itmo_conspects
Лекция 9. Индекс
Индекс - объект базы данных, предназначенные для ускорения поиска и выборки строк из таблицы. Помимо этого индексы могут служить для поддержания некоторых ограничений целостности
Индекс устанавливает соответствие между ключом (например, значением проиндексированного столбца) и строками таблицы, в которых этот ключ встречается. Строки идентифицируются с помощью TID (Tuple ID), который состоит из номера блока файла и позиции строки внутри блока
Несмотря на то, что индекс ускоряет поиск записи внутри таблицы (а также выборку, сортировку, агрегирование), изменение записей (а также создание новой, удаление и другие) в таблице требует перестройку индекса
Индекс может быть реализован как:
-
B-дерево
-
Хеш-таблица
-
GiST (Generalized Search Tree)
-
BRIN (Block Range INdex)
Хеш-индекс
Хеш-функция - функция, преобразующая массив входных данных произвольного размера в выходную битовую строку определённого (установленного) размера в соответствии с определённым алгоритмом
Так как хеш-функция может дать все, что угодно, то единственная операция, которую поддерживает хеш-индекс, - поиск по условию равенства
Хеш-индекс устроен так:
-
Изначально есть одна корзина, в которую складыываются все кортежи
-
После того, как она достигнет определенного размера, она делится на две части: в первую складываются кортежи с хеш-ключом, оканчивающимся на 0, во вторую на 1
-
По мере их увеличения они снова делятся пополам, и дальше смотрятся последние 2 бита и так далее
Элементы корзин упорядочены по хеш-кодам ключей, а подходящие идентификаторы эффективно находятся двоичным поиском
До версии PostgreSQL 10 хеш-индексы не журналировались
Недостатки: кластеризация таблицы по хешу нет, упорядочить кортежи нельзя, а также не работает с null-атрибутами
B-дерево
B-дерево - сбалансированное дерево поиска
B-деревом называется дерево, удовлетворяющее следующим свойствам:
- Ключи в каждом узле обычно упорядочены для быстрого доступа к ним.
Корень содержит от
1до2t-1ключей. Любой другой узел содержит отt-1до2t-1ключей. Листья не являются исключением из этого правила. Здесьt- параметр дерева, не меньший2(и обычно принимающий значения от50до2000). -
У листьев потомков нет. Любой другой узел, содержащий ключи
K_1, …,K_n, содержитn+1потомков. При этом- Первый потомок и все его потомки содержат ключи из интервала
(-∞,K_1) - Для
2 ≤ i ≤ n,i-й потомок и все его потомки содержат ключи из интервала(K_{i-1},K_i), (n+1)-й потомок и все его потомки содержат ключи из интервала(K_n, ∞)
- Первый потомок и все его потомки содержат ключи из интервала
- Глубина всех листьев одинакова.
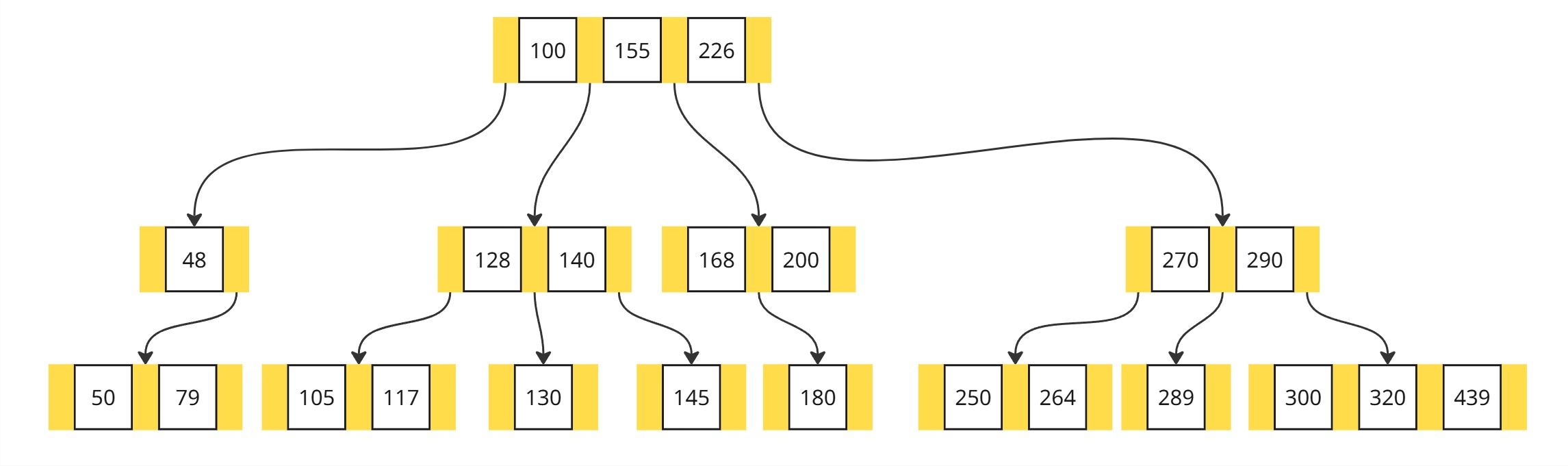
Каждый узел дерева содержит несколько элементов, состоящих из ключа индексирования и ссылки
B-дерево является очень распространенным
GiST (Generilized Search Tree)
GiST - фреймворк, который позволяет создавать пользовательские реализации для различных видов данных
Например: для географических данных, полнотекстового поиска, интервалов, деревьев
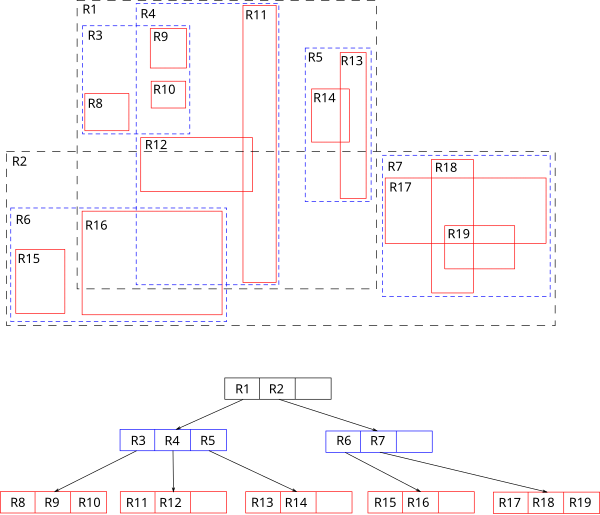
GiST реализует B-дерево, R-дерево и другие деревья
Идея R-дерева состоит в том, что плоскость разбивается на прямоугольники, которые в сумме покрывают все индексируемые точки
Индексная запись хранит ограничивающий прямоугольник, а предикат можно сформулировать так: точка лежит внутри данного ограничивающего прямоугольника
Также GiST используется для выбора из набора документов те, которые соответствуют поисковому запросу (то есть полнотекстовый поиск, Full Text Search). Чтобы полнотекстовый поиск работал быстро, его нужно поддержать индексом. Поскольку индексируются не сами документы, а значения типа tsvector, есть два варианта: построить индекс по выражению, с приведением типа, или создать отдельный столбец типа tsvector и индексировать его
GIN (Generalized Inverted Index)
GIN — это обобщённый инвертированный индекс. Он строит обратную карту: ключ → список документов (или позиций). Применяется там, где у одной записи много значений, каждое из которых нужно индексировать. GIN используется для полнотекстового поиска, индексации массивов, индексации JSONB