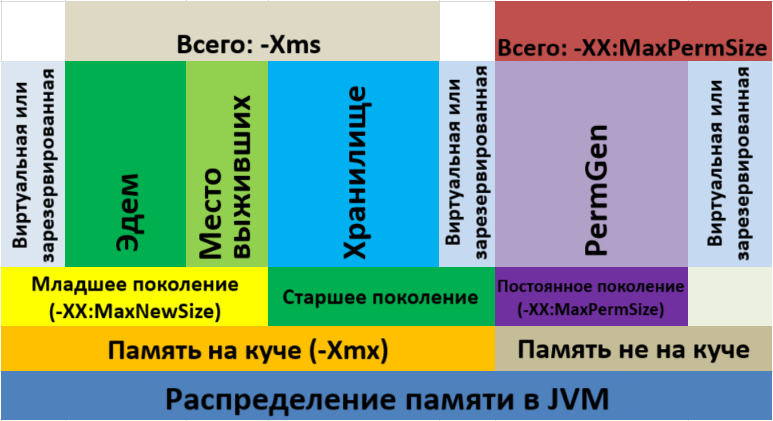
Помимо выше указанных существовала область PermGen - постоянное поколение. Там хранились метаданные о классах, и располагалась она на стеке. С Java 8 эту область решили назвать MetaSpace и перенести на кучу
Таким образом, Minor сборка мусора начинается с тех пор, как заполняется Эдем. Из Эдем выжившие объекты переходят в Пространство выживших. В Major сборке очищается хранилище
Сборщики мусора, основывающиеся на поколениях, называют Generational Garbage Collector
Реализации сборщиков мусора
Разберем некоторые реализации сборщиков мусора из HotSpot JVM
Serial GC
Простенький сборщик мусора для однопоточных приложений. Во время работы останавливает все приложение, поэтому не рекомендуется в случае, когда необходимы минимальные задержки. Включается флагом -XX:UseSerialGC в JVM
Parallel GC
Сборщик мусора по умолчанию, работает в несколько потоках, во время работы останавливает все приложение. Включается флагом -XX:UseParallelGC
CMS GC
Concurrent Mark and Sweep сборщик работает как и Parallel GC, только сводится время остановки мира к минимуму засчет большего потребления ресурсов ЦП. CMS GC не выполняет дефрагментацию. Включается флагом -XX:UseConcMarkSweepGC
G1 GC
Garbage 1st GC работает как и CMS GC, только вместо разделения памяти на поколения, память разделена на набор областей, каждая из которых может представлять младшее либо старшее поколение. Используется в Minecraft👍. Включается флагом -XX:UseG1GC
Epsilon GC
Совсем ниче не умеет, используется, когда мусора в вашем коде нет. Сдается, когда память закончилась. Включается флагом -XX:UnlockExperimentalVMOptions -XX:UseEpsilonGC
Shenandoah GC
Работает как G1 GC, только с меньшими задержками и большими затратами на ЦП. Включается флагом -XX:UnlockExperimentalVMOptions -XX:UseShenandoahGC
ZGC
Используется, когда нужны очень маленькие задержки и когда есть очень много оперативной памяти. Использовать лучше на сервере с огромном оперативкой, а не на тостере. Включается флагом -XX:UnlockExperimentalVMOptions -XX:UseZGC
В целом, выбор сборщика мусора зависит от характера разрабатываемого приложения. Однако, если приложение небольшое, то лучше прислушаться к настройкам по умолчанию👍
Лекция 5
Архитектура большинства приложений состоит из трех уровней:
- клиентский
- промежуточный
- уровень доступа к данным
Для уровня доступа к данным существуют такие инструменты:
- Java Database Connectivity API (JDBC API) - низкоуровневое API для доступа к хранилищу данных. Типичное использование JDBC — написание SQL запросов к конкретной базе данных.
- Java Persistence API - интерфейс для доступа к данным и преобразования этих данных в объекты языка программирования Java и наоборот. Гораздо более высокоуровневое API по сравнению с JDBC.
- Java Transaction API - интерфейс для определения и управления транзакциями, включая распределенные транзакции, а также транзакции, затрагивающие множество хранилищ данных.
Java Database Connectivity
JDBC представляет собой общий интерфейс для доступа к базе данных. Для подключения используется менеджер драйверов:
Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/db_name",
"user", "password");
DriverManager сам выберет нужный драйвер для указанной базы данных (в данном случае mysql)
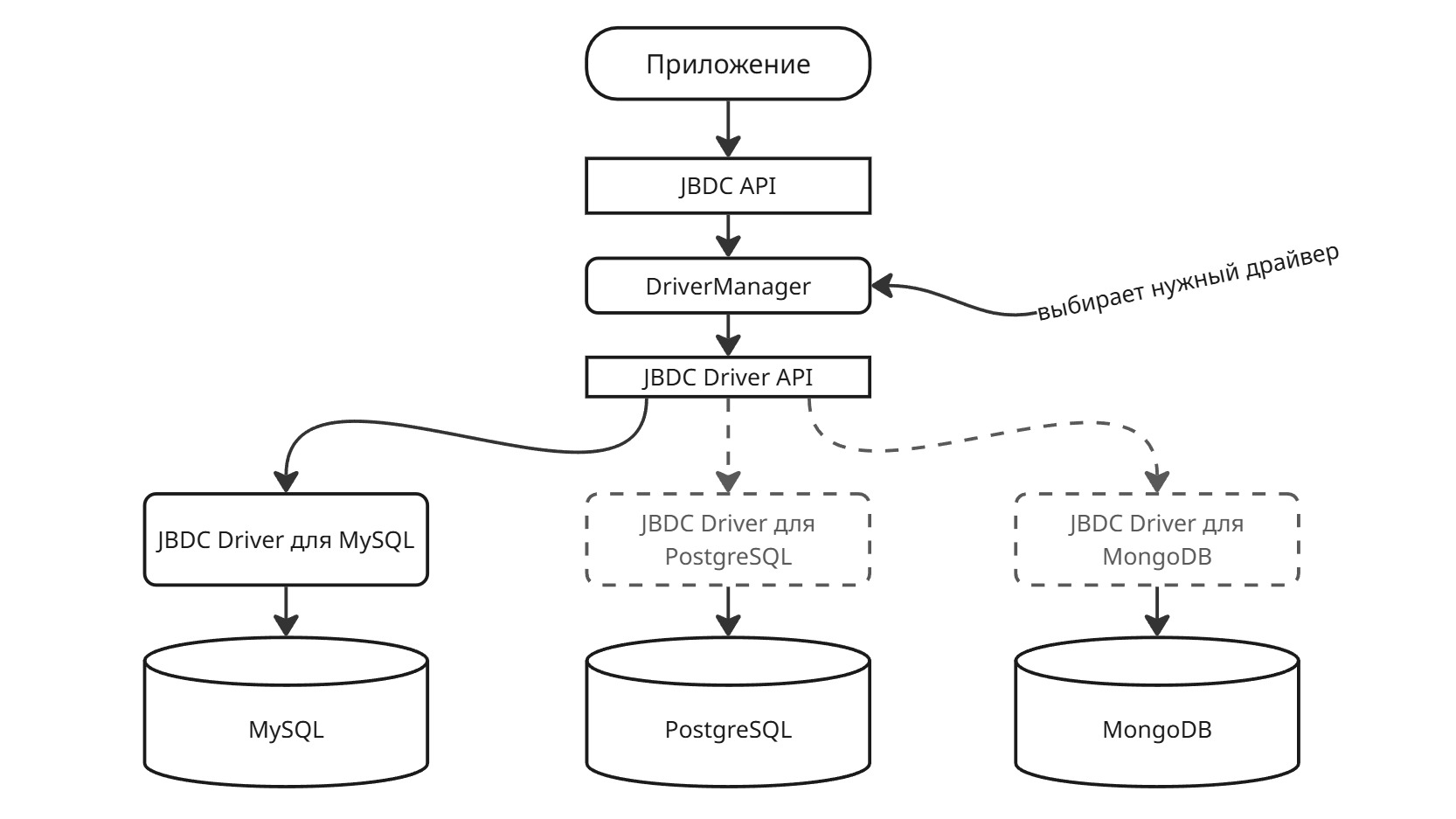
Чтобы сам класс нужного драйвера появился в проекте, используем менеджер зависимостей:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
dependencies {
implementation('mysql:mysql-connector-java:8.0.29')
}
Используя JDBC, с базой данных можно работать при помощи сырых SQL-запросов:
try (Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/db_name", "user", "password");
Statement stmt = conn.createStatement()) {
// SELECT-запрос
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
// Выводим идентификаторы и имена пользователей
while (rs.next()) {
System.out.println(rs.getInt("id"));
System.out.println(rs.getString("name"));
}
// INSERT-запрос
int rows = stmt.executeUpdate("INSERT INTO users (name) VALUES ('John')");
System.out.println("Добавлено строк: " + rows);
} catch (SQLException e) {
e.printStackTrace();
}
Все SQL-запросы можно разделить на два типа:
- Получение данных - инструкции SELECT и другие
- Изменение данных - инструкции INSERT, UPDATE, DELETE и другие
Для первых запросов используется метод executeQuery(), который возвращает ResultSet, содержащий данные
Для вторых запросов используется метод executeUpdate(), возвращающий количество измененных строк
При помощи JDBC можно создать выполнимую процедуру внутри базы данных:
CallableStatement callableStatement =
connection.prepareCall("{call calculateStatistics(?, ?)}",
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY,
ResultSet.CLOSE_CURSORS_OVER_COMMIT
);
Такие функции выполняются на сервере базе данных, то есть выигрывают в производительности, так как работают в одном пространстве памяти
При желании альтернативно можно создать подключение через определенный драйвер для базы данных, объявив DataSource:
OracleDataSource Ods = new OracleDataSource();
ods.setUser("stud");
ods.setPassword("stud");
ods.setDriverType("thin");
ods.setDatabaseName("stud");
ods.setServerName("localhost");
ods.setPortNumber(1521);
Connection conn = ods.getConnection();
Методы и их количество могут отличаться от драйвера к драйверу
Здесь thin - тип драйвера. Всего существуют 4 типа:
- Первый тип (Type-1) или JDBC-ODBC bridge driver
- Второй тип (Type-2) или Native-API driver
- Третий тип (Type-3) или Network Protocol driver
- Четвертый тип (Type-4) или Thin driver
Если нужно обратиться к одному типу базы данных, предпочтительным типом драйвера является Type-4.
Если Java-приложение обращается к нескольким типам баз данных одновременно, Type-3 является предпочтительным драйвером.
Драйверы Type-2 полезны в ситуациях, когда драйвер Type-3 или Type-4 еще недоступен для вашей базы данных.
Драйвер Type-1 обычно используется только при разработки и тестирования.
Зачастую пользоваться JDBC неудобно, так как все запросы становятся хардкодом, а Java-разработчики могут не знать SQL. Поэтому появился JPA
Java Persistence API
Java Persistence API - спецификация, описывающая систему управления сохранением Java объектов в таблицы реляционных баз данных в удобном виде. Сама Java не содержит реализации JPA, однако есть существует много реализаций данной спецификации от разных компаний.
Заметим, что JPA - это не единственный способ сохранения Java-объектов в базы данных (Object-Relational-Model-систем), но один из самых популярных.
Hibernate - одна из самых популярных открытых реализаций JPA версии 2.1. Далее будем рассматривать ее, как реализацию JPA
Чтобы объявить персистентную сущность, объявим ее аннотацией @Entity
@Entity
// явно указываем, из какой таблицы принадлежит сущность
@Table(name = "users")
public class User {
// говорим, что id - это первичный ключ, который будет генерироваться сам
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// указываем, что имя столбца отличается от имени атрибута
@Column(name = "user_name")
private String name;
// связь многие-к-одному
@ManyToOne
@JoinColumn(name = "countries")
private Country country;
// геттеры, сеттеры, другие методы
}
По умолчанию, Hibernate будет искать сущести в базе данных по их именам атрибутов (то есть переводя camelCase полей классов в snake_case атрибутов базы данных)
Далее сущности указываются в так называемой единице персистентности (persistence unit) в файле resources/META-INF/persistence.xml:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<!-- Здесь myunit - название группы сущностей -->
<persistence-unit name="myunit">
<description>
Описание
</description>
<!-- Здесь перечисляются сущности -->
<class>org.example.models.User</class>
<properties>
<!-- Данные для подключения -->
<!-- Здесь в качестве примера СУБД PostgreSQL и база данных с именем cats, находящаяся на localhost -->
<property name="hibernate.connection.driver_class" value="org.postgresql.Driver" />
<property name="hibernate.connection.url" value="jdbc:postgresql://localhost:5432/cast" />
<property name="hibernate.connection.username" value="${POSTGRES_USERNAME}" />
<property name="hibernate.connection.password" value="${POSTGRES_PASSWORD}" />
<!-- Настройка миграции -->
<property name="hibernate.hbm2ddl.auto" value="X" />
<!-- Вместо X подставить нужное значение:
validate - проверяет, что схема базы данных соответствует объектной модели, но не делает никаких изменений
update - обновляет схему с сохранением данных
create - создает схему, удаляя предыдущие данные
create-drop - создает схему, удаляя предыдущие данные, а также удаляет схему к концу сессии
-->
</properties>
</persistence-unit>
</persistence>
А чтобы работать с ними, используют EntityManager:
// Создаем EntityManager
EntityManagerFactory emf = Persistence.createEntityManagerFactory("myunit");
EntityManager em = emf.createEntityManager();
// Поиск по идентификатор
User user = em.find(User.class, 1L);
System.out.println(user.getName());
// JPQL-запрос
TypedQuery<User> query = em.createQuery(
"SELECT u FROM User u WHERE u.name LIKE 'A%'", User.class);
List<User> users = query.getResultList();
// Закрываем сессию
em.close();
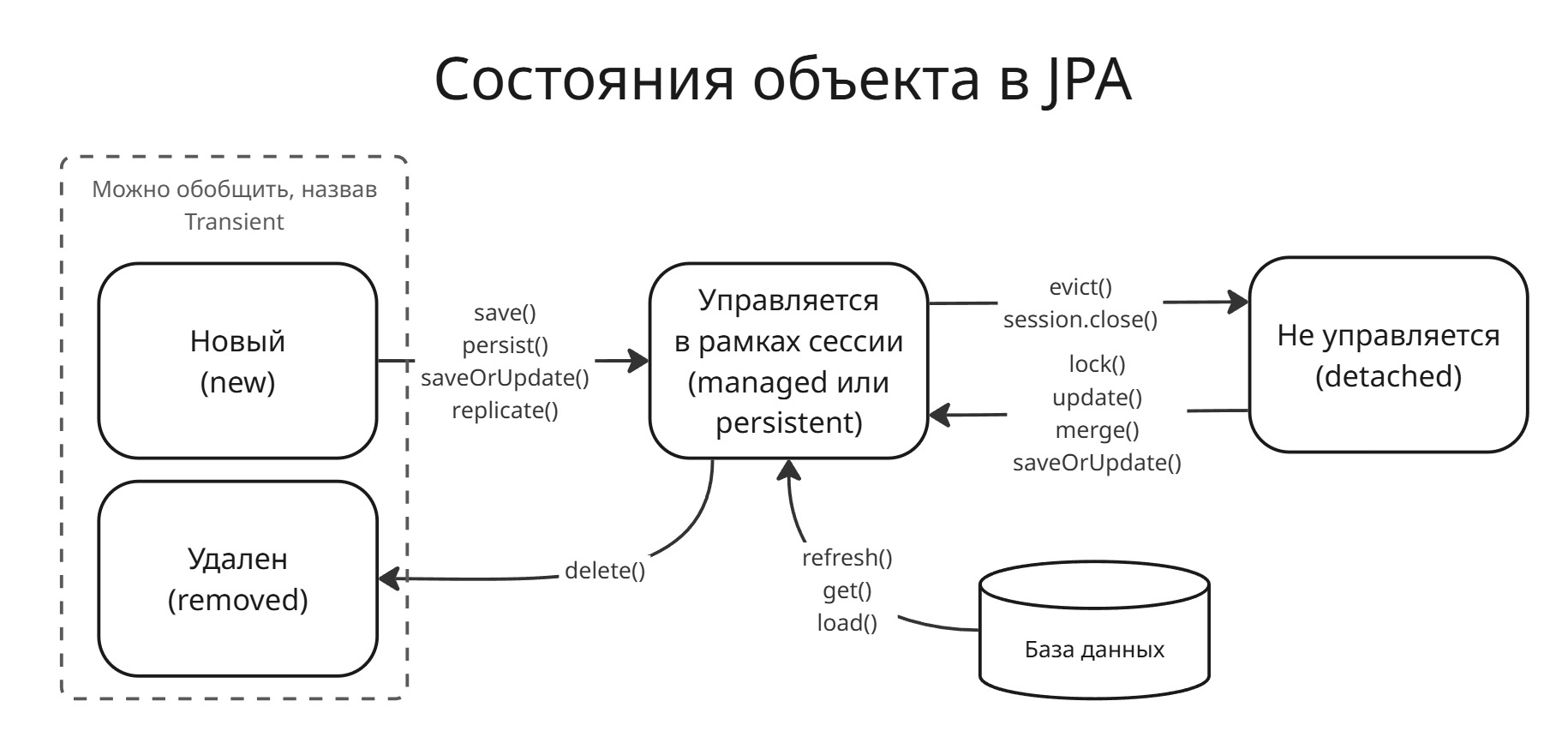
Сущности, включенные в JPA, имеют свое состояние:
- Новый объект - объект, созданный с помощью
new, но еще не имеет сгенерированный ключей и не хранится в базе данных - Удаленный объект - объект, который будет удален из базы данных после совершения транзакции
- Управляемый объект - объект, который управляется JPA
- Отсоединенный объект - объект, который существует в базе данных, но который не управляется JPA
Лекция 6
Spring Framework (или коротко Spring) — универсальный фреймворк с открытым исходным кодом для Java-платформы.
Spring является собой свободной альтернативной Java EE (или Jakarta EE), предоставляющая функционал для enterprise-разработки. Spring имеет множество расширений (MVC, Data и т.д.) и активной поддерживается сообществом
Spring IoC
Центральной частью Spring является контейнер Inversion of Control (инверсия управления). Он нужен для:
- управления жизненным циклом объектов
- связывания их между собой
По сути, то же самое, что и Dependency Injection в C#
Сами объекты, находящиеся в контейнере (еще называемом контекстом), называются бинами (bean)
Чтобы установить Spring, воспользуемся магическими строчками:
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.3.30</version>
</dependency>
</dependencies>
dependencies {
implementation('org.springframework:spring-context:5.3.30')
}
Зависимый объект может передаваться зависящему:
- напрямую через вызов метода контейнера
- через внедрение зависимостей (как аргумент конструктора, сеттера или свойства)
Чтобы Spring понял, какие классы должны стать бинами и участвовать в инверсии управления, их нужно
- указать в xml-конфиге
context.xml - аннотировать нужные сущности и указать пакет, в котором они находятся
- аннотировать нужные сущности и указать класс, который задает конфигурацию
Рассмотрим способ, включающий в себя xml-конфиг. Создадим две сущности - UserRepository и UserService:
public class UserRepository {
public String getData() {
return "Данные из репозитория";
}
}
public class UserService {
private final UserRepository userRepository;
private String endpoint;
public void setEndpoint(String endpoint) { this.endpoint = endpoint; }
public String getEndpoint() { return this.endpoint; }
// Конструктор для инъекции зависимости
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public void processData() {
System.out.println("Обработка данных: " + userRepository.getData());
}
}
Далее заполняем наш context.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- Определяем бин для UserRepository -->
<bean id="userRepository" class="UserRepository"/>
<!-- Создаем бин UserService с инъекцией зависимости через конструктор -->
<bean id="userService" class="org.example.models.UserService">
<constructor-arg ref="userRepository"/>
<!-- Можно указать свойство -->
<property name="endpoint" value="google.com"/>
</bean>
</beans>
Теперь в Main.java достаем контекст из конфига и используем его:
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Main {
public static void main(String[] args) {
// Загрузка контекста Spring из xml-файла
ApplicationContext context = new ClassPathXmlApplicationContext("context.xml");
// Получаем бин UserService из контейнера
UserService userService = context.getBean("userService", UserService.class);
// Используем сервис
userService.processData();
}
}
Здесь мы вручную создали только ClassPathXmlApplicationContext - все остальные объекты создал Spring
Вместо xml-конфига, можно создать конфиг-класс, в котором вручную прокинуть зависимости:
@Configuration
public class AppConfig {
// Указываем, что это бин
@Bean
public UserRepository userRepository() {
return new UserRepository();
}
@Bean
public UserService userService() {
return new UserService(userRepository());
}
}
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Main {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
UserService userService = context.getBean("userService", UserService.class);
userService.processData();
}
}
Это все надо делать ручками, поэтому перешли к сканированию пакета и аннотациям. Есть две аннотации, которые способствуют этому:
@Component- так помечаем класс, который будет участвовать во внедрении зависимости@Autowired- так помечаем метод (в том числе конструктор), которому будут передаваться зависимости из контейнера (также возможно приватное поле, которому будет передано зависимость)
В нашем примере это:
@Component
public class UserRepository {
public String getData() {
return "Данные из репозитория";
}
}
@Component
public class UserService {
private final UserRepository userRepository;
// Указываем, куда надо засунуть зависимость
@Autowired
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public void processData() {
System.out.println("Обработка данных: " + userRepository.getData());
}
}
Далее аннотированные классы можно показать Spring либо с указанием пакета, в котором они находятся:
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Main {
public static void main(String[] args) {
// Загрузка контекста Spring из сканирования пакета
ApplicationContext context = new AnnotationConfigApplicationContext("org.example.models");
UserService userService = context.getBean("userService", UserService.class);
userService.processData();
}
}
либо через отдельный класс конфига (так называемого JavaConfig), в котором указать пакет:
@Configuration
@ComponentScan("org.example.models") // Указываем пакет для сканирования
public class AppConfig {
}
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Main {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
UserService userService = context.getBean("userService", UserService.class);
userService.processData();
}
}
Вместо @Component можно использовать @Service, @Repository, @Controller, чтобы повысить читаемость
Если класс имеет несколько конструкторов, то можно добавить аннотацию @Primary для указания главного конструктора, которому будут передаваться зависимости
Чтобы задать скоуп (жизненный цикл) компонента, можно использовать аннотации:
@Scope("prototype")
@Scope("singleton")
// или
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
@Scope(ConfigurableBeanFactory.SCOPE_SINGLETON)
// ну и там еще есть request, session, application, websocket
или в xml-конфиге:
<bean id="userService" class="org.example.models.UserService" scope="singleton"/>
Как это работает?
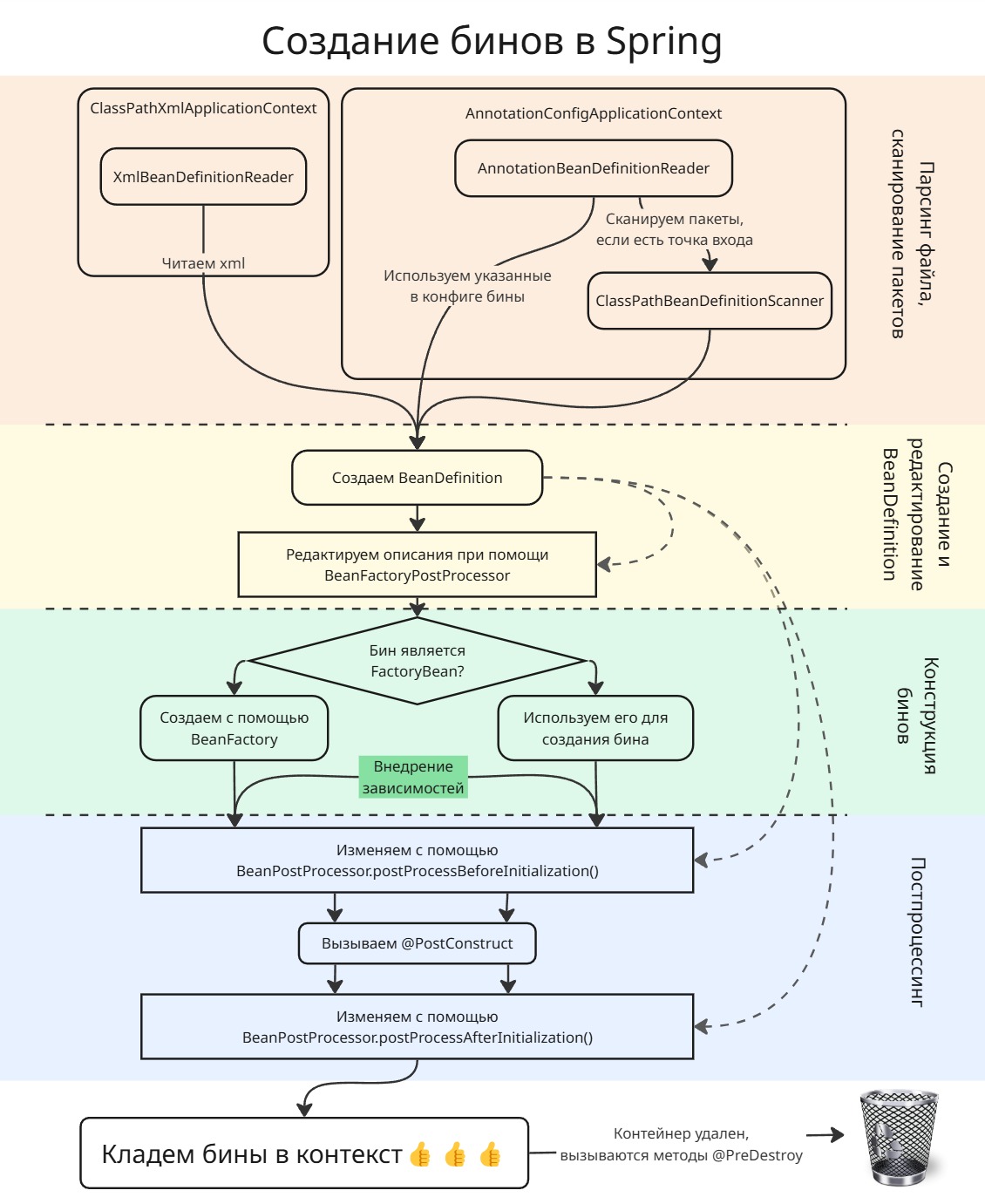
Сначала Spring достает все нужные ему сущности.
- Если это происходит через xml-файл, то используется объект класса
XmlBeanDefinitionReader. - Если это происходит через сканирование пакетов, то объект класса
AnnotationBeanDefinitionReaderищет все@Configuration, в которых могут быть дополнительные конфиги. ДалееClassPathBeanDefinitionScannerсканирует пакет на наличие@Component-классов
Теперь все считанные классы и интерфейсы запаковываются в объекты BeanDefinition, которые описывают будущие бины
По умолчанию, все BeanDefinition остаются не изменными, однако если в бинах случайно затесалась реализация BeanFactoryPostProcessor, то он используется для изменения описания бинов до их непосредственного создания. Пример такого BeanFactoryPostProcessor:
public class CustomBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
// Модифицируем существующий бин
BeanDefinition dbConfigDef = beanFactory.getBeanDefinition("dbConfig");
dbConfigDef.getPropertyValues().add("url", "jdbc:postgresql://default-host:5432/db");
// Создаем новый бин
GenericBeanDefinition newBeanDef = new GenericBeanDefinition();
newBeanDef.setBeanClassName("java.lang.String");
newBeanDef.getConstructorArgumentValues().addGenericArgumentValue("ЛОЛ!");
((DefaultListableBeanFactory)beanFactory).registerBeanDefinition("myBean", newBeanDef);
}
}
Все эти описания бинов хранятся в мапе. После этого они создаются при помощи BeanFactory
Если объект создается суперсложно, то его создание можно делегировать объекту класса, реализующего FactoryBean, например:
import org.springframework.beans.factory.FactoryBean;
// Создаем строки
public class StringFactoryBean implements FactoryBean<String> {
private String prefix;
private int counter = 0;
public void setPrefix(String prefix) {
this.prefix = prefix;
}
@Override
public String getObject() {
return prefix + "-" + (counter++);
}
@Override
public Class<?> getObjectType() {
return String.class;
}
@Override
public boolean isSingleton() {
return false;
}
}
Теперь можно получить объекты или фабрику:
String str = context.getBean("customStringFactory", String.class);
StringFactoryBean factory = context.getBean("&customStringFactory", StringFactoryBean.class);
ПОСЛЕ ЭТОГО, в ход вступают реализации BeanPostProcessor, которые могут дополнительно произвордить действия над созданными бинами перед и/или после инициализации (например, положить в прокси). Под инициализацией понимаются методы бинов, аннотированные @PostConstruct или указанные в xml как init-method: <bean id="userService" class="com.example.models.UserService" init-method="init"/>
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.config.BeanPostProcessor;
import org.springframework.stereotype.Component;
@Component
public class CustomBeanPostProcessor implements BeanPostProcessor {
// Вызывается ПЕРЕД инициализацией бина
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("Преинициализация: " + beanName);
return bean;
}
// Вызывается ПОСЛЕ инициализации бина
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("Постинициализация: " + beanName);
// Добавляем прокси для важного сервиса
if (bean instanceof ImportantService) {
return makeProxy(bean);
}
return bean;
}
private Object makeProxy(Object bean) {
System.out.println("Создаю прокси...");
return bean;
}
}
Теперь готовые бины кладутся в контекст
Когда контекст закрывается, у всех бинов вызывается метод, помеченный @PreDestroy или destroy-method="..." в xml
Лекция 7
Spring MVC
Spring MVC – модуль, который обеспечивает архитектуру паттерна Model - View - Controller (Модель - Отображение (или Вид) - Контроллер) при помощи слабо связанных готовых компонентов. Паттерн MVC разделяет аспекты приложения (логику ввода, бизнес-логику и логику UI), обеспечивая при этом свободную связь между ними.
- Model (Модель) инкапсулирует (объединяет) данные приложения, в целом они будут состоять из POJO (Plain Old Java Object - “Старый добрый Java-объект”, или бинов).
- View (Отображение, Вид) отвечает за отображение данных Модели, - как правило, генерируя HTML, которые мы видим в своём браузере.
- Controller (Контроллер) обрабатывает запрос пользователя, создаёт соответствующую Модель и передаёт её для отображения в Вид.
Spring MVC построен вокруг сервлета (объекта, который принимает запросы) DispatcherServlet, который распределяет запросы по контроллерам, а также предоставляет другие широкие возможности при разработке веб приложений.
DispatcherServlet уже интегрирован в Spring IoC, поэтому имеет доступ к встроенным в контекст бинам
DispatcherServlet, исходя из полученного HTTP-запроса, вызывает нужный контроллер, отмеченный аннотацией @Controller. Чтобы установить нужное действие по определенному эндпоинт, воспользуемся аннотацией @RequestMapping. В ней можно обозначить эндпоинт (и не только просто строка, а параметризированную (*тык*)), а также метод запроса
@Controller
@RequestMapping("/hello")
public class HelloControtter {
@RequestMapping(method = RequestMethod.GET)
public String printHetto(ModelMap model) {
model.addAttribute("message", "Hello Spring MVC Framework!");
return "hello";
}
}
Здесь вместо @RequestMapping(method = RequestMethod.GET) можно указать @GetMapping. Также есть другие специальные аннотации для типов запросов: @PostMapping, @PutMapping, @DeleteMapping, @PatchMapping
Еще пример:
@Controller
public class HelloController {
// Обработка GET-запроса на /hello
@GetMapping("/hello")
public String helloForm() {
return "hello-form"; // Вернет содержимое файла hello-form.html
}
// Обработка POST-запроса на /hello
@PostMapping("/hello")
public String sayHello(
@RequestParam("name") String name,
Model model
) {
// Здесь мы достаем имя из тела запроса и передаем его модели,
// контейнером, который передается слою с отображением
model.addAttribute("name", name.toUpperCase());
return "hello-response"; // Шаблон ответа
}
}
Готовые реализации интерфейса HandlerMapping могут в ответ на запрос дать нужный метод. По умолчанию есть:
-
RequestMappingHandlerMappingищет методы по аннотациям@RequestMappingи другим -
BeanNameUrlHandlerMappingиспользует параметры в аннотации@Bean(*тык*):@Configuration public class BeanNameUrlHandlerMappingConfig { @Bean BeanNameUrlHandlerMapping beanNameUrlHandlerMapping() { return new BeanNameUrlHandlerMapping(); } @Bean("/beanNameUrl") public WelcomeController welcome() { return new WelcomeController(); } }Или в xml-конфиге:
<bean class="org.springframework.web.servlet.handler.BeanNameUrlHandlerMapping" /> <bean name="/beanNameUrl" class="org.example.WelcomeController" />
Можно еще указать через SimpleUrlHandlerMapping - он использует явно добавленные методы:
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Bean
public SimpleUrlHandlerMapping urlHandlerMapping() {
SimpleUrlHandlerMapping mapping = new SimpleUrlHandlerMapping();
// Создаем мапу
Map<String, Object> urlMap = new HashMap<>();
urlMap.put("/manual", manualHandler());
// Указываем, в какой мапе смотреть эндпоинты
mapping.setUrlMap(urlMap);
// Указываем порядок обработки
mapping.setOrder(1);
return mapping;
}
// Обработчик контроллера
@Bean
public HttpRequestHandler manualHandler() {
return (request, response) -> {
response.getWriter().write("Handled manually!");
};
}
}
Контроллер чаще всего пишем мы сами, поэтому у него нет привязки к интерфейсу из библиотеки Spring. Поэтому существует HandlerAdapter. Выглядит он так:
public interface HandlerAdapter {
boolean supports(Object handler);
ModelAndView handle(
HttpServletRequest request,
HttpServletResponse response,
Object handler) throws Exception;
long getLastModified(HttpServletRequest request, Object handler);
}
Перед непосредственной обработкой запроса вызывается supports, который возвращает, доступен ли обработчик handler к работе. Далее вызывается handle, который его обрабатывает и возвращает отображение
Помимо этого Spring MVC кладет в контейнер с бинами:
-
HandlerExceptionResolverрешает, что нужно выдавать, если контроллер бросил исключение (например, показывать дефолтную 404 страницу) -
ViewResolverпреобразовывает имена представления, возвращенное контроллером, в фактическое представление (ну еще рендеринг делает) -
LocaleResolverиLocaleContextResolverопределяют локаль и часовой пояс -
ThemeResolverдостает из куков, сессии, параметров запроса тему, а затем по ней судит, какие давать стили CSS, картинки и прочее -
MultipartResolverобрабатывает составные запросы (сContent-Type: multipart/form-data), сохраняет файлы в память/временную папку и передает их контроллеру вместе с другими текстовыми полями -
FlashMapManagerхранит данные одного запроса для использования в другом (например, между редиректами)
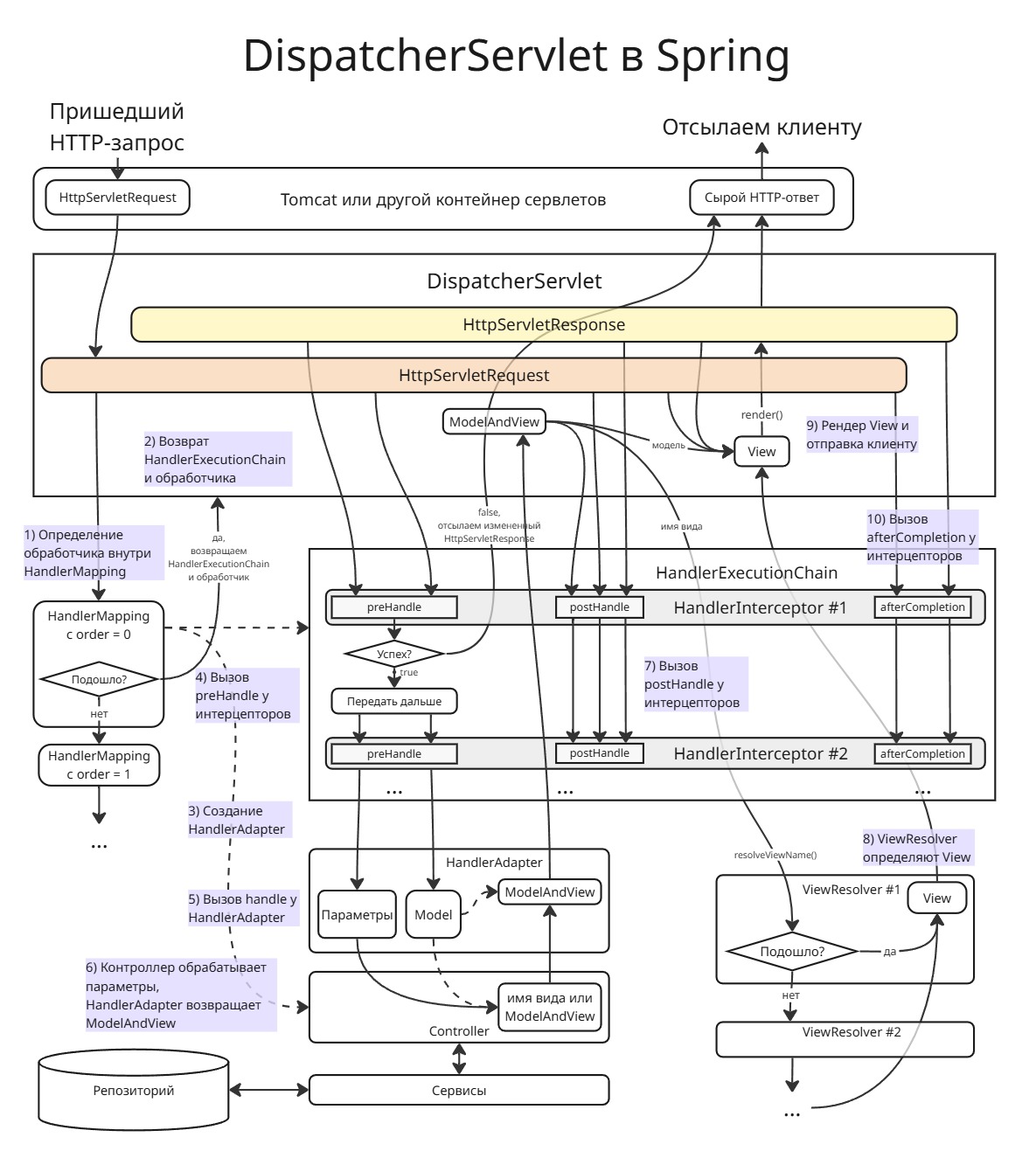
Разберем, как работает DispatcherServlet:
-
При получении HTTP-запроса
DispatcherServletдолжен определить при помощи доступных емуHandlerMappingкакому обработчику (методу контроллера) переправить запрос в видеHttpServletRequest. -
После определения контроллера внутри
HandlerMappingсписокHandlerExecutionChain(по сути цепочка обязанностей) из реализацийHandlerInterceptorвозвращается вместе с именем контроллера. Интерцепторы используются для пред- и постобработки запроса, а также после отсылки отображения клиенту -
Для обработчика создается обертка в виде
HandlerAdapter, реализации которых были найдены в контексте. По умолчанию, это:-
HttpRequestHandlerAdapterдля классов, реализующихHttpRequestHandler -
SimpleControllerHandlerAdapterдля классов, реализующих интерфейсController -
RequestMappingHandlerAdapterдля классов/методов, аннотированных@RequestMapping
-
-
Цепочка
HandlerExecutionChainвызывается, исполняя методыpreHandleу интерцепторов. Если какой-либо интерцептор вернетfalse, то запрос не дойдет до самого контроллера. Тогда считается, что запрос обработан интерцептором -
Когда все интерцепторы сказали
true, вызываетсяhandleуHandlerAdapter -
Контроллер принимает запрос, обрабатывает его и:
- сохраняет атрибуты отображения в
Model(например, черезmodel.addAttribute) и возращает имя отображения. - либо возвращает
ModelAndViewс именем отображения и атрибутами
Если контроллер хочет имплементировать REST API, то он сохранит все нужное в
Modelи вернетnull. Чтобы определить REST-методы, можно воспользоваться аннотациями@ResponseBodyдля методов или@RestControllerдля классов - сохраняет атрибуты отображения в
-
Теперь у интерцепторов цепочки
HandlerExecutionChainвызываютсяpostHandleдля постобработки -
При помощи интерфейса
ViewResolverDispatcherServletопределяет, какое отображение нужно использовать на основании полученного от контроллера имени -
После того, как отображение создано,
DispatcherServletотправляет данныеModelв виде атрибутов в отображение в методrender(), далее отображение в конечном итоге сохраняется вHttpServletResponse, а ответ далее идет отображаться в браузере -
В конце вызываются
afterCompletionу интерцепторов цепочки (например, для логгирования)
Если на каком-то этапе произошла ошибка, то реализации HandlerExceptionResolver возвращают какую-нибудь страничку с “что-то пошло не так”. По умолчанию в контексте есть:
-
ExceptionHandlerExceptionResolverобрабатывает исключения, передавая их аннотированным@ExceptionHandlerметодам:@ExceptionHandler(UserNotFoundException.class) public ResponseEntity<String> handleUserNotFound(UserNotFoundException ex) { return ResponseEntity .status(HttpStatus.NOT_FOUND) .body(ex.getMessage()); } -
ResponseStatusExceptionResolverможет отлавливать аннотированные@ResponseStatusисключения:@ResponseStatus(code = HttpStatus.NOT_FOUND, reason = "This user is not found") public class UserNotFoundException extends RuntimeException {}Здесь сообщение жестко зафиксировано, такое не получиться со стандартными исключениями, а также не вернуть какой-нибудь JSON
Также альтернативно можно кидать такие исключения в метода обработчика:
throw new ResponseStatusException( HttpStatus.NOT_FOUND, "User " + id + " not found!" ); -
DefaultHandlerExceptionResolverработает для стандартных Spring-исключений, возвращая подходящие для них HTTP коды статусов. Например, если вызвать GET для/user?id=abcпри имеющемся обработчике@GetMapping("/user") public User getUser(@RequestParam int id) { ... }DispatcherServletвыбросит ошибкуTypeMismatchException, аDefaultHandlerExceptionResolverвернетHTTP 400 Bad Request Body: "Failed to convert value of type 'java.lang.String' to required type 'int'"
Если HTTP-запрос пришел с заголовком Accept: <MIME_type>/<MIME_subtype>, то HttpMessageConverter будет искать доступные POJO доменной модели, пока не найдет соответствие с указанным в запросе типом. Далее HttpMessageConverter конвертирует тела входящих запросов в POJO, а в конце обработки запроса POJO в тела HTTP-ответов. По умолчанию, Spring Boot определяет набор дефолтных HttpMessageConverter

Лекция 8
Spring Boot
Spring Boot - набор утилит внутри Spring, автоматизирующих настройки фреймворка
Что должен сделать разработчик, чтобы запустить свое приложение без Spring Boot:
- В зависимости от характера приложения импортировать необходимые Spring-модули
- Импортировать библиотеку веб-контейнеров
- Импортировать необходимые сторонние библиотеки (например, Hibernate), при этом совместимые с выбранной версией Spring
- Конфигурировать компоненты DAO
- Определить класс, который загрузит необходимые конфигурации
Spring Boot же:
- Обеспечивает быстрый и широко доступный опыт начальной работы на Spring
- Делает возможным кастомизировать стандартное поведение
- Предоставляет ряд нефункциональных возможностей, таких как, тестирование, конфигурация, метрики и так далее
- Уходит от конфигом на XML
Все это работает благодаря:
- стартерам - готовым конфигурациям c бинами
- автоматической конфигурации библиотек
- преднастроенному Application Server для обеспечения серверного взаимодействия (в Spring используется Apache Tomcat)
- готовым рецептам для широко используемых подходов (метрики, внешняя конфигурация и т.д.)
Стартер
Стартер - это пакет зависимостей, собранных под одну задачу и оформленных как один артефакт для Maven или Gradle. Это ключевая особенность Spring Boot, упрощающая подключение библиотек и избавляющая от ручного выбора всех нужных зависимостей
Стартеры избавляют от ручного поиска всех зависимостей и обеспечивают совместимость библиотек между собой. Несколько популярных стартеров:
| Стартер | Назначение |
|---|---|
spring-boot-starter-web |
Для создания REST API и веб-приложений (включает Spring MVC, Tomcat) |
spring-boot-starter-data-jpa |
Для работы с базами данных через JPA/Hibernate |
spring-boot-starter-security |
Для добавления механизмов безопасности |
spring-boot-starter-test |
Для подключения JUnit, Mockito и других библиотек тестирования |
spring-boot-starter-thymeleaf |
Для серверной генерации HTML через шаблоны Thymeleaf |
spring-boot-starter-actuator |
Для мониторинга и управления приложением |
В spring-boot-starter-web входит Apache Tomcat. Apache Tomcat - комплект серверных программ, предназначенный для тестирования,отладки и исполнения веб-приложений на основе Java. Его обычно называют контейнером сервлетов - дополнительных компонентов, которые расширяют функциональность веб-сервера и позволяют ему выполнять приложения на языке Java.
Автоконфигурация
Второй превосходной возможностью Spring Boot является автоматическая конфигурация приложения.
После выбора подходящего starter-пакета, Spring Boot попытается автоматически настроить Spring-приложение на основе добавленных вами jar-зависимостей. Например:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableAutoConfiguration
@RestController
public class Main {
public static void main(String[] args) {
SpringApplication.run(Main.class, args);
}
@GetMapping("/")
public String hello() {
return "Hello world!";
}
}
С помощью аннотации @EnableAutoConfiguration Spring Boot может на основе добавленных зависимостей (например, spring-boot-starter-web) угадать, что и как именно нужно сконфигурировать
Другая аннотация, @SpringBootApplication, включает в себя аннотации @EnableAutoConfiguration и @ComponentScan (то есть включает автоконфигурацию и сканирование бинов)
Если сторонняя база данных не используется, а никаких сведений о подключении не предоставлено, Spring Boot автоматически настроит базу в памяти, без какой-либо дополнительной ручной конфигурации (при наличии H2 или HSQL драйверов)
В любой момент можно определить свою собственную конфигурацию, чтобы заменить определенные части автоконфигурации. Например, если добавить свой собственный бин DataSource, то средства поддержки встроенной базы данных по умолчанию отключатся.
Если необходимо узнать, какая автоконфигурация применяется в данный момент, можно запустить приложение с параметром --debug. Это позволит активировать отладочные журналы для выбранных основных диспетчеров журналирования и вывести отчет об условиях на консоль.
Можно указать, какие части автоконфигурации нужно исключить, например:
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
@SpringBootApplication(exclude = { DataSourceAutoConfiguration })
public class Main {
}
Initializr
Чтобы не тыкаться в xml или gradle файлике, гуглить самому зависимости и так далее, можно воспользоваться Spring Initializr (start.spring.io) - сайт, в котором можно выбрать нужную версию Spring, Java, подобрать нужные зависимости. Далее Spring Initializr сам генерирует шаблон проекта, автоматически делает конфиг с зависимостями и так далее
Инструменты разработчика
Модуль spring-boot-devtools включает в себя инструменты разработки, такие как:
-
Автоматическая перезагрузка (auto-restart) - при изменении классов или ресурсов приложение автоматически перезапускается (без полной перезагрузки JVM).
Это обеспечивает быструю обратную связь при разработке. Такой подход также известен как Hot Module Reload (“горячая” перезагрузка)
Перезагрузка работает при помощи основного и перезапускающего загрузчика:
- Классы, которые не будут изменяться (например, классы из сторонних jar-файлов), загружаются в основной загрузчик классов
- Классы, которые активно разрабатываются, загружаются в перезапускающий загрузчик классов
- Если приложение перезапускается, перезапускающий загрузчик классов единовременно используется, после чего создается новый, который подменяет старый. Такой подход означает, что перезапуск приложения обычно происходит гораздо быстрее, чем “холодный запуск”
- Отключение кеширования - кеш шаблонов (Thymeleaf, Freemarker), статики и т.п. отключается
- Улучшенные сообщения об ошибках - в stack trace отображаются более понятные причины ошибок
Модуль spring-boot-devtools выключается при свойстве spring.profiles.active=prod или при запуске приложения из jar-файла, чтобы не показывать пользователю подробности разработки
События при запуске
Spring Boot генерирует специальные события во время жизненного цикла запуска приложения. Эти события позволяют подключаться к нужным этапам старта и выполнять свою логику
ApplicationStartingEvent- Отправляется в самом начале, до инициализации контекста
- На этом этапе возможна только регистрация слушателей и инициализаторов
ApplicationEnvironmentPreparedEvent- Отправляется, когда доступна переменная
Environment
- Отправляется, когда доступна переменная
ApplicationContextInitializedEvent- Контекст уже создан, но бины ещё не загружены
- Выполнены
ApplicationContextInitializers
ApplicationPreparedEvent- Все определения бинов загружены
- Отправляется перед обновлением контекста
ApplicationStartedEvent- Контекст обновлён и запущен
- Но ещё не вызваны
ApplicationRunnerиCommandLineRunner(средства выполнения приложения и командной строки)
AvailabilityChangeEvent(LivenessState.CORRECT)- Обозначает, что приложение живое
- Следует сразу после
ApplicationStartedEvent
ApplicationReadyEvent- Приложение полностью готово
- Все раннеры (
ApplicationRunner,CommandLineRunner) вызваны
AvailabilityChangeEvent(ReadinessState.ACCEPTING_TRAFFIC)- Приложение готово принимать трафик
ApplicationFailedEvent- Отправляется, если во время старта возникло исключение
После ApplicationPreparedEvent и до ApplicationStartedEvent могут быть отправлены:
WebServerInitializedEvent- Отправляется, когда встроенный веб-сервер готов.
- Бывает двух видов:
ServletWebServerInitializedEvent— для обычного сервлета (Tomcat, Jetty и т.д.)ReactiveWebServerInitializedEvent— для реактивных приложений (Netty)
ContextRefreshedEvent- Отправляется, когда
ApplicationContextобновляется вручную или при запуске
- Отправляется, когда
Этот список касается только событий, относящихся к SpringApplicationEvent. Они особенно полезны для расширения поведения приложения на разных этапах запуска
Тестирование
Пакет spring-boot-starter-test включает в себя сразу библиотеки для работы с тестирование, а именно:
- JUnit 5 - стандартная библиотека для тестирования
- Spring Test и Spring Boot Test - средства поддержки утилит и интеграционных тестов для приложений Spring Boot. Модуль
spring-boot-testсодержит основные элементы, а модульspring-boot-test-autoconfigureподдерживает автоконфигурацию для тестов - AssertJ - для создания продвинутых ассертов
- Hamcrest - для создания объектов-сопоставителей (матчеров)
- Mockito - для мокирования объектов
- JSONassert - для проверки JSON-объектов
- JsonPath - XPath для JSON
Приложение Spring Boot – это ApplicationContext для Spring, поэтому для его тестирования не требуется ничего особенного, кроме тех операций, которые выполняются для ванильного контекста Spring
Spring Boot предусматривает аннотацию @SpringBootTest, которую по сути используется в качестве альтернативы стандартной аннотации @ContextConfiguration. Если Spring MVC доступен, конфигурируется обычный контекст приложения на основе MVC.
При тестировании приложений Spring Boot это обычно не требуется. Аннотации @*Test в Spring Boot осуществляют поиск вашей первичной конфигурации автоматически, если она не была определена вами явно. Алгоритм поиска начинает работу с пакета, содержащего тест, пока не найдет класс, аннотированный @SpringBootApplication или @SpringBootConfiguration
@SpringBootTest
@AutoConfigureMockMvc
public class HelloControllerTest {
@Autowired
private MockMvc mockMvc;
@Test
public void testHelloEndpoint() throws Exception {
mockMvc.perform(get("/hello"))
.andExpect(status().isOk())
.andExpect(content().string("Hello world!"));
}
}
По умолчанию аннотация @SpringBootTest не запускает сервер, а вместо этого создает имитационное окружение для тестирования конечных веб-точек (так называемых эндпоинтов).
Spring Data JPA
Spring Data JPA реализует готовые репозитории для доступа к сущностям через JPA. Конфиг для подключения к базе данных указывается в application.properties (или application.yml). По умолчанию Spring Boot подключает H2:
spring.datasource.url=jdbc:h2:mem:db
DB_CLOSE_DELAY=-1
spring.datasource.username=sa
spring.datasource.password=sa
С ними вместо написания своих DAO, использующих EntityManager, можно объявить класс репозитория, реализующий шаблонный интерфейс, а Spring Data JPA сам сделает реализации
public interface UserRepository extends CrudRepository<User, Long> {
}
Здесь User - класс, помеченный @Entity
Интерфейс CrudRepository задает базовые операции (создание, чтение, обновление, удаление). Интерфейс PagingAndSortingRepository предоставляет операции для пагинации и сортировки сущностей. Другой интерфейс, JpaRepository, является их объединением.
Класс, реализующие эти интерфейс, автоматически попадают в контейнер внедрения зависимостей
Традиционно сущности для JPA задаются в persistence.xml, но, используя Spring, так можно не делать - Spring сам их найдет по умолчанию с автоконфигурацией
Можно расширить функционал репозитория, при этом не писать своей собственной реализации. Работает это так: Spring по названию метода и аргумента может понять, какой ему нужно сгенерировать SQL-запрос, чтобы все заработало
Метод определяется по ключевым словам в его названии:
| Ключевое слово | Описание / Поведение | Пример метода | SQL-аналог |
|---|---|---|---|
And |
И | findByUsernameAndEmail |
WHERE username = ? AND email = ? |
Or |
ИЛИ | findByUsernameOrEmail |
WHERE username = ? OR email = ? |
Is, Equals |
Проверка на равенство (можно опустить) | findByUsername, findByUsernameIs |
WHERE username = ? |
Between |
Между двумя значениями | findByAgeBetween(18, 30) |
WHERE age BETWEEN 18 AND 30 |
LessThan, Before |
Меньше | findByAgeLessThan(18) |
WHERE age < 18 |
GreaterThan, After |
Больше | findByAgeGreaterThan(30) |
WHERE age > 30 |
LessThanEqual |
Меньше или равно | findByAgeLessThanEqual(18) |
WHERE age <= 18 |
GreaterThanEqual |
Больше или равно | findByAgeGreaterThanEqual(30) |
WHERE age >= 30 |
IsNull |
Значение = NULL | findByEmailIsNull() |
WHERE email IS NULL |
IsNotNull, NotNull |
Значение ≠ NULL | findByEmailIsNotNull() |
WHERE email IS NOT NULL |
Like |
SQL LIKE выражение (с %, _) | findByEmailLike("%@gmail.com") |
WHERE email LIKE '%@gmail.com' |
NotLike |
LIKE NOT | findByEmailNotLike("%test%") |
WHERE email NOT LIKE '%test%' |
StartingWith / StartsWith |
Начинается с | findByUsernameStartingWith("A") |
WHERE username LIKE 'A%' |
EndingWith / EndsWith |
Заканчивается на | findByUsernameEndingWith("ov") |
WHERE username LIKE '%ov' |
Containing / Contains |
Содержит (эквивалент %...%) |
findByUsernameContaining("adm") |
WHERE username LIKE '%adm%' |
In |
В списке | findByIdIn(List<Long> ids) |
WHERE id IN (...) |
NotIn |
Не в списке | findByUsernameNotIn(List<String> names) |
WHERE username NOT IN (...) |
True, False |
Для булевых полей | findByActiveTrue() |
WHERE active = true |
OrderBy |
Сортировка | findByAgeOrderByUsernameAsc() |
ORDER BY username ASC |
Top, First |
Лимит количества результатов | findTop3ByOrderByAgeDesc() |
LIMIT 3 |
ExistsBy |
Проверка на существование | existsByUsername(String username) |
SELECT COUNT ... > 0 |
CountBy |
Подсчёт | countByEmail(String email) |
SELECT COUNT(*) WHERE email = ? |
// Поиск по одному полю
Optional<User> findByUsername(String username);
// Поиск по нескольким полям (и)
Optional<User> findByUsernameAndEmail(String username, String email);
// Поиск с сортировкой
List<User> findByAgeGreaterThanOrderByUsernameAsc(int age);
// Проверка на существование
boolean existsByEmail(String email);
// Подсчёт
long countByAgeLessThan(int age);
Вместо findBy, возвращающего Optional<T>, может быть:
readByделает то же самоеgetByто же самое, но семантически подразумевает, что сущность точно существуетqueryByделает то же самоеcountByвозвращает количество сущностейexistsByвозвращает true, если сущность есть
Если очень хочется указывать свои шаблоны SQL-запросов, то это можно делать с помощью аннотации @Query
@Query("SELECT u.username, u.email FROM User u WHERE u.age >= :minAge")
List<Object[]> findUsernamesAndEmailsByAge(@Param("minAge") int minAge);
Если прям ОЧЕНЬ хочется, то можно реализовать свои методы:
public interface UserRepositoryCustom {
List<User> findUsersWithLongUsername(int minLength);
}
@Repository
public class UserRepositoryCustomImpl implements UserRepositoryCustom {
@PersistenceContext
private EntityManager entityManager;
@Override
public List<User> findUsersWithLongUsername(int minLength) {
return entityManager.createQuery(
"SELECT u FROM User u WHERE LENGTH(u.username) > :minLength", User.class)
.setParameter("minLength", minLength)
.getResultList();
}
}
Лекция 9
Spring Security
Spring Security – мощный фреймворк для обеспечения безопасности Java-приложений в экосистеме Spring. Он предоставляет комплексные сервисы безопасности (аутентификация, авторизация, фильтрация запросов и т.д.) для корпоративных веб-приложений. Spring Security возник из-за того, что встроенные в Java EE механизмы безопасности (Servlet/EJB) оказались слишком ограниченными и мало портируемыми для реальных задач. С помощью Spring Security можно гибко настроить проверку личности пользователя, разграничение прав доступа, защиту от CSRF, встроенную поддержку «remember-me», сессию, а также десятки других возможностей. Фреймворк автоматически интегрируется со Spring MVC/Boot и даже сам генерирует простые страницы логина/выхода по умолчанию
Основные понятия:
-
Аутентификация (Authentication). Процесс проверки и установления личности пользователя (principal) приложения. Обычно происходит проверка логина и пароля. Spring Security поддерживает множество моделей аутентификации (формовая, HTTP Basic/Digest, LDAP, JWT, OAuth2 и др.), при этом наиболее часто после успешного входа формируется объект
Authentication, содержащий информацию о пользователе -
Авторизация (Authorization). Процесс принятия решения, разрешено ли аутентифицированному пользователю выполнить запрошенное действие или получить ресурс. После аутентификации Spring Security сравнивает роли/привилегии пользователя с требованиями защищаемого ресурса. Например, проверяется, имеет ли пользователь роль
ADMINили другую необходимую полномочие. -
Фильтры безопасности (Security Filters). Весь механизм Spring Security построен как цепочка Servlet-фильтров. Эти фильтры перехватывают каждый HTTP-запрос до попадания в контроллер, проверяя аутентификацию и авторизацию. Spring Security по умолчанию подключается в FilterChain через
DelegatingFilterProxy. Фильтры могут, например, перенаправлять на страницу логина, если пользователь не аутентифицирован, или блокировать доступ, если прав недостаточно -
Контекст безопасности (Security Context). Информация о текущем пользователе (принципале) хранится в объекте
SecurityContext, привязанном к текущему потоку исполнения. Обычно Spring Security используетSecurityContextHolderсThreadLocalдля хранения текущегоAuthentication(информация о пользователе и его правах). Благодаря этому из любого места кода (в рамках одного HTTP-запроса) можно получить текущий контекст безопасности и узнать, кто залогинен. Spring Security самостоятельно очищает этот контекст после завершения обработки запроса -
Роли и привилегии (Roles and Authorities). В Spring Security права доступа пользователя задаются через «предоставленные полномочия» (
GrantedAuthority). Роли – это лишь особый тип полномочий. По соглашению роли записываются с префиксомROLE_(например, роль администратора называетсяROLE_ADMIN). Если в конфигурации указывается требованиеhasRole("ADMIN"), то Spring Security автоматически проверит, есть ли у пользователя полномочиеROLE_ADMIN. Таким образом «роль» – это только строковый маркер («ROLE_X»), а реальное решение принимается сравнением значенийGrantedAuthorityу текущегоAuthenticationс требуемыми атрибутами
Spring Security работает с помощью фильтров. Фильтры последовательно обрабатывают пришедший HTTP-запрос и решают, обрабатывать его дальше или нет. Фильтры образуют цепочку обязанностей:
@Configuration
@EnableWebSecurity
@EnableMethodSecurity
@RequiredArgsConstructor
public class SecurityConfig {
@Bean
@SneakyThrows
public SecurityFilterChain securityFilterChain(HttpSecurity http) {
return http
.csrf().disable()
.cors().disable()
.authorizeHttpRequests(customizer -> customizer.anyRequest().authenticated())
.httpBasic()
.authenticationEntryPoint((request, response, authException) -> response.sendError(401))
.and()
.build();
}
}
В этом примере мы:
- Отключаем для проекта защиту от атак CSRF (Cross-site request forgery). Атака CSRF работает так: вредоносный сайт отправляет от лица пользователя (сессия которого активна и находится в куки-файлах) POST-запрос, например, банку, а банк считает этот запрос валидным. Несмотря на то, что вредоносный сайт не видит куки, они автоматически прикрепляются в запросе браузером. Spring же для защиты от такого в запросе требует токен, который генерирует вместе с сессией
- Отключаем CORS (Cross-Origin Resource Sharing). По умолчанию браузер запрещают JavaScript-коду обращение к другим доменам, поэтому существует CORS: при запросе к отличающемуся домену сервер должен отправить в заголовке HTTP-запроса
Access-Control-Allow-Origin: https://example.com. Тогда браузер обработает его - Делаем так, что все запросы должны исходить от авторизованного пользователя. Иначе возвращаем 401 Unauthorized или перенаправляем на страницу с авторизацией
- Возвращаем настроенную цепочку фильтров
По умолчанию, фильтры такие:
WebAsyncManagerIntegrationFilter-Интеграция безопасности с асинхронными запросами (например,@Async)SecurityContextPersistenceFilter- Загружает/сохраняетSecurityContextвHttpSession(или другую стратегию) устанавливает его вSecurityContextHolderдля текущего потока. Если контекст ещё не создан (первый запрос), он создаёт новый «пустой» контекст. Это обеспечивает получение информации о ранее вошедшем пользователеHeaderWriterFilter- Добавляет HTTP-заголовки безопасности (например,X-Frame-Options)CsrfFilter- Обрабатывает защиту от CSRF-атак (если включена)LogoutFilter- Обрабатывает POST-запросы на/logout. В этом случае удаляется CSRF-токен, завершается сессия, чиститсяSecurityContextHolder-
BasicAuthenticationFilter- Обрабатывает HTTP Basic авторизацию (если используется): извлекает логин\пароль и передает их вAuthenticationManagerAuthenticationManagerпредставляет из себя интерфейс с одним методом:Authentication authenticate(Authentication authentication) throws AuthenticationException;В нашем случае имплементацией
AuthenticationбудетUsernamePasswordAuthenticationTokenAuthenticationManagerполучает объектAuthentication(например, с username и password) и передаёт его в подходящийAuthenticationProvider, чтобы проверить подлинность.AuthenticationProviderсодержит в себе два метода:Authentication authenticate(Authentication authentication) throws AuthenticationException; boolean supports(Class<?> authentication);Обычно реализуется через
ProviderManager, который внутри содержит списокAuthenticationProvider‘ов.AuthenticationProviderпроверяет, поддерживает ли он данный типAuthenticationс помощью методаsupports. Если поддерживает — проверяет credentials в методеauthenticate(например, сверяет пароль и логин), а если аутентификация успешна — возвращает полностью заполненный объектAuthenticationс флагомauthenticated=true.Если все провайдеры выкинул исключение,
ProviderManagerвыброситAuthenticationManagerпоследнее исключениеДалее фильтр сохраняет полученный
AuthenticationвSecurityContextHolder. Если выброситсяAuthenticationExceptionот провайдеров, то будет сброшен контекст, и вызоветсяAuthenticationEntryPoint RequestCacheAwareFilter- Кэширует защищённые запросы, чтобы потом на них вернуть пользователя:- Пользователь заходит на защищенный url.
- Его перекидывает на страницу логина.
- После успешной авторизации пользователя перекидывает на страницу которую он запрашивал в начале.
SecurityContextHolderAwareRequestFilter- Делаетrequest.isUserInRole(...)иgetUserPrincipal()работающимиAnonymousAuthenticationFilter- Назначает “анонимного пользователя”, если пользователь не аутентифицирован. Фильтр заполняет объектSecurityContextHolderанонимной аутентификациейAnonymousAuthenticationTokenс рольюROLE_ANONYMOUS. Это гарантирует что вSecurityContextHolderбудет объектSessionManagementFilter- Производится действия, связанные с сессией. Это может быть:- Смена идентификатора сессии
- Ограничения количества одновременных сессий
- Сохранение
SecurityContextвsecurityContextRepository
В обычном случае происходит следующее:
SecurityContextRepositoryс дефолтной реализациейHttpSessionSecurityContextRepositoryсохраняетSecurityContextв сессию. ВызываетсяsessionAuthenticationStrategy.onAuthentication:- По умолчанию, включена защита от Session Fixation Attack, то есть после аутентификации меняется идентификатор сессии.
- Если был передан CSRF-токен, генерируется новый CSRF-токен
ExceptionTranslationFilter- Перехватывает исключения (например, недостаточно прав или ошибка аутентификации) из более глубоких фильтров. Если пользователь не аутентифицирован,ExceptionTranslationFilterперенаправит его на точку входа (например, на страницу логина) или вернёт HTTP 401/403. Этот механизм обеспечивает корректное реагирование на проблемы с безопасностью.FilterSecurityInterceptor- Проверяет соответствие между требуемыми правами доступа и правами текущего пользователя. Здесь происходит сравнение атрибутов защищаемого ресурса (например, требуемой роли) с полномочиями вAuthentication. Если прав достаточно, запрос пропускается к контроллеру, иначе – генерируется отказ в доступе.
После обработки запроса всеми фильтрами результат либо отдается клиенту (запрос был разрешён), либо возвращается ошибка безопасности. При этом при завершении запроса SecurityContextPersistenceFilter может сохранить обновлённый SecurityContext (например, если пользователь только что вошёл) обратно в сессию.
Также есть:
RememberMeAuthenticationFilter, читающий куки и восстанавливающий аутентификациюOAuth2LoginAuthenticationFilterдля OAuth2-аутентификации
Конфигурация Spring Security может выполняться чисто на Java (без XML). Современный подход – объявлять бины SecurityFilterChain и UserDetailsService или WebSecurityCustomizer. Начиная с Spring Security 5.7 класс WebSecurityConfigurerAdapter считается устаревшим, и вместо него рекомендуется использовать SecurityFilterChain. Например, класс конфигурации может выглядеть так:
@Configuration
public class SecurityConfig {
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http
.authorizeHttpRequests(authz -> authz.anyRequest().authenticated())
.httpBasic(Customizer.withDefaults());
return http.build();
}
@Bean
public InMemoryUserDetailsManager userDetailsService() {
UserDetails user = User.withDefaultPasswordEncoder()
.username("user")
.password("password")
.roles("USER")
.build();
return new InMemoryUserDetailsManager(user);
}
}
В этом примере все запросы к приложению требуют аутентификации (anyRequest().authenticated()), и используется HTTP Basic для ввода логина/пароля. Пользователь с именем user, паролем password и ролью USER хранится в памяти внутри InMemoryUserDetailsManager. Метод withDefaultPasswordEncoder() упрощает демонстрацию (пароль автоматически кодируется), но не предназначен для продакшен-использования – в реальном приложении следует хранить пароль в безопасном зашифрованном виде.
При подобной конфигурации Spring Boot создаст простую стандартную форму логина/логаута по умолчанию. Как только разработчик добавляет Spring Security, по умолчанию все URL блокируются и требуют входа (пока не настроено иное поведение). Поведение фильтров (какие URL защищать, какие – открыты) меняется через методы authorizeHttpRequests(), permitAll(), hasRole() и т.д. Дополнительно можно настраивать CSRF-защиту, правила для статических ресурсов, перенаправления и прочее через объект HttpSecurity.
Если не настраивать пользователей вручную, Spring Boot по умолчанию создаст одного пользователя с именем user и сгенерированным паролем, который выводится в логи при запуске. Но обычно для учебных примеров и небольших приложений проще явно указать своих пользователей (как выше).
Продвинутые возможности:
- JWT (JSON Web Tokens). Часто Spring Security используют в безсессионном режиме для REST-API. В таком случае после логина выдаётся JWT-токен, который клиент отправляет в заголовке запроса. Затем на каждом запросе можно собственным фильтром извлекать JWT, проверять его подпись и создавать
Authenticationвручную. Spring Security полностью поддерживает работу с JWT (например, через модулиspring-security-oauth2-resource-server). - OAuth2. Spring Security имеет встроенную поддержку OAuth 2.0. Это позволяет легко настраивать вход через внешние провайдеры (Google, Facebook и др.) – механизм OAuth2 Client, а также реализовывать приложение как Resource Server (проверять входящие OAuth2-токены). С выходом новых версий добавлены удобные DSL и расширения для OAuth2.
- Кастомная аутентификация. При необходимости можно реализовать собственные компоненты. Например, создать свой
AuthenticationProviderили фильтр, чтобы проверить пользователя по 2FA, LDAP, внешним сервисам и т.д. Spring Security предоставляет точки расширения (например, можно сохранитьAuthenticationManagerкак бин и вставлять свои фильтры) – фреймворк изначально спроектирован как открытая и расширяемая платформа. - Интеграция с базой данных. Вместо хранения пользователей в памяти часто используют базу данных. Для этого есть готовый
JdbcUserDetailsManager, который может читать пользователей и роли из таблиц (с помощью SQL), или делают свой сервис, реализующийUserDetailsService, и подтягиваютUserDetailsиз JPA-Entitiy. ИнтерфейсUserDetailsв Spring Security служит как раз «адаптером» между вашей моделью пользователя в БД и тем, что нужно фреймворку. Таким образом вы можете хранить в БД произвольные поля (имя, email, статус и т.д.) и просто реализоватьloadUserByUsername, возвращая объект, унаследованный отUserDetails, содержащий имя, пароль и список ролей. Spring Security позаботится о проверке пароля, установке Authentication в контекст и применении политик доступа.
Лекция 10
Spring AOP
Аспектно-ориентированное программирование (АОП) - это парадигма программирования, являющаяся дальнейшим развитием процедурного программирования и ООП. Идея АОП заключается в выделении так называемой сквозной функциональности
В Spring AOP существуют следующие понятия:
Join Point - точки соединения, в которых внедряется сквозная функциональность
Pointcut - срез, выражение, определяющее набор точек соединения, к которым применяется функциональность
Advice - действие, выполняемый в определенный момент выполнения метода:
@Before- перед вызовом метода@Afterили@AfterFinally- после вызова метода@AfterReturning- если метод что-то вернул@AfterThrowing- если метод выбросил исключение@Around- параллельно с работой методом (например, чтобы засечь время работы метода)
Далее они собираются в класс с аннотацией @Aspect. Пример: имеется метод, который нужно логировать (так называемый Target). В этом случае, создаем интерфейс:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public interface Loggable {
}
@Aspect
@Component
public class LoggingAspect {
@Before("@annotation(Loggable)")
public void logBefore(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
System.out.println("➡ Вызов метода: " + methodName);
}
@AfterReturning(pointcut = "@annotation(Loggable)", returning = "result")
public void logAfter(JoinPoint joinPoint, Object result) {
String methodName = joinPoint.getSignature().getName();
System.out.println("✅ Метод " + methodName + " завершился. Результат: " + result);
}
@AfterThrowing(pointcut = "@annotation(Loggable)", throwing = "ex")
public void logException(JoinPoint joinPoint, Throwable ex) {
String methodName = joinPoint.getSignature().getName();
System.out.println("❌ Метод " + methodName + " выбросил исключение: " + ex.getMessage());
}
}
Здесь в качестве pointcut мы отмечаем все методы, которые были аннотированы @Loggable. Чтобы не хардкодить строки, можно создать отдельный метод для pointcut:
@Aspect
@Component
public class LoggingAspect {
@Pointcut("@annotation(Loggable)")
public void loggableMethods() { }
@Before("loggableMethods()")
public void logBefore(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
System.out.println("➡ Вызов метода: " + methodName);
}
...
}
Тогда на сам метод достаточно повесить аннотацию интерфейса:
@Service
public class UserService {
@Loggable
public String getUserById(Long id) {
if (id == null) {
throw new IllegalArgumentException("ID не может быть null");
}
return "Пользователь #" + id;
}
}
Также можно обозначить в pointcut все вызовы методов из определенного пакета: @Pointcut("execution(* com.example..*(..))")
АОП работает преимущественно в рантайме, однако расширение AspectJ может скомпилировать бины с аспектами заранее (так называемый Weaving). AspectJ расширяет синтаксис Java:
aspect LoggingAspect {
pointcut logMethods(): execution(* com.example..*(..));
before(): logMethods() {
System.out.println("Вызов метода: " + thisJoinPoint.getSignature());
}
}
Если целевой объект реализует какой-нибудь интерфейс, то Spring AOP будет использовать динамический прокси JDK, позволяющий проксировать интерфейс. Иначе будет использоваться CGLIB-прокси
Преимущества AOP:
- Повышенная модульность: Сквозные функции определяются один раз и применяются ко многим частям приложения.
- Улучшенная читаемость: Бизнес-логика не засоряется кодом сквозных функций.
- Упрощённое сопровождение: Изменения в аспектах не требуют модификации основного кода.
Потенциальные недостатки:
- Сложность отладки: Поведение программы может изменяться без явных изменений в коде, что усложняет отладку.
- Зависимость от фреймворков: Для использования AOP часто требуются дополнительные библиотеки или фреймворки.
- Потенциальное снижение производительности: Неправильное использование аспектов может привести к излишним накладным расходам.
Лекция 11
По мере приближения к пределу производительности на одном вычислительном узле мы приходим к тому, что проще разделить наше приложение на несколько частей, микросервисов, расположенных на разных узлах
Поэтому появилась микросервисная архитектура, позволяющая разделить приложения и независимо масштабировать отдельные части. К тому же повышается устойчивость к сбоям - узлы могут дублировать друг друга, а сами узлы использовать разные технологии: один написан на Java, другой на C#, а третий на Python
Однако, если же в монолитной архитектуре общение слоев происходило через функции, то как общаться микросервисам, которые могут располагаться в разных местах и иметь несовместимые интерфейсы?
Очевидным решением является общением по сети: мы можем сделать для каждого узла интерфейс, который отправляет/принимает нужные ему события. Определение этого интерфейса включает выбор транспорта или протокола и согласование форматов сообщений, которыми будут обмениваться системы.
Пока формат сообщений и порядок их отправки между системами согласованы, они смогут взаимодействовать друг с другом, не заботясь о реализации другой системы. До тех пор, пока поддерживается сам контракт, взаимодействие может продолжаться без изменений с другой стороны. Эти две системы эффективно разделены этим интерфейсом
Разделяют 2 типа связи между микросервисами:
- синхронная - при отправке запроса клиент ожидает ответ от сервиса - задачи выполняются только после того, как сервер пришлет ответ, например, HTTP
- асинхронным - код клиента или отправители сообщения не ждут ответ - сообщения отправляются аналогично передаче в очередь любого брокера, например, протокол AMQP (Advanced Message Queue Protocol)
Поэтому появились брокеры сообщений (или системы обмена сообщениями).
Брокеры являются независимой прослойкой в общении между микросервисами и в этот же момент базой данных, хранящей все пришедшие сообщения. Брокеры сообщений предоставляют свой интерфейс и свои библиотеки для разных языков, что позволяет объединить микросервисы с разными технологиями
Рассмотрим основные подходы в отправке и получении сообщений:
Point-to-Point
Подход Точка-Точка (или Point-to-Point) использует очереди сообщений между отправителем и получателем. Очередь действует как буфер, на который могут подписаться получатели, а очередь пытается справедливо распределить сообщения между потребителями. Таким образом, одно сообщение дойдет только одному потребителю
Очереди являются надежными - то есть очередь гарантирует, что будет сохранять сообщения до тех пор, пока потребители не подпишутся на нее. Тогда при появившейся возможности очередь отправит сообщения найденным потребителям. Очереди предоставляют гарантию, что сообщение будет доставлено хотя бы один раз
Надежность часто путают с персистентностью. Персистентность определяет, записывает ли сообщение система обмена сообщениями в какого-либо рода хранилище между получением и отправкой его потребителю
Сообщения, отправляемые в очередь, могут быть или не быть персистентными. Обмен сообщениями типа Точка-точка используется, когда требуется однократное действие с сообщением. В качестве примера можно привести внесение средств на счет или выполнение заказа на доставку
Publisher-to-Subscriber
Подход Издатель-Подписчик (Publisher-to-Subscriber) состоит в следующем: потребители могут подписаться на так называемые топики, в которых издатели отправляют свои сообщения. Издатель транслирует свои сообщения в топик, а подписчики их получают. Подписчики по своему желанию могут отписаться от топика, но тогда до них не дойдут сообщения издателей
Топики являются ненадежными - подписчики после повторной подписки не получат пропущенные сообщения. По этой причине можно сказать, что топики предоставляют гарантию доставки не более одного раза для каждого потребителя.
Издатель-Подписчик полезен, когда сообщения носят чисто информационный характер, например, температура градусника
Гибридная модель
Сценарии использования часто требуют совмещения моделей обмена сообщениями Издатель-Подписчик и Точка-Точка, например, когда нескольким системам требуется копия сообщения, и для предотвращения потери сообщения требуется как надежность, так и персистентность.
В этих случаях требуется адресат (общий термин для очередей и топиков), который распределяет сообщения в основном как топик, так, что каждое сообщение отправляется очереди, предназначенный для конечных потребителей (в этом случае ими могут быть группа потребителей, конкурирующих за сообщение, или один потребитель). Тип чтения в этом случае - один раз для каждой заинтересованной стороны. Эти гибридные адресаты часто требуют надежности, так что, если потребитель отключается, сообщения, которые отправляются в это время, принимаются после повторного подключения потребителя.
Гибридные модели не новы и могут применяться в большинстве систем обмена сообщениями, включая как ActiveMQ (через виртуальные или составные адресаты, которые объединяют топики и очереди), так и Kafka (неявно, как фундаментальное свойство дизайна её адресата).
В 2004 году появился брокер сообщений ActiveMQ с открытым кодом. ActiveMQ была разработана как реализация спецификации Java Message Service (JMS).
JMS же описывает абстракции для отправки и получения сообщений в асинхронном режиме по подписочной модели.
В ней изложены четкие указания по обязанностям клиента системы обмена сообщениями и брокера, с которым он общается, отдавая предпочтение обязательству брокера распределять и доставлять сообщения.
Основная обязанность клиента - взаимодействовать с адресатом (очередью или топиком) отправляемых им сообщений. Сама спецификация направлена на то, чтобы сделать взаимодействие API с брокером относительно простым.
Хотя API и ожидаемое поведение были хорошо определены в спецификации JMS, фактический протокол связи между клиентом и брокером был намеренно исключен из спецификации, чтобы существующие брокеры могли быть сделаны JMS-совместимыми. Таким образом, ActiveMQ был свободен в определении своего собственного протокола взаимодействия. Поэтому протокол OpenWire используется реализацией клиентской библиотеки ActiveMQ JMS. Помимо протокола OpenWire брокер ActiveMQ поддерживает:
-
AMQP (Advanced Message Queuing Protocol) - не имеет понятия клиентов или брокеров и включает в себя такие функции, как управление потоками, транзакции и различные QoS (Quality-of-Service, качество сервиса): не более одного раза, не менее одного раза и точно один раз
-
MQTT (Message Queuing Telemetry Transport) - протокол для отправки телеметрии
-
ну и другие, такие как STOMP
При работе со сторонними библиотеками и внешними компонентами необходимо учитывать, что они могут быть несовместимы с функциями, предоставляемыми в ActiveMQ.
Сам JMS описывает несколько сущностей:
ConnectionFactoryдля создания подключения к брокеруConnectionдля создания сессии для взаимодействия с брокеромSessionдля созданияMessageProducerиMessageConsumerMessageProducerдля отправки сообщенияMessageConsumerдля получения сообщения- и сам
Message
ConnectionFactory - это интерфейс, используемый для установления соединений с брокером. В типичном приложении реализация этого интерфейса представляет собой единственный экземпляр. Для ActiveMQ - это ActiveMQConnectionFactory.
Connection - это долгоживущий объект, после создания он обычно существует в течение всего жизненного цикла приложения до его закрытия. Connection - потокобезопасный и может работать с несколькими потоками одновременно.
Session - это дескриптор потока при взаимодействии с брокером. Объекты Session не являются потокобезопасными, что означает, что они не могут быть доступны нескольким потокам одновременно. Session - это основной транзакционный дескриптор, с помощью которого программист может закоммитить и откатить (rollback) операции обмена сообщениями, если он работает в транзакционном режиме. Используя этот объект, вы создаете объекты Message, MessageConsumer и MessageProducer, а также получаете указатели (дескрипторы) на объекты Topic и Queue.
MessageProducer - интерфейс позволяющий отправлять сообщение адресату.
MessageConsumer - интерфейс позволяющий получать сообщения. Существует два механизма получения сообщения:
-
Своя реализация
MessageListener, у которой при получении будет вызываться методonMessage(Message message)(push-модель):consumer.setMessageListener(new MessageListener() { @Override public void onMessage(Message message) { try { if (message instanceof TextMessage) { TextMessage textMsg = (TextMessage) message; System.out.println("Получено текстовое сообщение: " + textMsg.getText()); } else { System.out.println("Получено сообщение другого типа: " + message); } } catch (JMSException e) { e.printStackTrace(); } } }); -
Опрос на наличие сообщений с помощью методов
consumer.receive(),consumer.receive(long timeout)илиconsumer.receiveNoWait()
Message - самая важная структура. Сообщение содержит заголовки, свойства, а также само тело сообщения (полезная нагрузка, payload)
Заголовки - это хорошо известные элементы, определенные спецификацией JMS и доступные напрямую через API, такие как JMSDestination и JMSTimestamp. Свойства - это произвольные фрагменты информации о сообщении, которые задаются для упрощения обработки или маршрутизации сообщений без необходимости считывания самого тела сообщения.
Из Session может быть создано несколько различных типов сообщений в зависимости от типа содержимого, которое будет отправлено в теле - наиболее распространенными из которых являются TextMessage для строк и BytesMessage для двоичных данных.
Рассмотрим на примере ActiveMQ, как работает отправка сообщения брокеру:
- Издатель отправляет сообщение брокеру
- Брокер записал сообщение на диск для сохранения персистентность
- Брокер получил подтверждение записи
- Брокер уведомил (применяют сокращение ack от acknowledge) издателя, что его сообщение сохранено
Это ожидание подтверждения персистентных сообщений является базой гарантии, предоставляемой JMS API - если вы хотите, чтобы сообщение было сохранено, для вас, вероятно, также важно, было ли сообщение принято брокером в первую очередь.
Существует ряд причин, по которым это может оказаться невозможным, например, достигнут предел памяти. Вместо сбоя, брокер либо заставляет издателя ждать, пока не освободится память для обработки сообщения (процесс называется Producer Flow Control), либо он кинет исключение издателю - подобное поведение настраивается в брокере
Обычно, в простом базовом сценарии, никого не интересует, как там себя чувствует брокер сообщений и используют его по сценарию.
Если брокер записывает сообщения в файл, то перед тем как попасть на диск, данные могут оказаться в буферном кеше, поэтому в этом случае подтверждение получения необязательно означает непосредственную запись
Кстати, именно поэтому ваш компьютер жалуется, когда вы небезопасно извлекаете USB-накопитель - файлы, которые вы скопировали, на самом деле, возможно, не были записаны! Как только данные выходят за пределы буферного кэша, они попадают на следующий уровень кэширования, на этот раз на аппаратном уровне - кэш контроллера диска.
ActiveMQ включает в себя буфер записи, в который записываются сообщения. Затем данные из буфера записывается в одно действие. После завершения издатели получают уведомление. Таким образом, брокер максимизирует использование пропускной способности хранилища, а время, потраченное на открытие/закрытие файла, минимизируется
Как же работает отправка сообщения?
- Подписчик подписывается на сообщения брокера
- Брокер читает сообщения из памяти
- Брокер отправляет сообщения подписчику, часто партиями по несколько сообщений
- Подписчик принимает их в буфере (чтобы создать равномерный поток сообщений), обрабатывает их, далее уведомляет брокера, что он принял сообщения
- Брокер принимает, что подписчик сообщение прочитал, и записывает у себя, что сообщение обработано (ну и может удалить его)
Брокер может читать сообщения из памяти страницами, а может использовать механизм курсора между принимающей и перенаправляющей частями брокера для минимизации взаимодействия с хранилищем. Постраничное чтение является одним из режимов, используемым в этом механизме. Курсоры можно рассматривать, как кэш уровня приложения, который необходимо поддерживать в синхронизированном состоянии с хранилищем брокера.
Также в действительности брокер может не удалять сообщения - в журнал может записаться запись о подтверждении. Фактическое удаление файла журнала, содержащего сообщение, будет выполнено сборщиком мусора в фоновым потоке на основе этой информации
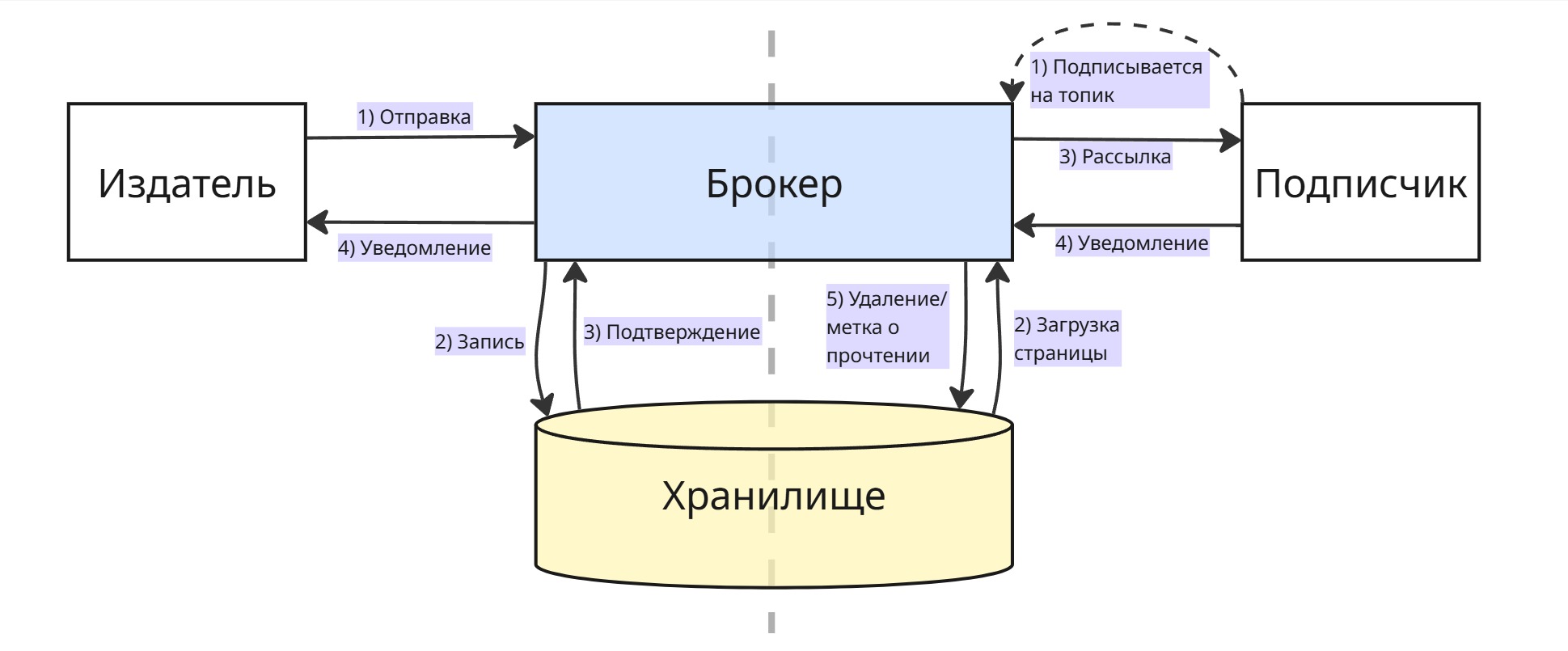
Лекция 12
Apache Kafka
Одним из популярных брокеров сообщений является Apache Kafka. Kafka первоначально разрабатывалась в LinkedIn. В 2011 году код был опубликован, а с 2012 года разработку ведет Apache.
Название брокер получил в честь писателя Франц Кафка, который, как известно, не дописывал свои произведения
Брокер Kafka обладает рядом преимуществ:
- Распределенность
- Отказоустойчивость
- Высокая доступность
- Надежности согласованность данных
- Высокая производительность (пропускная способность)
- Горизонтальное масштабирование
- Интегрируемость
Без брокера сообщений возникают следующие сложности в общении между производителями и потребителями:
- Тяжело гарантировать доставку сообщений
- Подключение новых получателей нужно осуществить для всех производителей
- Отправители знают получателей
- Интеграции разных стеков сделать тяжело, так как необходим единый интерфейс общения
Поэтому появляется прослойка в виде брокера сообщений
- Вся ответственность на гарантии доставки делегируется брокеру
- Брокер сам занимается подключение новых получателей к сети
- Отправители не знают получателей
- Интеграции разных стеков сделать легко, так как брокер предоставляем единый интерфейс общения
Брокер принимает сообщения, хранит и выдает их. Чтобы система была более отказоустойчивой, брокеров делают несколько и их объединяют в кластер. Таким образом, появляется возможность масштабирование и репликации сообщений
Другая сущность, Zookeeper, управляет кластером брокеров. Zookeeper следит за состоянием кластера, конфигурацией и решает, что делать, если упал какой-то узел. Zookeeper выбирает какого-то брокера и назначает его контроллером, который следит за консистентность. В последних версиях в Kafka реализован алгоритм Raft: брокеры сами знают о своей конфигурации и решают, что делать, если мастер-узел перестал работать
Само сообщение содержит:
- Ключ, используемый для распределения по кластеру
- Значение - полезная нагрузка
- Время сообщения, устанавливаемое при отправке или обработке
- Заголовки - пары ключ-значение с пользовательскими атрибутами
При приеме сообщения брокер кладет его в топик. Топик хранит в себе очередь (поток) сообщений. Эта очередь может быть разделена на части (партиции) для параллелизации. Эти партиции для удобства могут располагаться на разных брокера внутри кластера
Сами сообщения хранятся на диске так:
/.../kafka-logs/
├── my-topic-0/ # Партиция 0 топика "my-topic"
│ ├── 00000000000000000000.log # Сегмент лога (сами сообщения)
│ ├── 00000000000000000000.index # Индекс для быстрого поиска
│ ├── 00000000000000000000.timeindex # Индекс по времени
│ ├── 00000000000000012345.log # Следующий сегмент
│ └── ...
├── my-topic-1/ # Партиция 1 топика "my-topic"
│ └── ...
└── __consumer_offsets/ # Служебный топик для хранения оффсетов потребителей
-
.log– бинарный файл, содержащий сами сообщения (ключ, значение, метаданные). -
.index– индекс для быстрого поиска сообщений по оффсетам (смещениям). -
.timeindex– индекс для поиска по временным меткам.
Если .log-файл превышает максимальный размер файла в системе, то создается новый файл с названием <id нового сообщения>.log
При этом Kafka отдельные сообщения удалить не может, однако поддерживается автоматическое удаление по time-to-live (время, которые сегменты хранятся на диске), тогда удаляются целиком сегменты партиций
Если какой-то брокер падает, то его партиции в топике становится недоступной. Поэтому партиции реплицируют на другие брокеры. Какая-то из партиций назначается лидером, и все операции записи и чтения производятся через нее. Далее она копирует данные на другие партиции-реплики. Если брокер с партицией-лидером падает, то другая партиция становится лидером
Проблема может возникнуть в распределении лидерских партиций по брокерам. Если все лидерские партиции окажутся на одном брокере, то он станет узким горлышком в системе
Оптимально ставить количество реплик равное числу узлов-брокеров, уменьшенному на 1
Партиции-реплики обычно сами периодически посылают запросу брокеру с лидерской партицией (pull-модель), чтобы обновить свои данные. Однако, если лидер упадет, то данные на репликах могут быть не полными. Для решения этого вводятся синхронизированные реплики (in-sync replicas), запись в которых производится лидерской партицией (push-модель), таким образом данные в них актуальные, а сами они могут быть приоритетными кандитатами при падении лидера
При отправке сообщения через продюсер можно установить степень осведомленности о его обработке:
acks = 0означает, что продюсер не ждет подтверждение отправки сообщенияacks = 1означает, что продюсер ждет подтверждение только от лидерской репликиacks = -1означает, что продюсер ждет подтверждение от всех синхронизированных реплик
Потребитель же принимает сообщения из лидерских партиций какого-либо топика. Для дополнительной параллелизации может быть несколько потребителей, каждый из которых принимает сообщения из какой-либо партиции и которые объединены в группу потребителей
Чтобы отслеживать, какие сообщения были обработаны потребителями, существует специальный топик __consumer_offsets. При обработке сообщений потребителем потребитель отправляет сообщение с именем топика, номером партиции, идентификатором группы потребителей и номером последнего сообщения. Таким образом, при падении потребителя, другим потребителями внутри группы не придут уже обработанные сообщения
Почему Kafka быстрая:
- Масштабируемая архитектура
- Последовательные чтение и запись
- Нет случайного чтения
- Zero-copy
- Огромное количество настроек для разных случаев
Apache Kafka популярное и надежное решение, однако для работы с ней нужно понимать все нюансы и тонкости
Лекция 13
Использование JMS в Spring
Spring предоставляет инфраструктуру для интеграции с JMS, которая значительно упрощает использование стандартного JMS API
JMS функционально можно разделить на две основные области: производство (отправка) и потребление (получение) сообщений
Для производства сообщений и синхронного получения используется класс JmsTemplate
Для асинхронного получения Spring предоставляет ряд контейнеров слушателей сообщений (MessageListenerContainer), управляемых сообщениями. Эти контейнеры отвечают за создание и управление ресурсами (соединениями, сессиями, потребителями) и доставку сообщений вашим обработчикам
Сообщения отправляются через Message Driven POJO (MDP), содержащий метод, который вызывается контейнером при поступлении сообщения. Контейнер слушателя выступает посредником между JMS-брокером и определенным MDP
Основная функциональность для работы с JMS сосредоточена в пакете org.springframework.jms.core - здесь находится JmsTemplate. Принцип проектирования, общий для шаблонных классов Spring, заключается в предоставлении высокоуровневых, упрощенных методов, скрывающих сложность низкоуровневых операций и управление ресурсами (такими как открытие/закрытие соединений и сессий)
- Пакет
org.springframework.jms.supportсодержит функциональность для обработкиJMSException, преобразующую специфичные исключения JMS-провайдера в непроверяемые исключения SpringJmsExceptionдля единообразной обработки - Пакет
org.springframework.jms.support.converterсодержит абстракциюMessageConverterдля преобразования между объектами Java и сообщениями JMS (и обратно) - Пакет
org.springframework.jms.support.destinationсодержит различные стратегииDestinationResolverдля управления адресами назначения JMS - Пакет
org.springframework.jms.annotationсодержит аннотацию@JmsListener, с помощью которой можно легко указать методы-получатели MDP - Пакет
org.springframework.jms.configсодержит конфигурационную инфраструктуру для слушателей
Ключевым компонентом является ConnectionFactory. Брокер сообщений (например, ActiveMQ, RabbitMQ с плагином JMS) предоставляет свою реализацию
API-интерфейс JMS предусматривает два типа методов отправки, один из которых принимает режим доставки, приоритет и время жизни в качестве параметров качества обслуживания, а другой не принимает ничего и использует значения по умолчанию. Метод JmsTemplate.setReceiveTimeout используется, чтобы поставить таймаут
Сам же JmsTemplate объявляет множество метод для разных сценариев отправки и получения запросов, JmsTemplate является потокобезопасным, поэтому его можно внедрять как общую зависимость с временем жизни синглтона
Шаблону JmsTemplate нужно специально разрешить собственные значения QoS (Quality of Service). JMS API предусматривает два типа методов отправки: один принимает явные параметры QoS — режим доставки (deliveryMode: persistent/non-persistent), приоритет (priority) и время жизни сообщения (timeToLive). Другой использует значения по умолчанию
По умолчанию JmsTemplate использует значения по умолчанию (deliveryMode=PERSISTENT, priority=4, timeToLive=0 - то есть вечно). Чтобы использовать свои значения QoS для всех отправок через данный экземпляр JmsTemplate (установленные через setDeliveryMode(), setPriority(), setTimeToLive()), нужно явно включить флаг setExplicitQosEnabled(true) - иначе эти свойства игнорируются, и используются значения по умолчанию брокера/сессии
С помощью ConnectionFactory создается соединение Connection, затем на его основе создается сессия Session (которая определяет контекст для работы — транзакционный или нет, режим подтверждения получения). В рамках сессии создается MessageProducer (для отправки) или MessageConsumer (для получения)
Чтобы уменьшить эту длинную цепочку, Spring предусматривает две реализации ConnectionFactory:
SingleConnectionFactoryсоздает одно и то же соединениеConnectionпри всех вызовах (то есть ничего не кешируется). Это полезно для тестирования и автономных окруженийCachingConnectionFactoryдобавляет кеширование экземпляровSession,MessageProducerиMessageConsumer. Начальный размер кеша установлен на 1, его можно увеличить в свойствеsessionCacheSize. Сессии кешируются на основе их режима подтверждения, поэтому реальное число сессии может быть больше 1
JmsTemplate делегирует разрешение имени адреса назначения (которое как правило строка) в объект javax.jms.Destination объекту интерфейса DestinationResolver. По умолчанию реализован DynamicDestinationResolver, но есть возможность реализовать свой. Довольно часто адреса назначения становятся известны в рантайме, поэтому динамическое разрешение адресов является приоритетным в разработке
Адрес по умолчанию можно задать в свойстве defaultDestination (или defaultDestinationName для строки) у JmsTemplate. Тогда методы send() и receive() без явного указания адреса назначения будут использовать его
Важное свойство JmsTemplate - pubSubDomain (по умолчанию false). Если true, то при динамическом разрешении строки в Destination будет создаваться топик, а не очередь. Это определяет, в какой модели (Точка-Точка или Издатель-Подписчик) будет работать операция отправки/получения для динамически разрешаемых адресов
Чтобы асинхронно получать и обрабатывать сообщения из брокера, нужно:
- Создать MDP — POJO с методом, принимающим сообщение
javax.jms.Messageили уже сконвертированный объект, благодаряMessageConverter - Зарегистрировать этот MDP в контейнере слушателя сообщений. Начиная с Spring Framework 4.1, методы MDP удобно помечать аннотацией
@JmsListener(например,@JmsListener(destination = "myQueue")). Для включения обработки этой аннотации нужно добавить@EnableJmsв конфигурацию - Контейнер создает и управляет необходимыми JMS-ресурсами (
Connection,Session,MessageConsumer), получает сообщения и вызывает определенный метод MDP
В JMS есть две реализации контейнера:
SimpleMessageListenerContainerявляется самым простым - он создает фикс количество JMS-сессий и потребителей при запуске. Этот контейнер предоставляет множество свойств для его настройки:Session.AUTO_ACKNOWLEDGE(по умолч.): Сообщение автоматически подтверждается (ack) после успешного вызова метода MDPSession.CLIENT_ACKNOWLEDGE: Клиент (ваш MDP) должен явно вызватьmessage.acknowledge()для подтверждения получения всей группы сообщений (не только текущего)Session.DUPS_OK_ACKNOWLEDGE: “Ленивое” подтверждение; брокер может повторно доставить сообщение, если подтверждение задержится. Экономит ресурсы, допуская дубликатыSession.SESSION_TRANSACTED: Использует транзакционную JMS-сессию. Получение и обработка сообщения будут частью транзакции. Подтверждение (commit) происходит при успешном завершении метода MDP, откат (rollback) — при исключении (приведет к повторной доставке сообщения брокером)
Этот контейнер легковесный, но не может динамически масштабироваться и не поддерживает интеграцию с внешними менеджерами транзакций (как JTA)
DefaultMessageListenerContainer- контейнер, использующийся по умолчанию. Каждое полученное сообщение регистрируется в XA-транзакции (extended architecture), если конфигурация включаетJtaTransactionManager. Этот контейнер слушателя обеспечивает отличный баланс между низкими требованиями к JMS-поставщику, расширенной функциональностью и совместимостью со средами Java EE
Все методы отправки (send(), convertAndSend()) могут принимать либо конкретный объект Destination, либо строку с именем адреса (которая будет разрешена DestinationResolver), либо использовать адрес по умолчанию
Далее объект сообщения конвертируется при помощи MessageConverter. Реализация по умолчанию SimpleMessageConverter поддерживает преобразования между String и TextMessage, byte[] и BytesMessage, а также java.util.Map и MapMessage. Можно реализовать свой MessageConverter для сложных преобразований (например, в JSON/XML)
После конвертации объект можно обработать дополнительно в реализации интерфейса MessagePostProcessor. Это может быть полезно для установки заголовков сообщения (например, message.setStringProperty("MyHeader", "Value")). Передается как аргумент в методы convertAndSend(..., MessagePostProcessor postProcessor)
Фабрика контейнеров (JmsListenerContainerFactory), обычно DefaultJmsListenerContainerFactory, настраивается в конфигурации Spring (бины ConnectionFactory, MessageConverter, DestinationResolver, настройки транзакций TransactionManager, concurrency, cacheLevel для кэширования ресурсов и т.д.)
Аннотация @JmsListener на методе ссылается на эту фабрику через свойство containerFactory (если не указано, используется фабрика по умолчанию с именем jmsListenerContainerFactory)
Настройки параллелизма (concurrency) часто выносятся во внешнюю конфигурацию (например, application.properties): spring.jms.listener.concurrency=3-10, где 3 - минимальное число потоков, 10 - максимальное
Лекция 14
Эта лекция была пересказом доклада Вадима Лузика “Жизнь без Spring на Kotlin”. Презентация доступна здесь: https://cdn.tbank.ru/static/meetups/talks/24ef1ef4-c17a-4734-a54d-907828dcfb7d.pdf
Spring - это мощный фреймворк, но именно его универсальность делает его громоздким. Он тянет за собой множество конфигураций и зависимостей. Даже если используется лишь малая часть функциональности, всё равно нужно понимать, как работает остальное - просто потому, что это часть экосистемы. Это повышает порог входа и замедляет разработку на начальных этапах.
Кроме того, из-за своей масштабности Spring-приложения зачастую имеют высокие накладные расходы: потребляют больше памяти, требуют больше CPU, что особенно критично в условиях ограниченных ресурсов
Быстродействие таких приложений тоже страдает. В сравнении с легковесными фреймворками, Spring может запускаться в 3-5 раз медленнее, а потребление ресурсов под нагрузкой выше.
Кривая обучения достаточно крутая. Новичкам без опыта работы со Spring нужно время, чтобы освоить такие ключевые концепции, как IoC-контейнер, бины, автоконфигурация, AOP и т.д. Даже простой REST-контроллер может оказаться непрозрачным из-за аннотаций и скрытой магии.
Есть ли альтернативы? Да, и их немало. Вот список актуальных альтернатив Spring, включая как Java-, так и Kotlin-фреймворки:
- Micronaut на Java
- Quarkus на Java
- Helidon на Java
- Vert.x на Java
- Play Framework на Scala
- Ktor на Kotlin
- Http4k на Kotlin
Spring Boot остаётся самым популярным, но эта популярность - не всегда индикатор технологического превосходства. Альтернативы - в том числе Ktor - предлагают иной подход: меньше магии, больше контроля и лёгкость в старте
Ktor - это фреймворк от JetBrains, написанный на Kotlin. Это даёт ему несколько серьёзных преимуществ:
- Нативная интеграция с Kotlin: поддержка корутин, хорошая типизация, удобный DSL
- Минимум по умолчанию: из коробки - только нужное. Всё остальное подключается по мере необходимости
- Активное развитие и поддержка: JetBrains интегрирует поддержку Ktor прямо в IntelliJ IDEA, а также оперативно развивает экосистему
Если важна скорость разработки и контроль над архитектурой, Ktor - достойный выбор.
Как же создать приложение на Ktor?
- Создаём “hello-world” веб-приложение с Ktor
- Подключаем лёгковесный DI-фреймворк (например, Koin)
- Добавляем MongoDB как хранилище данных
- Используем Apache Kafka как брокер сообщений
- Используем Ktor HttpClient для внешних API-запросов
- Применяем Netty как web-сервер по умолчанию
Для DI на Kotlin есть несколько вариантов:
- Koin - самый популярный. Лёгкий, аннотированный, нативный для Kotlin, не требует сложной конфигурации
- Kodein - также Kotlin-first, но менее популярен
- Guice и Dagger - Java-фреймворки, которые можно использовать, но они менее удобны в Kotlin-контексте
Выбираем Koin, потому что:
- Он написан на Kotlin.
- Он легко интегрируется с Ktor
- У него есть аннотации, похожие на Spring (
@Single,@Factory,@Inject) - Хорошая документация и сообщество
Можно использовать application.yml для хранения настроек. Ktor позволяет удобно вытаскивать параметры конфигурации из этого файла с помощью конфигурационных классов. Это особенно удобно для перехода со Spring
Теперь можно добавить зависимости для MongoDB Kotlin Driver. Используем асинхронный API. Строим слой репозитория вручную, без Spring Data, что требует немного больше усилий, но даёт больше гибкости и понимания процессов
Чтобы с нашим приложением можно было общаться, интегрируем приложение с Kafka. Ktor не имеет встроенной поддержки Kafka, поэтому всё конфигурируется вручную через стандартные Kafka-клиенты
Для обращения к внешним API используем Ktor HttpClient. Он тоже построен на корутинах, легко конфигурируется и интегрируется
Теперь можно сравнить это приложение на Ktor с аналогичным на Spring:
| Метрика | Ktor | Spring Boot |
|---|---|---|
| Время старта | 0.6 сек | 2.49 сек |
Размер .jar |
36.5 МБ | 49.9 МБ |
| Нагрузочные тесты с использованием JMeter | Меньше потребление памяти | Выше потребление памяти |
Это важно: разница в скорости и ресурсоемкости особенно заметна под высокой нагрузкой. При лёгкой нагрузке всё примерно одинаково. Но когда начинается интенсивная работа - Ktor показывает себя эффективнее
Выводы:
- Жизнь вне Spring возможна. Писать приложения без больших фреймворков несложно, хоть и требует больше усилий
- Приложения на Ktor и других легковесных фреймворках показывают лучшую производительность при высоких нагрузках
- Тем не менее, Spring остаётся де-факто стандартом в мире Java-разработки: благодаря огромному сообществу, богатой экосистеме и множеству материалов
X. Программа экзамена 2024/2025
-
Что такое виртуальная среда исполнения управляемого кода? Каковы отличия от неуправляемых языков?
Виртуальная среда, которая управляет выполнением кода, предоставляет сервисы, такие как автоматическое управление памятью (сборка мусора), проверка типов, безопасность, оптимизация в рантайме
Критерий Управляемый код (Java) Неуправляемый код (C/C++) Управление памятью Автоматическое (сборщик мусора) Ручное ( new/delete,malloc/free).Безопасность Песочница: запрет небезопасных операций Прямой доступ к памяти (уязвимости) Платформозависимость Кросс-платформенный (байт-код) Требует перекомпиляции под платформу Производительность Может быть ниже из-за накладных расходов Выше (прямой доступ к железу) Примеры JVM (Java), CLR (.NET) Нативные приложения (ОС, драйверы) -
Что такое спецификация языка? Отличия между основными изданиями Java. Приведите примеры набора API различных изданий.
Спецификация - формальное описание языка (синтаксис, семантика, JVM) комитетом Java Community Process (JCP)
Издания Java:
Издание Назначение Пример API Java SE Базовые приложения. java.lang,java.util,java.io.Java EE Корпоративные приложения (веб, распределенные системы). javax.servlet,EJB,JPA.Java ME Встроенные системы (IoT, мобильные). MicroProfile,CLDC. -
Иерархия интерфейсов для работы с коллекциями. Особенности Stream API.
Иерархия интерфейсов:
Map не наследует
Collection, но входит в Collections Framework:HashMap,TreeMap,LinkedHashMap.
Stream API: Функциональный стиль обработки данных:
List<String> names = users.stream() .filter(u -> u.getAge() > 18) .map(User::getName) .sorted() .collect(Collectors.toList());- Промежуточные операции:
filter,map,sorted. - Терминальные:
collect,forEach,count.
-
Системы сборок, предназначение, ключевые особенности. Понятие модульности и конвенций иерархии пакетов.
Назначение систем сборки: Автоматизация: компиляция, управление зависимостями, тестирование, упаковка в JAR/WAR.
Система Особенности Конвенции структуры Apache Ant XML-скрипты, гибкость. Нет строгих правил. Apache Maven Конвенция > конфигурация, архетипы. src/main/java,src/test/resources.Gradle DSL на Groovy/Kotlin, высокая производительность. Аналогично Maven, но гибче. Модульность:
- Разделение кода на модули (например, с помощью Java Platform Module System (JPMS) в Java 9+).
- Зависимости декларируются в
pom.xml(Maven) илиbuild.gradle(Gradle).
-
Автоматическое управление памятью. Алгоритмы отчистки.
Задачи GC:
- Обнаружение мусора (недоступные объекты).
- Очистка памяти.
Алгоритмы обнаружения:
- Reference Counting: Подсчет ссылок (не работает с циклическими зависимостями).
- Tracing: Поиск достижимых объектов из GC Roots (потоки, статические поля).
Алгоритмы очистки: | Алгоритм | Принцип работы | Плюсы | Минусы | |——————–|——————————————–|—————————————|—————————| | Mark-Sweep | Пометить живое → удалить неживое. | Простота. | Фрагментация памяти. | | Mark-Compact | Mark-Sweep + дефрагментация. | Нет фрагментации. | Высокая стоимость. | | Copying | Копирование живых объектов в новую область. | Быстро для young-gen. | Требует 2x памяти. | | Generational | Разделение на young/old поколения. | Оптимизация под характер объектов. | Сложная реализация. |
-
Сборка мусора на поколениях. Устройство кучи. Принцип работы.
Принцип: Большинство объектов “умирают молодыми” (weak generational hypothesis)
Устройство кучи:
- Младшее поколение (Young Generation), состоящее из Eden (новые объекты) и Survivor Space (S0, S1 - выжившие после минорной сборки)
- Старшее поколение (Old Generation) из долгоживущих объектов
Процесс:
- Minor GC: Очистка Young Gen (копирование из Eden → Survivor)
- Major/Full GC: Очистка Old Gen (алгоритм зависит от GC: G1, CMS, ZGC)
-
Технологии Java EE для работы с данными. Популярные имплементации спецификации JPA.
Технологии:
- JDBC: Низкоуровневый API для SQL-запросов.
- JPA (Java Persistence API): ORM-стандарт (маппинг объектов на таблицы).
- JTA (Java Transaction API): Управление распределенными транзакциями.
Популярные реализации JPA:
- Hibernate: Самая распространенная, с расширенным функционалом.
- EclipseLink: Референсная реализация JPA.
- Apache OpenJPA.
Пример JPA-сущности:
@Entity @Table(name = "users") public class User { @Id @GeneratedValue private Long id; private String name; } -
Особенности реализации CDI в Spring. Внедрение зависимостей. Инверсия контроля.
IoC (Inversion of Control): Контейнер управляет жизненным циклом объектов и зависимостями вместо программиста.
DI (Dependency Injection): Способ реализации IoC: зависимости передаются объекту извне (через конструктор, сеттеры, поля).
Реализация в Spring:
- Бины: Объекты, управляемые контейнером (
@Component,@Service). - Внедрение:
@Autowired,@Inject. - Конфигурация: Через XML, JavaConfig (
@Configuration), аннотации (@ComponentScan).
Пример:
@Service public class UserService { private final UserRepository repository; @Autowired // DI через конструктор public UserService(UserRepository repository) { this.repository = repository; } } - Бины: Объекты, управляемые контейнером (
-
Что такое «сервлет»? Отличия сервера приложений и контейнеров сервлетов.
Сервлет - Java-класс, обрабатывающий HTTP-запросы (реализует интерфейс
javax.servlet.Servlet).Отличия: | Контейнер сервлетов | Сервер приложений | |—————————–|——————————–| | Обработка HTTP (Tomcat, Jetty). | Полная Java EE-реализация (WildFly, GlassFish). | | Поддержка только сервлетов/JSP. | + EJB, JMS, JTA, CDI. | | Легковесный. | Тяжелый, требует больше ресурсов. |
-
Жизненный цикл запроса в рамках DispatcherServlet в Spring.
Этапы обработки HTTP-запроса:
- Запрос приходит на
DispatcherServlet. - Поиск контроллера:
HandlerMappingопределяет, какойControllerобработает запрос. - Вызов контроллера:
HandlerAdapterвызывает метод контроллера. - Обработка: Контроллер возвращает имя представления + модель данных.
- Рендеринг:
ViewResolverвыбирает шаблон (JSP, Thymeleaf). - Формирование ответа:
Viewгенерирует HTML/JSON. - Ответ клиенту.
- Запрос приходит на
-
Основные задачи решаемые с помощью Spring Boot. С помощью каких инструментов достигается результат?
Spring Boot упрощает настройку Spring-приложений. Spring Boot использует:
- Стартеры - готовые наборы зависимостей (например,
spring-boot-starter-web) - Автоконфигурация - автонастройка бинов на основе зависимостей и classpath
- Actuator - мониторинг и управление приложением
- Embedded Server - встроенный веб-сервер Tomcat/Jetty
- Spring Initializr - GUI-генератор шаблонов проектов
- Стартеры - готовые наборы зависимостей (например,
-
Инструменты и типовые решения для аутентификации и авторизации запросов.
- Аутентификация: Проверка логина/пароля (через
AuthenticationManager). - Авторизация: Проверка прав доступа (
@PreAuthorize,hasRole()).
Механизмы:
- Form Login: Стандартная HTML-форма.
- HTTP Basic: Заголовок
Authorization: Basic. - JWT/OAuth2: Для REST API.
- Фильтры: Цепочка фильтров (
BasicAuthenticationFilter,FilterSecurityInterceptor).
Пример конфигурации:
@Configuration @EnableWebSecurity public class SecurityConfig { @Bean public SecurityFilterChain filterChain(HttpSecurity http) throws Exception { http .authorizeRequests(auth -> auth .antMatchers("/admin").hasRole("ADMIN") .anyRequest().authenticated() ) .formLogin(); return http.build(); } } - Аутентификация: Проверка логина/пароля (через
-
Парадигма аспектно-ориентированного программирования. Отличия от ООП.
Критерий ООП АОП Парадигма Инкапсуляция, наследование, полиморфизм. Разделение сквозной функциональности. Решаемая задача Моделирование предметной области. Логирование, транзакции, безопасность. Единица модульности Класс. Аспект (совет + срез). Пример в Spring @Service,@Repository.@Transactional,@Secured.АОП в Spring:
@Aspect @Component public class LoggingAspect { @Before("execution(* com.example.service.*.*(..))") public void logMethodCall(JoinPoint jp) { System.out.println("Вызов метода: " + jp.getSignature()); } } -
Межсервисное взаимодействие. Микросервисная архитектура.
Проблемы монолита:
- Сложность масштабирования.
- Технологическая связанность.
Принципы микросервисов:
- Каждый сервис решает одну задачу.
- Независимое развертывание.
- Слабосвязанность (через API).
Способы взаимодействия:
- Синхронное: HTTP/REST, gRPC (клиент ждет ответ).
- Асинхронное: Брокеры сообщений (Kafka, RabbitMQ).
-
Какие ключевые задачи решают брокеры сообщений? Перечислите известные вам модели обмена сообщениями и протоколы.
Задачи:
- Асинхронная коммуникация.
- Гарантии доставки.
- Буферизация нагрузки.
Модели:
- Point-to-Point: Очереди (1 сообщение → 1 потребитель).
- Pub/Sub: Топики (1 сообщение → N подписчиков).
- Гибридная: Комбинация (например, Kafka).
Протоколы:
- JMS: Java-стандарт (ActiveMQ).
- AMQP: Кросс-языковой (RabbitMQ).
- MQTT: Для IoT.
- Собственные: Kafka Protocol.
-
Ключевые отличия Apache Kafka от RabbitMQ. Паттерн Outbox.
Критерий Apache Kafka RabbitMQ Архитектура Распределенный log-брокер. Классический брокер (очереди). Модель Pub/Sub с сохранением истории. P2P, Pub/Sub. Скорость Очень высокая (миллионы сообщ./сек). Высокая (тысячи сообщ./сек). Надежность Сохранение на диск + репликация. Сохранение в памяти/на диск. Гарантии доставки At-least-once, Exactly-once (Kafka 0.11+). At-most-once, At-least-once. Использование Стриминг данных, аналитика в реальном времени. Традиционные задачи (очереди задач). Паттерн Outbox: Способ надежной доставки событий из микросервиса:
- Сохранить событие в БД (в таблицу
outbox) в той же транзакции. - Отдельный процесс отправляет события из
outboxв брокер (Kafka/RabbitMQ). - Гарантирует, что событие не потеряется даже при падении сервиса.
- Сохранить событие в БД (в таблицу