itmo_conspects
Лекция 3. Основы глубокого обучения
Ключевым открытием в машинном обучении стало разработка архитектуры нейронных сетей
В человеческом мозге примерно 100 миллиардов нейронов, которые обмениваются сигналами
Человек распознает картинки с помощью множества областей в мозге. Сам нейрон выдает сигналы с частотой ~200 Гц в активированном состоянии, из-за чего мозг распознает изображение за ~200 мс, а также способен обучаться на малой выборке, благодаря пластичность (способности перестраиваться) мозга
Сейчас процессор компьютера работает с частотой 3-6 ГГц (на 7 порядков больше), что позволяется использоваться модели сетей из нейронов для решения задач с нетривиальной зависимостью
Сейчас предпринимается множество попыток смоделировать работу структур мозга. Ученые уже смогли построить трехмерную модель синапса, включающего 300 тысяч белков, с помощью которого нейроны общаются
Из курса математического анализа известно, что сколь угодно сложную функцию можно представить как композицию наиболее простых (например, преобразование Фурье), поэтому решать сложные задачи можно с помощью кучи нейронов
В 1943 году появилась модель нейрона МакКаллока-Питтса, в 1948 Алан Тьюринг высказал идею искусственных сетей, а в 1958 году Розенблатт разработал первый перцептрон - полносвязную нейросеть
В 1969 году Брисон и Хобэк разработали алгоритм обратного распространения, который применили в 1974 году к нейросетям, благодаря чему стало возможным обучение нейросети
В 1990-ых развитие пришло в тупик из-за слабых мощностей железа, но в 2000-ых появились графические ускорители, алгоритмы инициализации весов и регуляризации и так далее. С середины 2010-ых нейросети начали применятся в обработке текстов на естественном языке, что привело к созданию ChatGPT, Gemini, Grok и так далее
Нейрон в типичной нейронной сети представляет из себя линейную комбинацию значений на предыдущем слое и применение функции активации
Подробнее нейронные сети описаны в курсе машинного обучения
Вместо функции активации используют:
-
Функцию сигмоиды, использующаяся в задача логистической регрессии:
\[\sigma(x) = \frac{1}{1 + e^{-x}}\] -
Гиперболический тангенс:
\[\mathrm{tanh}(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}\] -
ReLU (Rectified Linear Unit):
\[\mathrm{ReLU}(x) = \begin{cases}0 & x < 0 \\ x & x \geq 0\end{cases}\] -
Leaky ReLU:
\[\mathrm{LeakyReLU}(x) = \begin{cases}\alpha x, & x < 0, \\ x, & x \geq 0,\end{cases}\] -
GELU (Gaussian Error Linear Unit), использующийся в моделировании языка:
\[\mathrm{GELU}(x) = x P(X \leq x) = x \Phi(x) \text{ , где } X \in N(0, 1)\]Обычно используют приближение $\mathrm{GELU}(x) = x \sigma(1.702 \cdot x)$
-
Softplus:
\[\mathrm{Softplus}(x) = \frac{1}{\beta} \log(1 + e^{\beta x})\] -
Swish:
\[\mathrm{Swish}(x) = x \sigma(\beta x) = \frac{x}{1 + e^{-\beta x}}\]
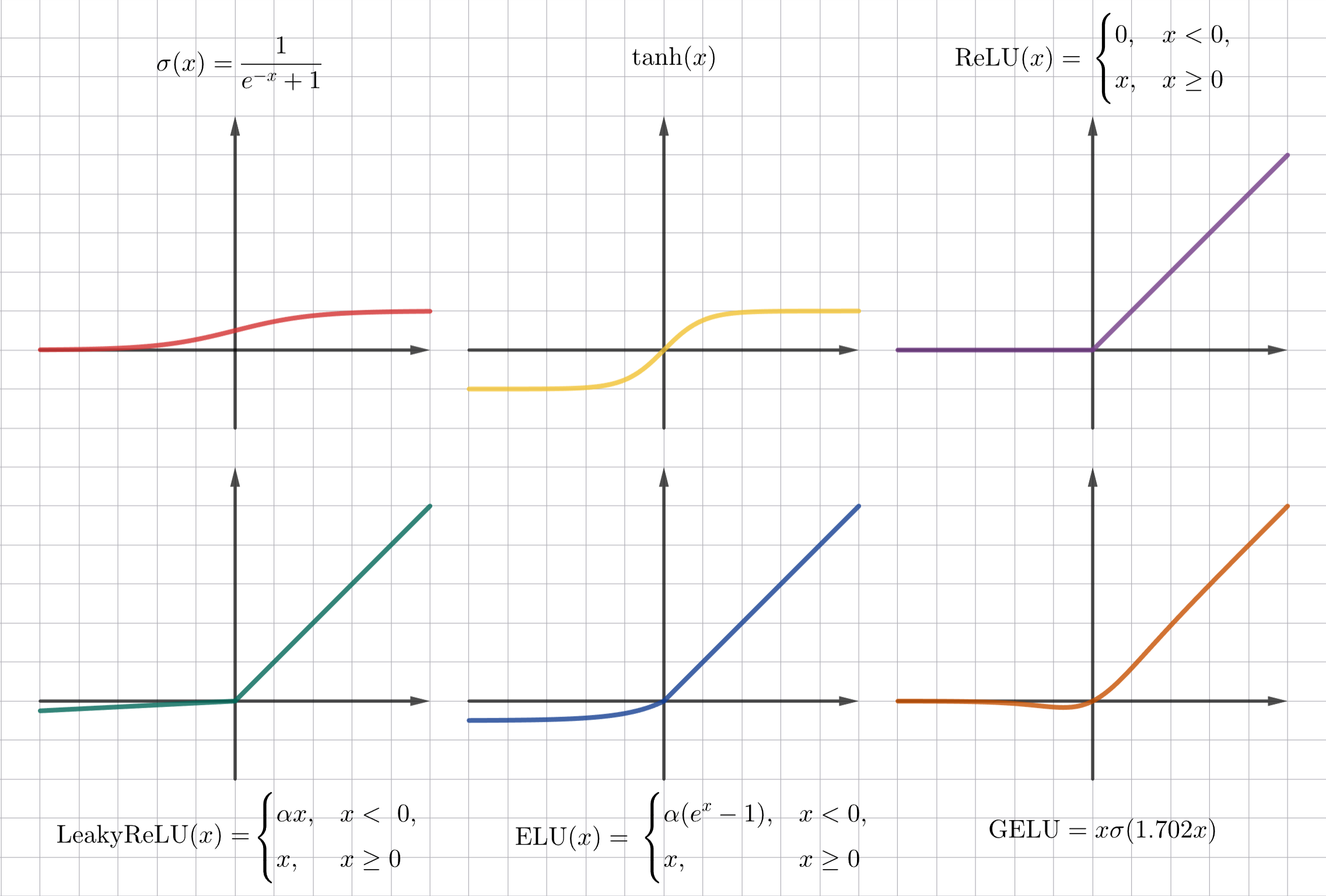
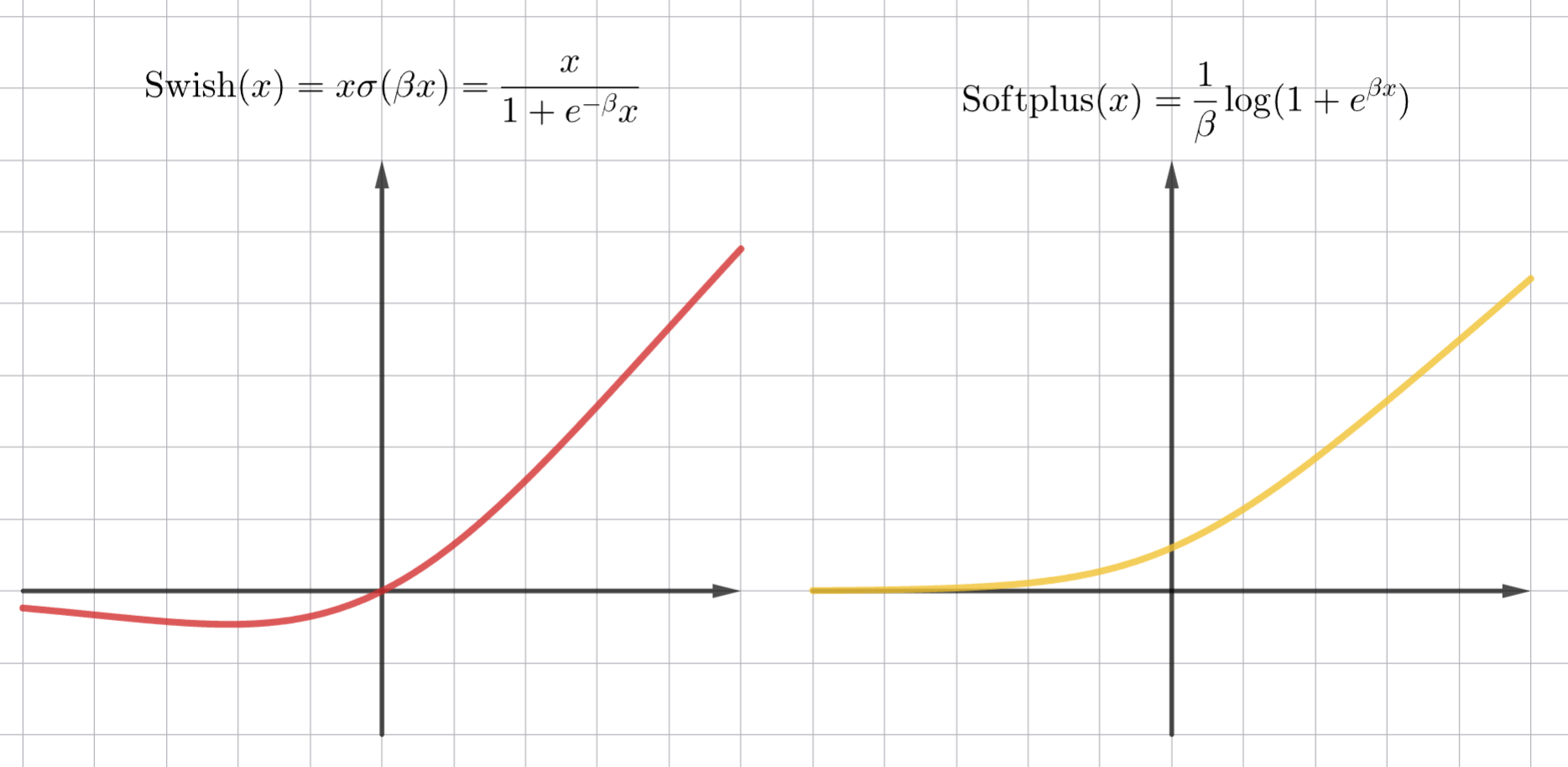
Нейросеть представляет композицию нейронов или же большую сложную функцию. Такую нейросеть можно задать графом вычислений
Оптимизировать сложную функцию можно с помощью градиентного спуска. Мы измеряем эффективность нашей нейросети с помощью функции потерь $\mathcal{L}(W)$, которая представляет различие между предсказанным результатом и истинным, где $W$ - это веса нейронов, поэтому можно найти градиент от этой функции, который равен вектору наибольшего роста функции потерь
Если веса изменять в противоположном направлении градиента:
\[W^\prime = W - \eta \nabla \mathcal{L}(W),\]где $\eta$ - скорость обучения, то функция потерь будет уменьшаться
Проблем с градиентным спуском есть несколько:
- Возможность прийти к локальному минимуму, а не глобальному
- Градиентный спуск все время “прыгает” вокруг минимума, но не достигает его
Эти проблемы решаются с помощью правильного выбора оптимизатора и скорости обучения
Далее с помощью обратного распространения находится градиент от функции потерь для каждого нейрона, что позволяет отрегулировать его веса
Еще одним полезным приемом являются стохастический или пакетный градиентные спуски. Вместо всей тренировочной выборки используются лишь часть для обновления весов
Рассмотрим подходы для адаптивной скорости обучения и оптимизаторы:
-
Линейное уменьшение (Linear Decay). При линейном уменьшении скорость обучения $\eta$ (eta, шаг) убывает пропорционально номеру эпохи или итерации: $\eta_t = \eta_0 \cdot \gamma^{\lfloor \frac{t}{s} \rfloor}$, где $s$ - шаг, через сколько эпох уменьшать скорость
-
Экспоненциальное уменьшение (Exponential Decay). При экспоненциальном уменьшении скорость обучения падает в геометрической прогрессии. С каждой эпохой текущую скорость обучения умножается на постоянный коэффициент $\gamma$, который меньше 1: $\eta_t = \eta_0 \cdot \gamma^t$ или $\eta_t = \eta_0 \cdot e^{-kt}$
-
Градиентный спуск с импульсом: $w^{(t + 1)} = w^{(t)} - \eta v_{t + 1}$, где $v_{t + 1} = \mu v_t + \frac{\partial \mathcal{L}}{\partial w^{(t)}}$
Более быстрый при малых градиентах, чем обычный градиентный спуск, также менее чувствителен к шуму, чем стохастический градиентный спуск
-
Метод Нестерова (Nesterov Accelerated Gradient, NAG) - это развитие идеи спуска с импульсом. Обычный метод импульса помогает сглаживать колебания и ускоряться в нужном направлении, но у него есть недостаток: он может не вовремя замедляться, так как использует текущее положение для расчета градиента
Метод Нестерова использует значение градиента от функции потерь для уже измененных весов: $w^{(t + 1)} = w^{(t)} - \eta v_{t}$, где $v_{t} = \mu v_{t - 1} + \eta \cdot \frac{\partial \mathcal{L}}{\partial (w^{(t)} + \mu v_{t - 1})}$
-
Адаптивный градиент (Adagrad, от Adaptive Gradient)
Adagrad стал первым методом, который ввел понятие адаптивной скорости обучения для каждого параметра. Adagrad накапливает сумму квадратов всех прошлых градиентов для каждого параметра $G_{t} = G_{t-1} + \left(\frac{\partial \mathcal{L}}{\partial (w^{(t)})}\right)^2$ и использует ее для масштабирования скорости обучения: $w^{(t + 1)} = w^{(t)} — \frac{\eta}{\sqrt{G_{t} + \varepsilon}} \cdot \frac{\partial \mathcal{L}}{\partial (w^{(t)})}$
-
RMSProp (Root Mean Square Propagation): $w^{(t + 1)} = w^{(t)} - \frac{\eta}{\sqrt{s_{t + 1}} + \varepsilon} \frac{\partial \mathcal{L}}{\partial w^{(t)}}$, где $s_{t + 1} = \rho s_t + (1 - \rho) \left(\frac{\partial \mathcal{L}}{\partial w^{(t)}}\right)^2$
Здесь $\varepsilon$ - число, близкое к 0, чтобы избежать деления на 0
-
Adam (Adaptive Moment Estimation): $w^{(t + 1)} = w^{(t)} - \frac{\eta}{\sqrt{\hat v_{t + 1}} + \varepsilon} \hat m_{t + 1}$
Здесь $m_{t + 1} = \beta_1 m_t + (1 - \beta_1) \frac{\partial \mathcal{L}}{\partial w^{(t)}}$ - оценка первого момента, $v_{t + 1} = \beta_2 v_t + (1 - \beta_2) \left(\frac{\partial \mathcal{L}}{\partial w^{(t)}}\right)^2$, а $\hat m_{t + 1} = \frac{m_{t + 1}}{1 - \beta^t_1}$, $\hat v_{t + 1} = \frac{v_{t + 1}}{1 - \beta^t_2}$ - коррекция смещения
$\beta_1$ и $\beta_2$ - настраиваемые параметры, рекомендуется $\beta_1 = 0.9, \beta_2 = 0.999, \varepsilon = 10^{-8}$
Оптимизатор Adam получился настолько удачным, что его применяют в большинстве публикаций, и он получается множество модификаций
Роль функции потерь могут исполнять:
-
Для бинарной классификации это бинарная перекрестная энтропия (BCE, Binary Cross-Entropy):
\[\mathcal{L}_{\mathrm{BCE}} (y, p) = -(y \log p + (1 - y) \log (1 - p)),\]где $y$ - точное значение класса ($0$ или $1$), а $p$ - вероятность принадлежности классу $1$
Если нейросеть дает несколько предсказаний объекту, имеющему несколько классов, то применяют такую формулу (Multi-label BCE):
\[\mathcal{L}_{\mathrm{BCE}} (y, p) = -\sum_k (y_k \log p_k + (1 - y_k) \log (1 - p_k))\] -
Для регрессии используют среднее значение абсолютных разностей (MAE) \(\mathcal{L}_\mathrm{MAE} (y, \hat y) = \frac{1}{n} \sum_{i = 1}^n \vert y_i - \hat y_i \vert\) или среднее значение квадратов разностей (MSE) \(\mathcal{L}_\mathrm{MSE} (y, \hat y) = \frac{1}{n} \sum_{i = 1}^n (y_i - \hat y_i)^2\)
Помимо них еще используется функция потерь Хубера:
\[\mathcal{L}_\delta (a) = \begin{cases}\frac{1}{2} a^2, & \vert a \vert \leq \delta, \\ \delta (\vert a \vert - \frac{1}{2} \delta), & \vert a \vert > \delta, \\ \end{cases}\]где $a = y - \hat y$, а $\delta$ - параметр чувствительности
Такая функция менее чувствительна к тем выбросам, что дальше $\delta$: квадратичная к маленьких ошибкам и линейна к большим
Как и с другими методами машинного обучения, нейросети подвержены переобучению - ситуации, в которой функция потерь для тренировочных данных низка, а для тестовых данных высока, то есть модель не запомнила общие закономерности, а просто подстраивается под тренировочные данные и при этом сильно реагирует на шумы
Для борьбы с переобучением используются:
-
L2-регуляризация (Weight Decay) - вводим штраф за большие веса для функции потерь: $\mathcal{L}^\prime = \mathcal{L} + \frac{\lambda}{2} \sum_l | W^{(l)} |^2$
-
Ранняя остановка - если метрика на проверочных данных достигла минимума на определенной эпохи и начала расти, то оптимально остановить обучение
-
Исключение или дропаут (Dropout) - случайным образом с некой вероятностью (обычно $p = \frac{1}{2}$) отключаем нейроны в процессе обучения, таким образом, нейроны обучаются осмысленным признакам самостоятельно
-
Сглаживание меток (Label Smoothing) - с определенной вероятностью $\varepsilon$ изменяем метку $y^\prime_i = y_i (1 - \alpha) + \frac{\alpha}{N}$
-
Инициализация весов
При первой инициализации весов мы можем посчитать дисперсию распределения
Если дисперсия весов меньше 1, то со временем градиенты затухают, а если больше 1, то градиенты взрываются. Из-за чего появились методы инициализации весов как случайные величины нормального или равномерного распределения:
-
Метод инициализации Xavier, предложенный Ксавье Глоро и Йошуа Бенджио в 2010, предполагает инициализировать веса как $w_i \in U\left(-\frac{\sqrt{6}}{\sqrt{f_{\text{in}} + f_{\text{out}}}}, \frac{\sqrt{6}}{\sqrt{f_{\text{in}} + f_{\text{out}}}}\right)$ или как $w_i \in N\left(0, \frac{2}{f_{\text{in}} + f_{\text{out}}}\right)$, где $f_{\text{in}}$ - размерность предыдущего слоя, а $f_{\text{out}}$ - размерность этого
В результате этого подхода дисперсия значений на входе и на выходе слоя совпадает
Такой метод отлично подходит для симметричных функций активации (например, гиперболический тангенс), но плохо для таких, как ReLU
-
Метод инициализации He, предложенный Каймингом Хе в 2015, предполагает инициализировать веса как $w_i \in N\left(0, \frac{2}{f_{\text{in}}}\right)$
Такой метод хорошо работает с ReLU, LeakyReLU, GELU и другими несимметричными функциями
-
-
Нормализация - приведение к одному масштабу значение нейрона. Без нормализации распределение значений нейронов по слоям могут сильно меняться, обучение может проходить нестабильно и медленно. Используют:
-
Пакетная нормализация (Batch Normalization) - для пакета (батча) объектов из выборки вычисляют значения конкретного нейрона, далее от этих значений считается среднее и отклонение, чтобы затем масштабировать значения этого нейрона, то есть $\hat z_i = \frac{z_i - \mu}{\sqrt{\sigma^2 + \varepsilon}}$, где $\varepsilon$ - близкое к 0 число (например, $10^{-5}$)
Обучение небольшими пакетами позволяют параллельно вычислять значения нейронов
После пакетной нормализации обычно применяют канальное масштабирование $y_i = \gamma z_i + \beta$, где $\gamma$ и $\beta$ - обучаемые параметры, а под каналом подразумевается один или несколько нейронов
-
Нормализация слоев (Layer Normalization) работает аналогично пакетной, только значения нейронов масштабируются относительно среднего и отклонения значений всех нейронов слоя
-