itmo_conspects
Лекция 5
Архитектура большинства приложений состоит из трех уровней:
- клиентский
- промежуточный
- уровень доступа к данным
Для уровня доступа к данным существуют такие инструменты:
- Java Database Connectivity API (JDBC API) - низкоуровневое API для доступа к хранилищу данных. Типичное использование JDBC — написание SQL запросов к конкретной базе данных.
- Java Persistence API - интерфейс для доступа к данным и преобразования этих данных в объекты языка программирования Java и наоборот. Гораздо более высокоуровневое API по сравнению с JDBC.
- Java Transaction API - интерфейс для определения и управления транзакциями, включая распределенные транзакции, а также транзакции, затрагивающие множество хранилищ данных.
Java Database Connectivity
JDBC представляет собой общий интерфейс для доступа к базе данных. Для подключения используется менеджер драйверов:
Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/db_name",
"user", "password");
DriverManager сам выберет нужный драйвер для указанной базы данных (в данном случае mysql)
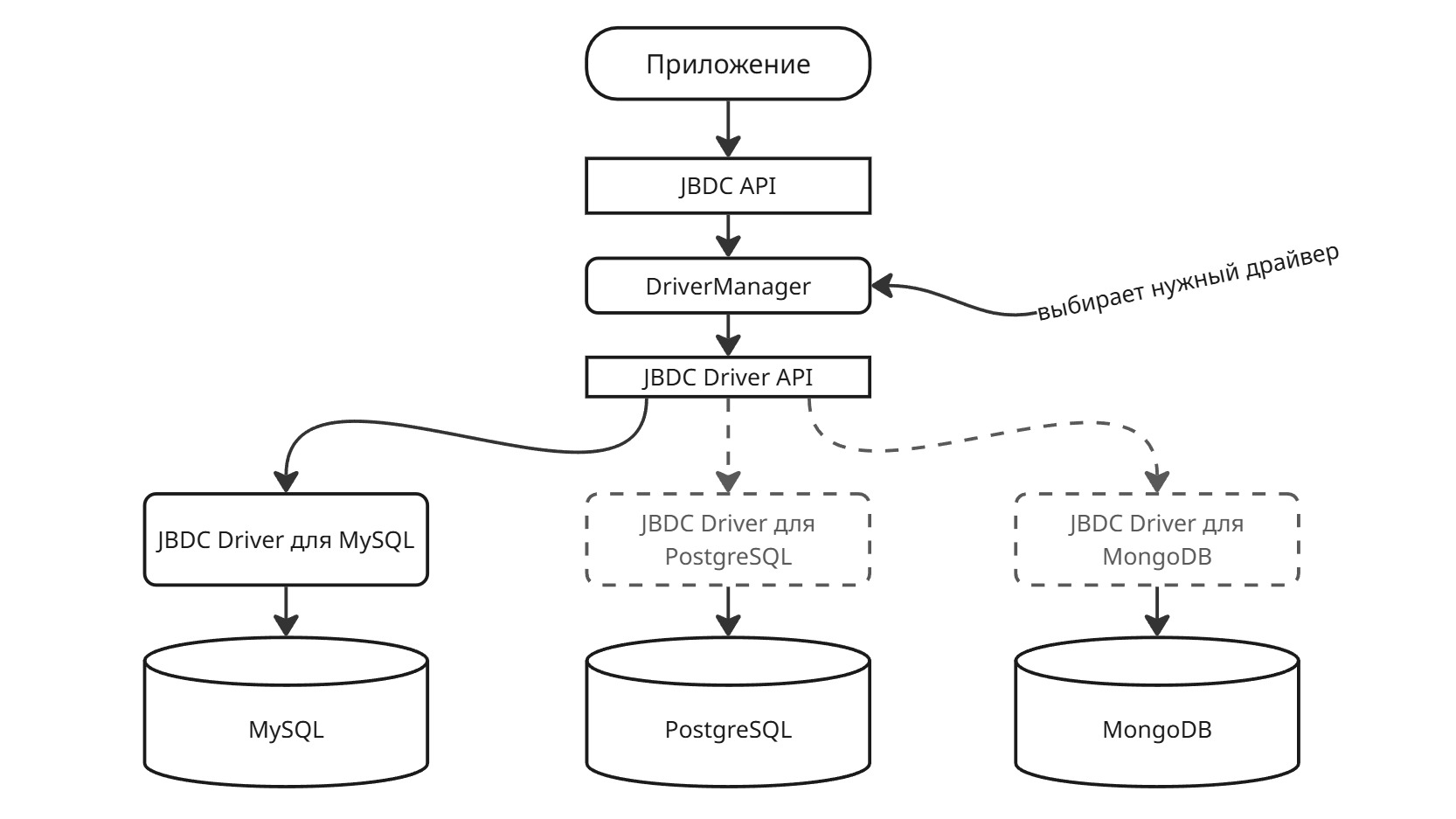
Чтобы сам класс нужного драйвера появился в проекте, используем менеджер зависимостей:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
dependencies {
implementation('mysql:mysql-connector-java:8.0.29')
}
Используя JDBC, с базой данных можно работать при помощи сырых SQL-запросов:
try (Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/db_name", "user", "password");
Statement stmt = conn.createStatement()) {
// SELECT-запрос
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
// Выводим идентификаторы и имена пользователей
while (rs.next()) {
System.out.println(rs.getInt("id"));
System.out.println(rs.getString("name"));
}
// INSERT-запрос
int rows = stmt.executeUpdate("INSERT INTO users (name) VALUES ('John')");
System.out.println("Добавлено строк: " + rows);
} catch (SQLException e) {
e.printStackTrace();
}
Все SQL-запросы можно разделить на два типа:
- Получение данных - инструкции SELECT и другие
- Изменение данных - инструкции INSERT, UPDATE, DELETE и другие
Для первых запросов используется метод executeQuery(), который возвращает ResultSet, содержащий данные
Для вторых запросов используется метод executeUpdate(), возвращающий количество измененных строк
При помощи JDBC можно создать выполнимую процедуру внутри базы данных:
CallableStatement callableStatement =
connection.prepareCall("{call calculateStatistics(?, ?)}",
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY,
ResultSet.CLOSE_CURSORS_OVER_COMMIT
);
Такие функции выполняются на сервере базе данных, то есть выигрывают в производительности, так как работают в одном пространстве памяти
При желании альтернативно можно создать подключение через определенный драйвер для базы данных, объявив DataSource:
OracleDataSource Ods = new OracleDataSource();
ods.setUser("stud");
ods.setPassword("stud");
ods.setDriverType("thin");
ods.setDatabaseName("stud");
ods.setServerName("localhost");
ods.setPortNumber(1521);
Connection conn = ods.getConnection();
Методы и их количество могут отличаться от драйвера к драйверу
Здесь thin - тип драйвера. Всего существуют 4 типа:
- Первый тип (Type-1) или JDBC-ODBC bridge driver
- Второй тип (Type-2) или Native-API driver
- Третий тип (Type-3) или Network Protocol driver
- Четвертый тип (Type-4) или Thin driver
Если нужно обратиться к одному типу базы данных, предпочтительным типом драйвера является Type-4.
Если Java-приложение обращается к нескольким типам баз данных одновременно, Type-3 является предпочтительным драйвером.
Драйверы Type-2 полезны в ситуациях, когда драйвер Type-3 или Type-4 еще недоступен для вашей базы данных.
Драйвер Type-1 обычно используется только при разработки и тестирования.
Зачастую пользоваться JDBC неудобно, так как все запросы становятся хардкодом, а Java-разработчики могут не знать SQL. Поэтому появился JPA
Java Persistence API
Java Persistence API - спецификация, описывающая систему управления сохранением Java объектов в таблицы реляционных баз данных в удобном виде. Сама Java не содержит реализации JPA, однако есть существует много реализаций данной спецификации от разных компаний.
Заметим, что JPA - это не единственный способ сохранения Java-объектов в базы данных (Object-Relational-Model-систем), но один из самых популярных.
Hibernate - одна из самых популярных открытых реализаций JPA версии 2.1. Далее будем рассматривать ее, как реализацию JPA
Чтобы объявить персистентную сущность, объявим ее аннотацией @Entity
@Entity
// явно указываем, из какой таблицы принадлежит сущность
@Table(name = "users")
public class User {
// говорим, что id - это первичный ключ, который будет генерироваться сам
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// указываем, что имя столбца отличается от имени атрибута
@Column(name = "user_name")
private String name;
// связь многие-к-одному
@ManyToOne
@JoinColumn(name = "countries")
private Country country;
// геттеры, сеттеры, другие методы
}
По умолчанию, Hibernate будет искать сущести в базе данных по их именам атрибутов (то есть переводя camelCase полей классов в snake_case атрибутов базы данных)
Далее сущности указываются в так называемой единице персистентности (persistence unit) в файле resources/META-INF/persistence.xml:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<!-- Здесь myunit - название группы сущностей -->
<persistence-unit name="myunit">
<description>
Описание
</description>
<!-- Здесь перечисляются сущности -->
<class>org.example.models.User</class>
<properties>
<!-- Данные для подключения -->
<!-- Здесь в качестве примера СУБД PostgreSQL и база данных с именем cats, находящаяся на localhost -->
<property name="hibernate.connection.driver_class" value="org.postgresql.Driver" />
<property name="hibernate.connection.url" value="jdbc:postgresql://localhost:5432/cast" />
<property name="hibernate.connection.username" value="${POSTGRES_USERNAME}" />
<property name="hibernate.connection.password" value="${POSTGRES_PASSWORD}" />
<!-- Настройка миграции -->
<property name="hibernate.hbm2ddl.auto" value="X" />
<!-- Вместо X подставить нужное значение:
validate - проверяет, что схема базы данных соответствует объектной модели, но не делает никаких изменений
update - обновляет схему с сохранением данных
create - создает схему, удаляя предыдущие данные
create-drop - создает схему, удаляя предыдущие данные, а также удаляет схему к концу сессии
-->
</properties>
</persistence-unit>
</persistence>
А чтобы работать с ними, используют EntityManager:
// Создаем EntityManager
EntityManagerFactory emf = Persistence.createEntityManagerFactory("myunit");
EntityManager em = emf.createEntityManager();
// Поиск по идентификатор
User user = em.find(User.class, 1L);
System.out.println(user.getName());
// JPQL-запрос
TypedQuery<User> query = em.createQuery(
"SELECT u FROM User u WHERE u.name LIKE 'A%'", User.class);
List<User> users = query.getResultList();
// Закрываем сессию
em.close();
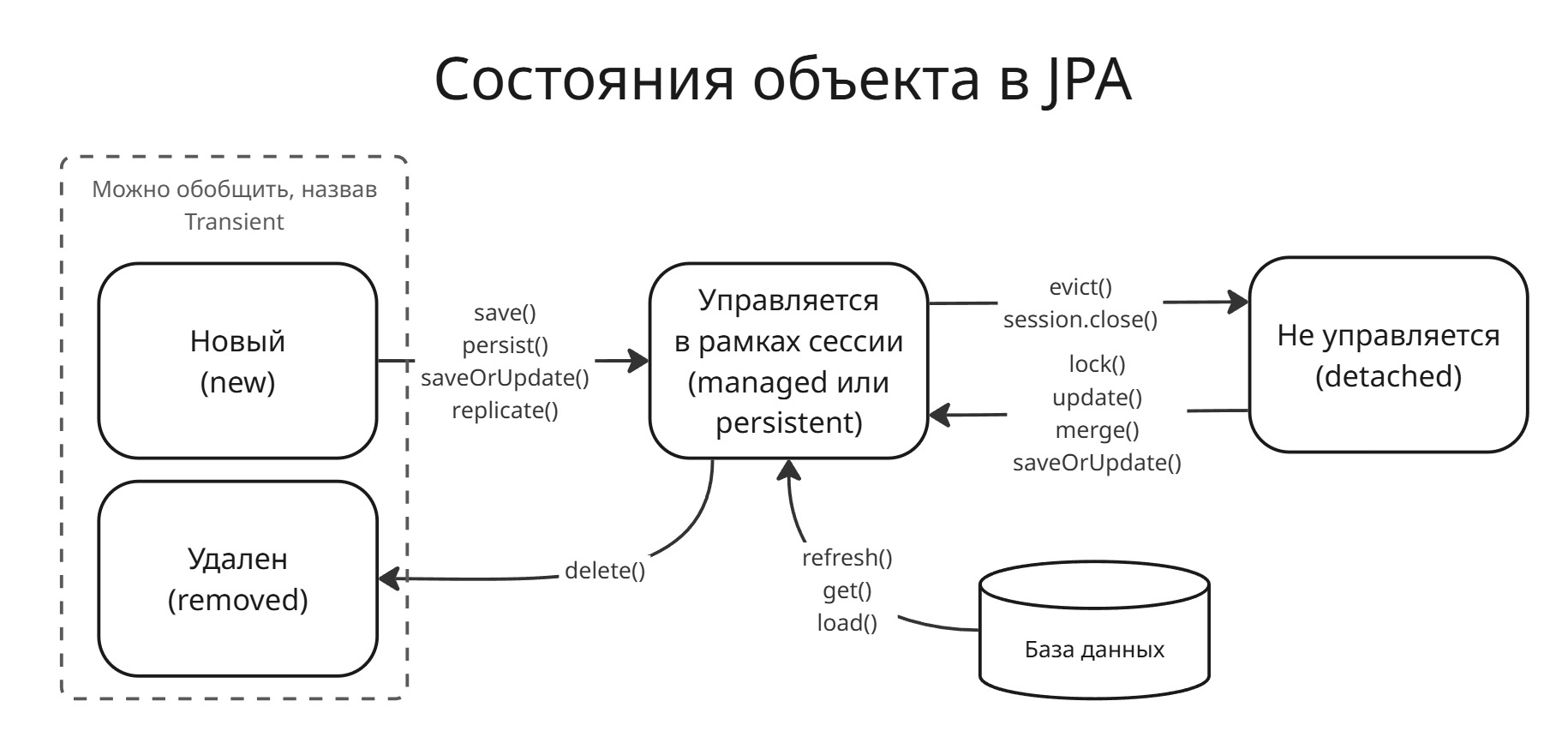
Сущности, включенные в JPA, имеют свое состояние:
- Новый объект - объект, созданный с помощью
new, но еще не имеет сгенерированный ключей и не хранится в базе данных - Удаленный объект - объект, который будет удален из базы данных после совершения транзакции
- Управляемый объект - объект, который управляется JPA
- Отсоединенный объект - объект, который существует в базе данных, но который не управляется JPA