itmo_conspects
Лекция 6. Сегментация изображений и обработка видеопотока
Сегментация изображений
Задача сегментации изображений заключается в разбиении изображения на области и в присвоении пикселям меток классов или конкретных объектов
Выделяют несколько постановок задачи:
- Семантическая сегментация (Semantic Segmentation) - каждому пикселю сопоставляется класс объекта, но разные объекты одного класса не разделяются
- Сегментация сущностей (Instance Segmentation) - объекты одного класса разделяются на отдельные экземпляры
- Паноптическая сегментация (Panoptic Segmentation) объединяет семантическую сегментацию и сегментацию сущностей: каждый пиксель размечен, а объекты одного класса различаются между собой
В задачах сегментации сеть должна выдавать не один класс для всего изображения, а карту предсказаний того же или близкого пространственного размера, что и входное изображение
На последних слоях образуются карты активации классов. По ним можно понять, какие части изображения повлияли на предсказание и где модель ошибается
Чаще всего используют полносверточные сети (Fully Convolutional Networks, FCN). Обычно такая архитектура состоит из двух частей:
- Кодировщик (encoder или backbone) - последовательно извлекает признаки и уменьшает пространственное разрешение
- Декодировщик (decoder) - восстанавливает пространственное разрешение и строит карту сегментации
При уменьшении разрешения из-за пулинга и страйдов часть точной пространственной информации теряется. Поэтому при восстановлении разрешения часто используют соединения с пропуском (skip-connections): признаки из ранних слоев кодировщика передаются в декодировщик и помогают точнее восстановить границы объектов
Именно по такому принципу устроена U-Net. В ней:
- левая часть сети сжимает изображение и извлекает признаки
- правая часть постепенно восстанавливает разрешение
- на каждом уровне объединяются признаки кодировщика и декодировщика
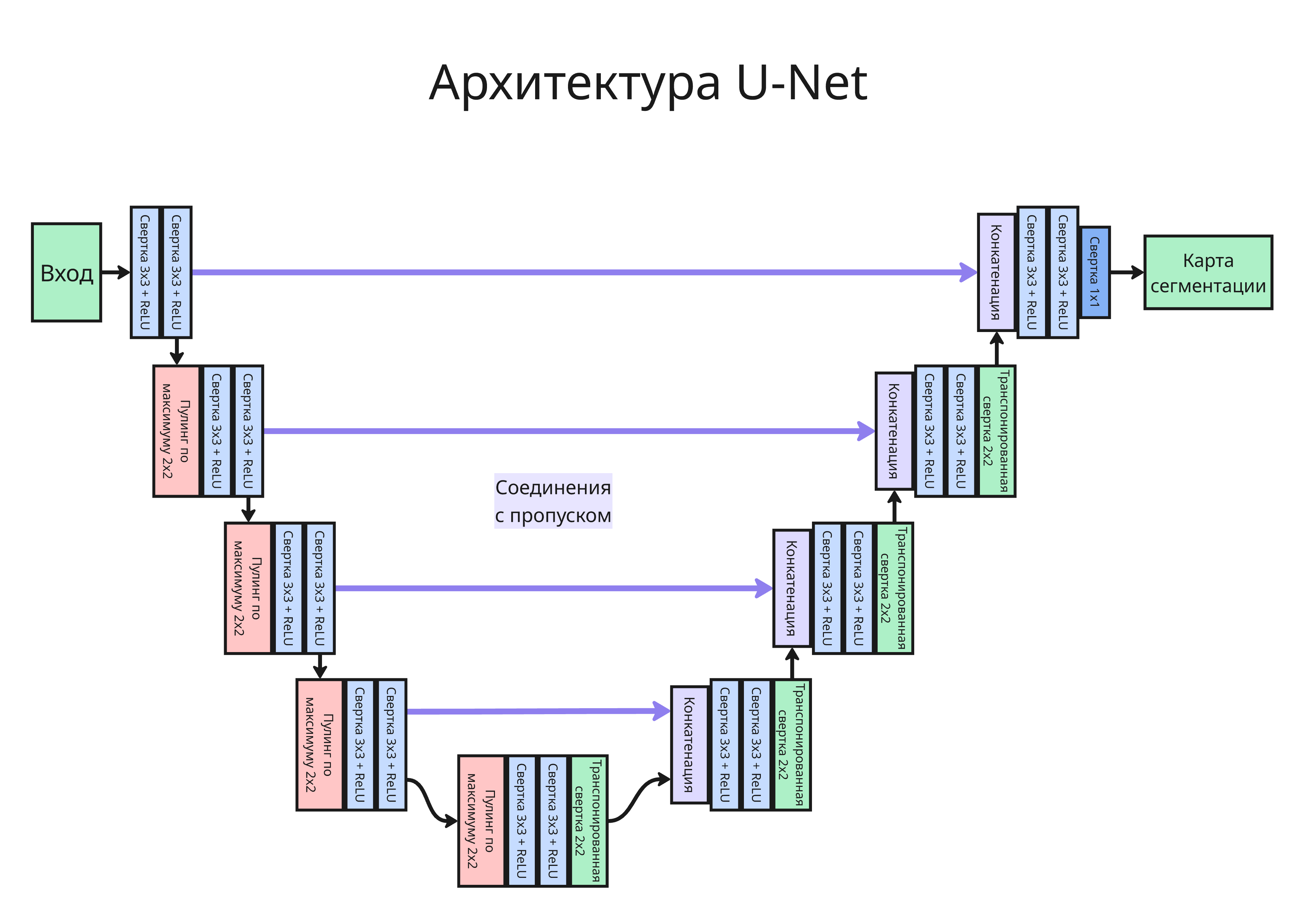
В качестве кодировщика могут использоваться обычные CNN, например ResNet
Для сегментации часто применяют следующие функции потерь:
- поклассовую кросс-энтропию
- Функцию потерь Dice, особенно если классы несбалансированы и важна точность масок
- комбинации кросс-энтропии и Dice Loss
Коэффициент Dice для бинарной сегментации можно записать так: $\mathrm{Dice} = \frac{2 \sum_{x, y} p_{x,y} t_{x,y}}{\sum_{x, y} p_{x,y} + \sum_{x, y} t_{x,y}}$, где $p_{x,y}$ - предсказание модели, а $t_{x,y}$ - истинная разметка
На основе U-Net появились различные модификации:
- Multi-Input U-Net - сеть с несколькими входами
- 3D U-Net - вариант для объемных данных, например результатов компьютерной томографии или МРТ
- RefineNet - архитектура с блоками уточнения признаков
Также существуют и другие семейства моделей:
- PSPNet (Pyramid Scene Parsing Network) - использует пирамидальный пулинг, чтобы учитывать контекст на нескольких масштабах
- DeepLab - использует расширенные свертки (dilated, atrous convolution), позволяющие увеличивать рецептивное поле без сильной потери разрешения
Расширенная свертка применяет ядро не к соседним пикселям подряд, а с промежутками. Это позволяет захватывать более широкий контекст, не увеличивая число параметров слишком сильно
Сегментация активно применяется:
- в автономном вождении
- в промышленности, например для обнаружения дефектов
- в медицине, например для выделения органов, сосудов и опухолей
- в робототехнике и анализе спутниковых снимков
Обработка видеопотока
Видео - это упорядоченная последовательность кадров одинакового разрешения, отображаемая с определенной частотой. Частота обычно измеряется в кадрах в секунду (Frames Per Second, FPS)
Обработка видео сложнее обработки одиночного изображения, потому что нужно учитывать:
- движение объектов и камеры
- размытие из-за движения
- изменения освещенности
- ограничение по скорости обработки, особенно в задачах реального времени
Обработка видеопотока позволяет решать такие задачи:
- распознавание объектов и лиц на видео
- трекинг объектов
- распознавание действий
- стабилизация и улучшение видео
- восстановление 3D-структуры сцены
Обычно обработка видео включает:
- декодирование видеопотока
- обработку кадров
- кодирование результата
Важно соблюдать баланс между точностью и скоростью, поскольку во многих задачах результат нужен в реальном времени.
Для ускорения моделей могут использоваться:
- дистилляция знаний - обучение компактной модели по предсказаниям более крупной
- квантование и pruning
- специализированные устройства, например GPU и TPU
Оптический поток
Одна из классических задач обработки видео - оценка оптического потока
Оптический поток - это поле векторов смещения пикселей между соседними кадрами. Для каждого пикселя или характерной точки оценивается, куда она переместилась на следующем кадре
Оптический поток применяют для:
- трекинга объектов
- стабилизации видео
- оценки движения камеры
- реконструкции 3D-сцены
- интерполяции кадров
Классический подход - метод Лукаса-Канаде. Его идея состоит в следующем:
- выбирается точка или небольшое окно вокруг точки на первом кадре
- на втором кадре ищется область, наиболее похожая на это окно
- смещение оценивается по максимуму сходства или из локальной линейной модели яркости
У такого подхода есть ограничения:
- поворот и деформация окна ухудшают качество сопоставления
- на изображении могут быть несколько похожих областей
- изменение освещенности нарушает предположение о сохранении яркости
- полный перебор слишком дорог по вычислениям
Для обучения нейросетевых моделей оптического потока используют, например, датасеты:
- Middlebury
- KITTI
- MPI Sintel
- Flying Chairs
В нейросетевых методах часто используют ошибку конечной точки (End-Point Error, EPE): $\mathcal{L} = \frac{1}{H W} \sum_{i = 1}^{H W} \vert \hat{u}_i - u_i \vert_2^2$, где $\hat{u}_i$ - предсказанный вектор смещения, а $u_i$ - истинный.
Примеры моделей для оценки оптического потока:
- FlowNet - одна из первых популярных сверточных моделей для этой задачи
- FlowFormer - более современная архитектура, использующая идеи transformer-подходов
Отслеживание объектов
Отслеживание объектов (Object tracking) - задача обнаружения и сопровождения объекта или нескольких объектов в видеопоследовательности с сохранением их идентичности между кадрами
Обычно в многообъектном трекинге на входе есть:
- множество детекций на каждом кадре
- координаты ограничивающего прямоугольника
- необходимость присвоить каждому объекту устойчивый идентификатор
Трекинг нужен потому, что:
- детектор может пропускать объект на отдельных кадрах
- важно понимать траекторию движения объекта
- во многих системах требуется работа в реальном времени
Во многих системах используются два основных шага:
- детекция объектов
- предсказание движения и сопоставление детекций между кадрами
SORT (Simple Online Realtime Tracking) - простой и быстрый алгоритм многообъектного трекинга. Основные шаги SORT:
- Детекция объектов на текущем кадре любым детектором, например YOLO или Faster R-CNN
- Предсказание новых положений уже известных объектов с помощью фильтра Калмана
- Сопоставление старых треков и новых детекций по IoU с использованием венгерского алгоритма
- Создание новых треков и удаление пропавших
Преимущество SORT - высокая скорость. Недостаток - зависимость почти только от геометрии движения
Далее появилась модификация DeepSORT (Deep Simple Online Realtime Tracking), которая расширяет SORT и использует не только движение, но и внешний вид объекта. Дополнительно:
- для каждого объекта извлекается эмбеддинг внешнего вида с помощью CNN
- сопоставление выполняется не только по IoU и предсказанному движению, но и по визуальному сходству
Это делает трекинг устойчивее при перекрытиях, пропаданиях детекций и сложных траекториях