itmo_conspects
Лекция 2. Абстрагирование данных
Откуда появилась идея абстрагирования данных? Сначала все началось с архитектуры фон Неймана, где появилась однородность памяти - концепция хранения данных и инструкций в одном месте. Потом появилась первая абстракция данных - хранение в файле. Если же в оперативной памяти читаемость не нужна, то в постоянной она необходима для упрощенной работы - будь-то имя файла и имя каталога. И так появляется файло-серверная архитектура:
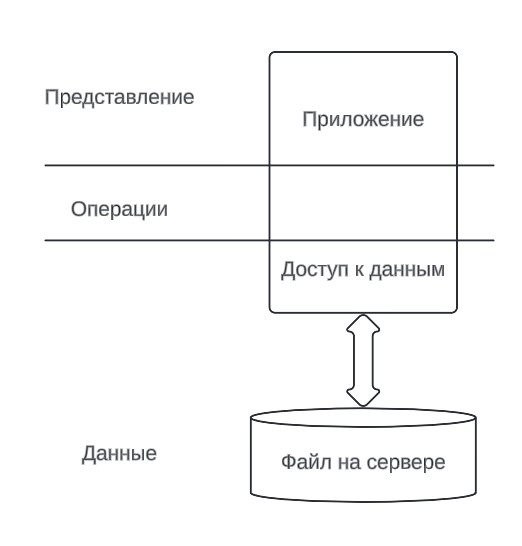
Все хорошо, но что, если приложений будет N? Каждое из них будет блокировать этот файл, таким образом можно соблюдать целостность данных, но файл становиться большим и нельзя поддерживать параллельный доступ (эффект конкурентных транзакций), падает производительность
Можно хранить несколько файлов, каждый из них хранящий группу данных (например: студенты, группы, факультеты), но все равно почти все запросы запрашивают те комбинации файлов, которые так или иначе пересекутся
Можно воспользоваться позиционированием - разбиением данных на группы (студентов на факультеты), но возникают другие проблемы: студенты мигрируют между факультетами, другие студенты ходят на занятия других факультетов
При этом данные растут, а если фрагментировать данные, то придется переписывать логику кода, что не является хорошей идеей. Да и к тому же возникает противоречие скоростей записи и чтения: нельзя обеспечить одинаково быстрые запись и чтение
В итоге появляется клиент-серверная архитектура, появляется СУБД (Система Управления Базой Данных) и моделирование данных, из-за чего мы избавляемся от привязанности к определенному формату файла
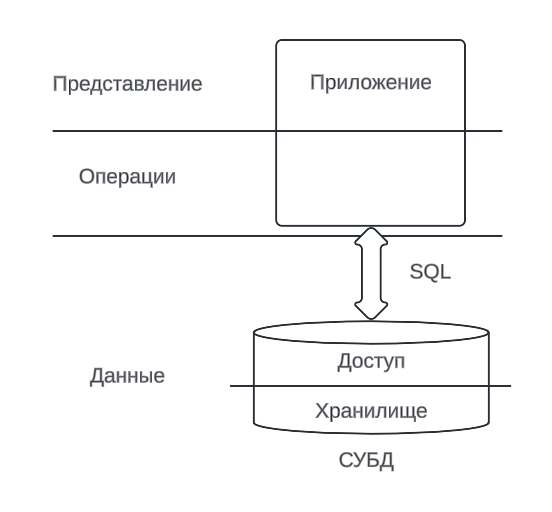
Появляется целостность данных, которая контролируется СУБД, и повышается производительность в следствие группировки запросов по времени и другим параметрам. Появляются правила моделирование бизнес-сущностей.
Но в чем состоит идея моделирования: выделение значимых аспектов у сущностей и для разных целей формирование различного моделирования
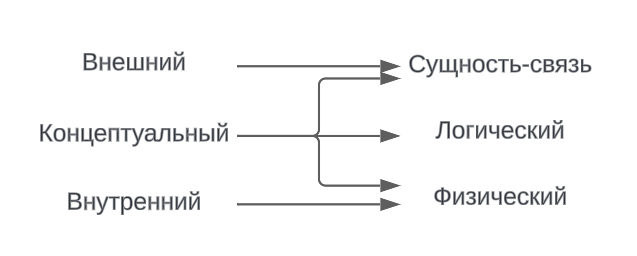
Выделяют 2 основания классификаций:
- Трехуровневая архитектура (ANSI/SPARC):
- Внешний
- Концептуальный
- Внутренний (физический, исходный)
Внешний уровень определяет базу данных с точки зрения конечного пользователя, например: для студофиса важно знать возраст определенного студента, но хранить возраст не удобно
Концептуальный уровень - на этом уровне накладываются ограничения на данные, определяются сущности и атрибуты, семантика данных (например: рейтинг компании на внешнем уровне может быть Excellent, Good, …, а на концептуальном 5, 4, … для упрощенной группировки)
Внутренний уровень - то, что организует производительность, безопасность, структуру файлов, шифрование и ограниченный доступ к щекотливым данным
- И уровни моделей данных:
- Сущность-связь
- Логический (дата-логический) уровень
- Физический уровень
Сущность-связь (ER, Entity-Relation) - абстрагирование объектов, появление связей
Логический уровень - то, как мы пытаемся описать сущность-связь, выделив какие-то формальные множества
Физический уровень - выбор СУБД на основе логического уровня (ограничения на типы данных, производительность, безопасность)
В конце концов появляется вот такой граф:
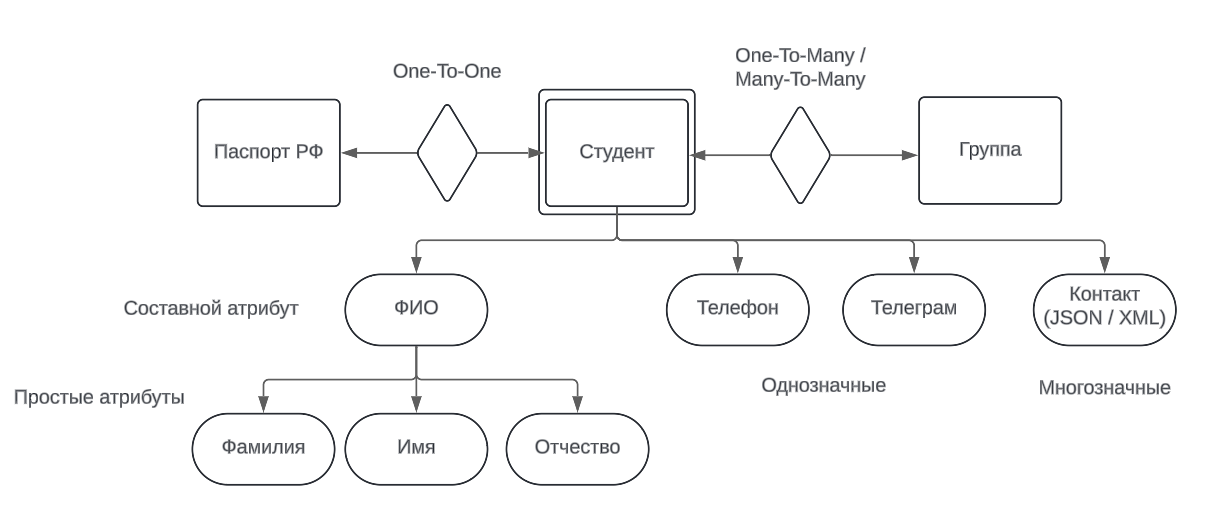
Сущность - множество экземпляров, реальных или абстрактных, однотипных объектов предметной области
Выделяют 2 типа сущности: сильная и слабая
Студент - сильная сущность, потому что может существовать без других
Группа - слабая сущность, потому что не может существовать без студентов (но группа может быть и сильной сущностью)
Также у сущностей могут быть атрибуты
- Составные, например, ФИО
- Простые, например, Фамилия и Имя по отдельности
А также:
- Однозначными - хранят одно значение, например, телефон
- Многозначными - хранят не меньше одного значения, например, контакт, хранящий JSON-объект с множеством телефонов
Появляются 3 вида связи:
-
One-To-One: студент
-<>-паспорт (1<->1) (паспорт можно выделить в отдельную сущность, чтобы ограничить к нему доступ) -
One-To-Many: группа
-<>-студент (1<->N) -
Many-To-Many: группы
-<>-студенты (M<->N)
Получается такая картинка в нотации Чена: