itmo_conspects
Лекция 10. Распределенные хранилища
Зачем нам нужны распределенные хранилища? Есть 3 причины:
-
Посмотрим на File-Server архитектуру: в ней мы выделили недостаток с тем, что файл блокируется при попытке доступа к нему. Тогда мы сделали прослойку “Приложение”, к которому обращаются наши клиенты.
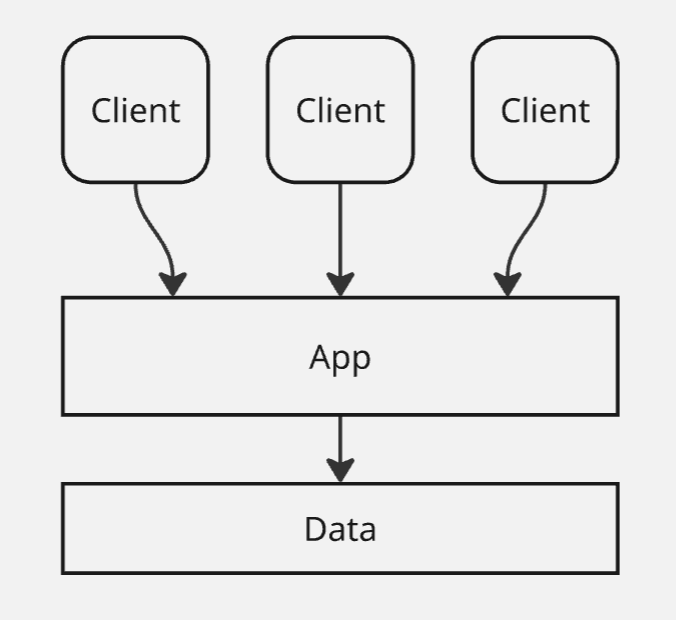
В этом случае приложение становится бутылочным горлышком. Тогда мы можем разделить слой приложения на несколько узлов:
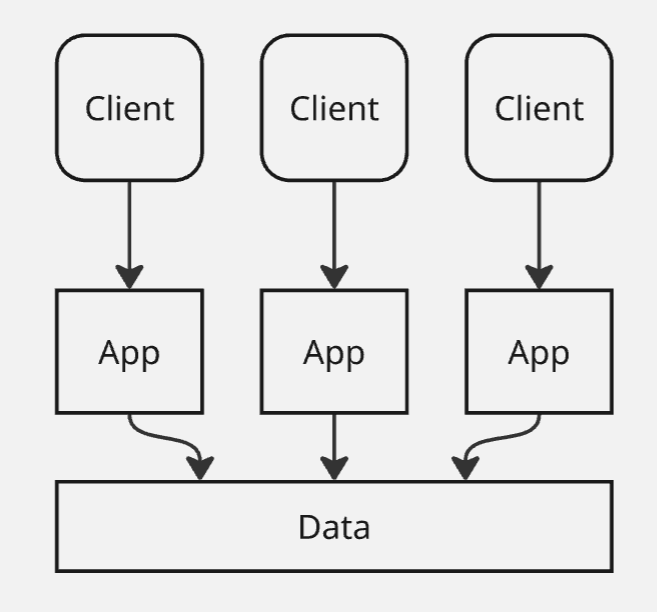
Здесь, как гласит еврейская пословица:
Если проблему можно решить деньгами, то это не проблема, а затраты
мы можем просто купить просто много серверов, которые будут хостить бэкенд. Проблемы начинаются на слое с данными - все узлы приложения подключаются к нему, и дальше он становится узким местом
-
Хорошо, так как мы не можем уменьшить количество транзисторов на чипе из-за физики, мы можем купить огромный сервер и поставить туда огромные плашки памяти.
Возникает проблема: подводя к серверу N кВт, мы должны эти N кВт в виде тепла отвести от сервера, иначе полупроводники расплавятся.
Так как затраты энергии возрастают экспоненциально, мы не можем сделать огромный компьютер, но можем сделать много маленьких
-
Естественная распределенность данных: зачем хранить данные про питерский склад маркетплейса в центральном сервере в Москве? Не проще ли их хранить там, где они непосредственно нужны.
В случае маркетплейса мы не можем клиентскую базу разделить на какие-то части, но данные логистики мы можем разделить так, чтобы они действовали в едином информационном поле
Получается, что нам надо сделать распределенную систему:
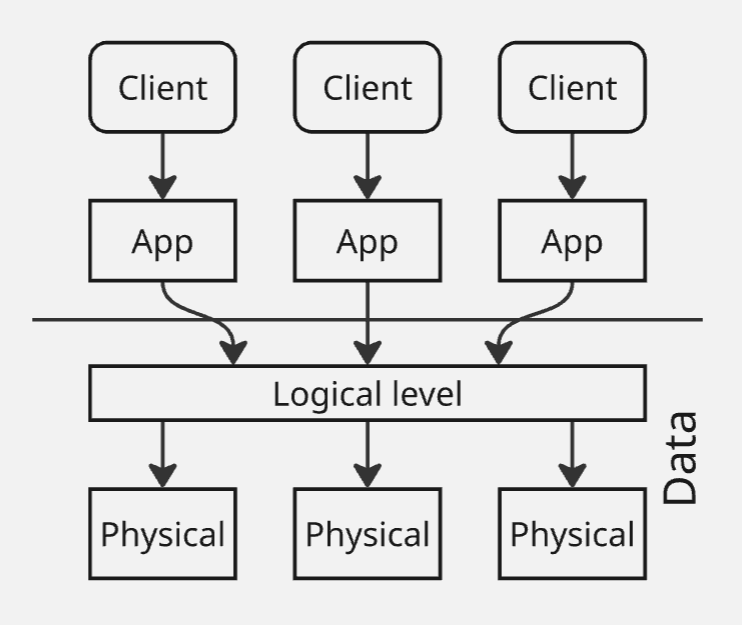
Распределенная база данных - набор логически связанных между собой разделяемых данных и их описаний, которые физически располагаются на нескольких вычислительных узлах распределительной сети
Как же это сделать? Мы можем распологать таблицы по разным узлам, но тогда сделаем операцию JOIN еще медленнее.
Но мы можем сделать с табличками фрагментацию
-
Горизонтальную (также партиционирование) - храним одни строки на одном узле, другие строки на другом
-
Вертикальную - храним одни столбцы с первичным ключом в одном узле, другие столбцы + пк в другом (достаточно редко применяют, сложнее в этом случае соблюдать целостность)
-
Смешанную - храним “квадратики” из таблицы
Также мы можем применять репликацию. Реплика - копия объекта, для которого поддерживается синхронизация с исходным объектом
Есть 3 стратегии репликации
-
Раздельное размещение: каждый фрагмент хранится в единственном экземпляре
- медленный узел становится слабым местом
+ не надо поддерживать целостность
-
Размещение с полной репликацией: все фрагменты данных реплицируются на всех узлах
- надо поддерживать целостность
+ надежность (умер один узел, данные есть на других)
-
Размещение с выборочной репликацией: реплицируем какие-то востребованные данные
- нужно думать, что куда реплицировать
+ оптимально👍
Здесь мы приходим к определению распределенной СУБД
Распределенная СУБД - комплекс программ, предназначенный для управления базой данных и позволяющий сделать распределенность информации прозрачной для конечного пользователя
“Прозрачная” в определении означает, что распределенная база данных ощущается как единое целое. Тут можно выделить 4 уровня прозрачности:
-
Прозрачность фрагментации: не знаем, как сделаны фрагменты
-
Прозрачность расположения объектов: не знаем, где они расположены
-
Прозрачность количества реплик: не знаем, сколько их
-
Прозрачность контроля доступа: не знаем, как устроен контроль доступа к данным
Распределенные баз данных бывает:
-
гомогенными - узлами управляет одна субд
-
гетерогенными - на узлах разные субд
Дальше Дейт конкретизировал требования прозрачных СУБД, вышло 12 правил:
-
Локальная автономность: локальные данные принадлежат локальным владельцам и сопровождаются локально (данные не могут передаваться горизонтально)
-
Отсутствие опоры на центральный узел: в системе не должно быть ни одного узла, без которого не может функционировать система
-
Непрерывное функционирование: в системе не должна возникать потребность в плановой остановке ее функционирования
-
Независимость от расположения фрагментов: пользователь должен получать доступ, начиная с текущего узла
-
Независимость от репликации
-
Независимость от фрагментации
-
Обработка распределенных запросов: система должна поддерживать обработку запросов с данными, расположенных более чем на одном узле
-
Обработка распределенных транзакций: система должна поддерживать обработку транзакций с данными, расположенных более чем на одном узле, включая необходимые блокировки
-
Независимость от типа оборудования
-
Независимость от сетевой архитектуры
-
Независимость от операционной системы
-
Независимость от типа СУБД
И при составлении запроса к распределенном СУБД нужно знать ответы на такие вопросы:
-
К какому фрагменту нужно обратиться?
-
Какую реплику необходимо использовать?
-
Какое из местоположений должно использоваться для тех или иных структур, какие данные и в каком порядке их хранить и перемещать?
И здесь возникают проблемы с распределенными транзакциями: пусть есть 2 реплики одного фрагмента, одна транзакция пишет что-то в одну реплику, из-за этого она блокируют к чтению все реплики, но в это время вторая транзакция пишет что-то во вторую реплику, которая еще не успели заблокировать. Тогда придумали 2-фазное выполнение транзакции
1 фаза: любая транзакция пытается блокировать все ресурсы, которые ей понадобятся, если где-то не получается заблокировать, то предпринимается откат
2 фаза: выполняются изменения в базу данных
И чтобы решить все эти проблемы с реляционными базами данных приходят NoSQL решения, о которых будет следующая лекция