itmo_conspects
Лекция 5. Реляционная алгебра
Уже на протяжении выполнения лабораторных работ можно было столкнуться с теоретико-множественными операциями из реляционный алгебры,
например, JOIN. Причем, стоит заметить, что реляционная алгебра - замкнутая.
Операции реляционной алгебры
Операции, которые ввел Кодд в реляционной алгебре, делятся на унарные и бинарные
-
Проекция:
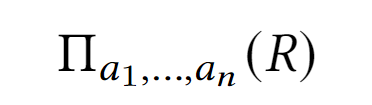
Результатом проекции является новое отношение, содержащее вертикальное подмножество исходного отношения, создаваемое посредством извлечения значений указанных атрибутов и исключения из результата строк-дубликатов
В SQL проекция реализована через инструкцию
SELECTи выбор определенных атрибутов -
Выборка
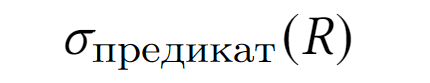
Результатом выборки является новое отношение, которое содержит только те кортежи из исходного отношения, которые удовлетворяют заданному предикату
В SQL выборка реализована через инструкцию
WHERE Condition -
Объединение (Union)

Объединение двух наборов кортежей определяет новое отношение, которое включает все кортежи из исходных отношений с исключением кортежей-дубликатов
Отношения совместимы, если они состоят из одинаковых атрибутов и каждая пара атрибутов имеет одинаковый домен
В SQL возможно сделать объединение так:
SELECT * FROM Table1 UNION SELECT * FROM Table2;Синтаксически такие запросы в SQL разрешены, но семантически они не имеют смысла. Приведем пример объединения на таблицах
Item:ItemID ItemName 1 Ball 2 Pen 3 Notebook И
FavouriteItem:ItemID ItemName 2 Pen 3 Notebook 4 Laptop Их объединение
SELECT * FROM Item UNION SELECT * FROM FavouriteItem;даст такое отношение:
ItemID ItemName 1 Ball 2 Pen 3 Notebook 4 Laptop -
Разность
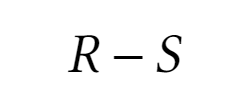
Разность отношений - новое отношение, которое включает кортежи из первого отношения и исключает кортежи, входящие во второе отношение
Аналогично, отношения, к которым применяется разность, должны быть совместимы
Разность отношений, приведенных выше:
SELECT * FROM Item EXCEPT SELECT * FROM FavouriteItem;даст такое отношение:
ItemID ItemName 1 Ball -
Пересечение
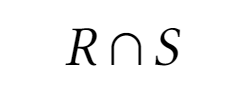
Пересечение определяет новое отношение, которое включает кортежи, входящие в обои отношения одновременно
Аналогично, отношения, к которым применяется пересечение, должны быть совместимы
Пересечение отношений, приведенных выше:
SELECT * FROM Item INTERSECT SELECT * FROM FavouriteItem;даст такое отношение:
ItemID ItemName 2 Pen 3 Notebook
Дальше будут приводиться примеры операций на атрибуте
DepartmentID(далееDepartID) на таблицахEmployee1:EmplID FullName DepartID 1 Albert Einstein 4 2 Ernest Rutherford 4 3 Marie Curie 10 4 Igor Kurchatov NULL 5 Alexander Fleming 13 И
Department:DepartID DepartName DirectorID 4 Theoretical Physics 1 10 Chemistry 3 11 Nuclear Physics 2 13 Biology 5
-
Декартовое произведение
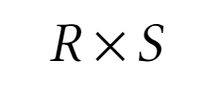
Результатом декартового произведения является новое отношение, в которой кортежи являются результатом конкатенации кортежей из первого отношения и кортежей из второго произведения
В SQL декартовое произведение можно сделать так:
SELECT * FROM Table1, Table2Либо так:
SELECT * FROM Table1 CROSS JOIN Table2Семантически декартовое произведение зачастую не имеет смысла. На таблицах выше декартовым произведением будет такое отношение:
EmplID FullName DepartID DepartID DepartName DirectorID 1 Albert Einstein 4 4 Theoretical Physics 1 2 Ernest Rutherford 4 4 Theoretical Physics 1 3 Marie Curie 10 4 Theoretical Physics 1 4 Igor Kurchatov NULL 4 Theoretical Physics 1 5 Alexander Fleming 13 4 Theoretical Physics 1 1 Albert Einstein 4 10 Chemistry 3 2 Ernest Rutherford 4 10 Chemistry 3 3 Marie Curie 10 10 Chemistry 3 4 Igor Kurchatov NULL 10 Chemistry 3 5 Alexander Fleming 13 10 Chemistry 3 1 Albert Einstein 4 11 Nuclear Physics 2 2 Ernest Rutherford 4 11 Nuclear Physics 2 3 Marie Curie 10 11 Nuclear Physics 2 4 Igor Kurchatov NULL 11 Nuclear Physics 2 5 Alexander Fleming 13 11 Nuclear Physics 2 1 Albert Einstein 4 13 Biology 5 2 Ernest Rutherford 4 13 Biology 5 3 Marie Curie 10 13 Biology 5 4 Igor Kurchatov NULL 13 Biology 5 5 Alexander Fleming 13 13 Biology 5 -
Тета-соединение
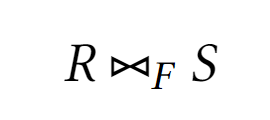
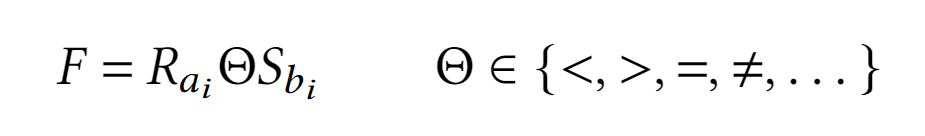
Результатом тета-соединения является декартовое соединение, кортежи которого удовлетворяют предикату
FТета-соединение осуществимо в SQL с помощью инструкции
FROM Table1 FULL JOIN Table2 ON Condition -
Эквисоединение
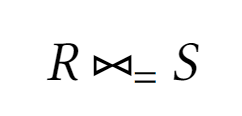
Результатом эквисоединения является декартовое соединение, кортежи которого равны по какому-либо атрибуту
Эквисоединение двух таблиц из примера будет таким результатом:
EmplID FullName DepartID DepartID DepartName DirectorID 1 Albert Einstein 4 4 Theoretical Physics 1 2 Ernest Rutherford 4 4 Theoretical Physics 1 3 Marie Curie 10 10 Chemistry 3 5 Alexander Fleming 13 13 Biology 5 SELECT * FROM Employee INNER JOIN Department ON Employee.DepartmentID = Department.DepartmentID; -
Естественное соединение (Natural Join)
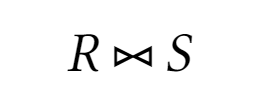
Естественное соединение - эквисоединение двух отношений, выполненное по всем общим атрибутам, из результатов которого исключается по одному экземпляру общего атрибута
Естественное соединение удобно, например, когда есть два таблицы с атрибутами серии и номера паспорта. В SQL естественное соединение напрямую не реализовано, но естественное соединение таблиц из примера выглядело бы так:
EmplID FullName DepartName DirectorID 1 Albert Einstein Theoretical Physics 1 2 Ernest Rutherford Theoretical Physics 1 3 Marie Curie Chemistry 3 5 Alexander Fleming Biology 5 -
Левое внешнее соединение
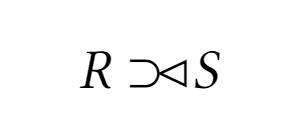
Соединение, результирующее отношение которое содержит в себе все кортежи из отношения R, с конкатенации к ним тех кортежей из отношения из S, имеющих совпадающие значения в общих атрибутах
В SQL левое внешнее соединение на таблицах выше осуществляется так:
SELECT * FROM Employee LEFT JOIN Department ON Employee.DepartmentID = Department.DepartmentID;EmplID FullName DepartID DepartID DepartName DirectorID 1 Albert Einstein 4 4 Theoretical Physics 1 2 Ernest Rutherford 4 4 Theoretical Physics 1 3 Marie Curie 10 10 Chemistry 3 4 Igor Kurchatov NULL NULL NULL NULL 5 Alexander Fleming 13 13 Biology 5 Аналогично в SQL можно сделать правое внешнее соединение:
SELECT * FROM Employee RIGHT JOIN Department ON Employee.DepartmentID = Department.DepartmentID;EmplID FullName DepartID DepartID DepartName DirectorID 1 Albert Einstein 4 4 Theoretical Physics 1 2 Ernest Rutherford 4 4 Theoretical Physics 1 3 Marie Curie 10 10 Chemistry 3 NULL NULL NULL 11 Nuclear Physics 2 5 Alexander Fleming 13 13 Biology 5 -
Полусоединение
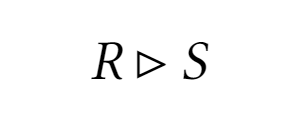
Полусоединение - отношение, состоящее из кортежей R, которые входят в экви-соединение R и S
В SQL полусоединение не реализовано2
Синтаксис SELECT
Рассмотрим запрос выборки в SQL - его можно разделить на 5 частей:
-
Выбор столбцов отношения:
SELECT [ DISTINCT | ALL ] { * | [ColumnExpression [AS NewName] ] [, ...]}Ключевое слово
DISTINCTопределяет выбор только уникальных кортежей,ALL- явный выбор кортежей с дубликатамиДалее указываются имена столбцов (также возможны их алиасы) или
*, которая определяет вывод всех столбцов отношения -
Выбор исходного отношения:3
FROM TableName [AS NewTableName] [{INNER | LEFT OUTER | FULL} JOIN OuterTable [AS NewOuterTableName] ON Condition]Здесь же можно определить соединение и его тип на основе условия
Condition -
Фильтрация кортежей:
[WHERE Condition]В инструкции
WHEREопределяются условия для фильтрации кортежей -
Группировка:
[GROUP BY ColumnList [, ...] [HAVING Condition]]В инструкции
GROUP BYпроизводится группировка по указанному набору атрибутов и фильтрации через условие вHAVING -
Сортировка:
[ORDER BY ColumnList [, ...] [{ASC | DESC}]]И, наконец, в инструкции
ORDER BYпроисходит сортировка конечного отношения по указанному набору атрибутов
В конечном счете, получаем:
SELECT [ DISTINCT | ALL ] { * | [ColumnExpression [AS NewName] ] [, ...]}
FROM TableName [AS NewTableName]
[{INNER | LEFT OUTER | FULL} JOIN OuterTable [AS NewOuterTableName]
ON Condition]
[WHERE Condition]
[GROUP BY ColumnList [, ...] [HAVING Condition]]
[ORDER BY ColumnList [, ...] [{ASC | DESC}]]
Здесь стоит заметить, что желательно общие условия, которые имеют место в инструкции WHERE стоит размещать именно там, а не в HAVING, так как фильтрация кортежей после группировки работает медленнее и не обеспечивает производительность
Порядок выполнения инструкций в SELECT запросе таков:
FROMONJOINWHEREGROUP BYHAVINGSELECTDISTINCTORDER BY
Рассмотрим две реализации JOIN:
-
Наивная:
for r in R: for s in S: if r.a_i Θ S.b_i: print(r + s) -
Слиянием:
R.sort(a) S.sort(b) while not endof(R) and not endof(S): if R.a_i < S.b_i: next(R) if R.a_i > S.b_i: next(S) if R.a_i == S.b_i: print(r + s) next(R)
Обе реализации имеют свои достоинства и недостатки. Но так как SQL хранит кортежи уже отсортированными (чтобы поддерживать быстроту индексации), вторая реализация зачастую работает лучше
В конечном итоге, мы приходим к мысли, что, чтобы поддерживать целостность данных, приходится тратить много средств на сервера и жертвовать производительностью, и в бизнесе намного дешевле содержать ошибки из-за нарушения целостности, чем создавать идеальные системы
-
Таблицы из примера были созданы так:
CREATE TABLE Employee ( EmployeeID BIGINT PRIMARY KEY, FullName TEXT, DepartmentID BIGINT ); CREATE TABLE Department ( DepartmentID BIGINT PRIMARY KEY, DepartmentName TEXT, DirectorID BIGINT ); INSERT INTO Employee VALUES (1, 'Albert Eistein', 4), (2, 'Ernest Rutherford', 5), (3, 'Marie Curie', 10), (5, 'Charles Darwin', 13), (4, 'Igor Kurchatov', NULL); INSERT INTO Department VALUES (4, 'Theoretical Physics', 1), (10, 'Chemistry', 3), (13, 'Biology', 5), (11, 'Nuclear Physics', 2); -
Несмотря на это, полусоединение можно реализовать в SQL при помощи
INNER JOIN:SELECT * FROM Employee INNER JOIN Department ON Employee.DepartmentID = Department.DepartmentID;На отношениях из примера получится такое полусоединение:
EmplID FullName DepartID DepartID DepartName DirectorID 1 Albert Einstein 4 4 Theoretical Physics 1 2 Ernest Rutherford 4 4 Theoretical Physics 1 3 Marie Curie 10 10 Chemistry 3 5 Alexander Fleming 13 13 Biology 5 -
На самом деле синтаксис инструкции
FROMнемного шире:FROM TableName [AS NewTableName] [{INNER | { LEFT | RIGHT | FULL } [OUTER]} JOIN OuterTable [AS NewOuterTableName] ON Condition]