itmo_conspects
Администрирование в ОС Linux
- Администрирование в ОС Linux
- Лекция 1. Введение в Linux
- Лекция 2. Файлы и права доступа
- Лекция 3. Файловые системы
- Лекция 4. Процессы, часть I
- Лекция 5. Процессы, часть II
- Лекция 6. Загрузка ОС Linux
- X. Программа экзамена 2025/2026
- Extra 1. Современные системы инициализации
- Extra 2. Механизмы контейнеризации
- Extra 3. Установка ПО, пакетные менеджеры
- Extra 4. Графические подсистемы
Операционная система - это базовое системное программное обеспечение, управляющее работой вычислительного узла и реализующее универсальный интерфейс между аппаратным обеспечением, программным обеспечением и пользователем
Возможности по изменению аппаратного обеспечения часто ограничены, поэтому на практике стремятся извлечь максимальную производительность и гибкость за счёт программного обеспечения и грамотного администрирования ОС
Курс разделен на несколько блоков:
- Работа с файлами
- Файловые системы
- Процессы и управление ресурсами
- Межпроцессорное взаимодействие
- Загрузка операционной системы
- Механизмы контейнеризации
- Управление пользовательским ПО
- Графические среды
Лекция 1. Введение в Linux
Linux (в части случаев GNU/Linux) - это семейство открытых и свободных Unix-подобных операционных систем на базе ядра Linux, включающих набор утилит и программ проекта GNU, а также другие системные и прикладные компоненты
Linux начал своё развитие в 1991 году, когда Линус Торвальдс, будучи студентом Хельсинкского университета, опубликовал первую версию ядра Linux как учебный и исследовательский проект
Со временем вокруг ядра Linux сформировалось большое сообщество разработчиков, а сам Linux стал использоваться в серверах, настольных системах, мобильных и других устройствах
Разделяют бесплатное ПО, открытое ПО и свободное ПО:
- Бесплатное ПО (Freeware) - программное обеспечение, распространяющееся бесплатно конечному пользователю в виде исполняемых файлов
- Открытое ПО (Open-Source Software) - программное обеспечение с открытым исходным кодом, чаще всего распространяющимся по разрешительной лицензии
- Свободное ПО (Free and Open-Source Software, FOSS) - открытое программное обеспечение, лицензия которого заставляет авторов производных от него работ лицензировать их под той же свободной лицензией
Linux является свободным программным обеспечением и распространяется под лицензией GNU General Public License 2.0. Это означает, что операционная система Linux гарантирует пользователю 4 свободы, сформулированные Ричардом Столлманом, основателем проекта GNU:
- Свобода запускать программу в любых целях (свобода 0).
- Свобода изучения работы программы и адаптация её к вашим нуждам (свобода 1). Доступ к исходным текстам является необходимым условием.
- Свобода распространять копии, так что вы можете помочь вашему товарищу (свобода 2).
- Свобода улучшать программу и публиковать ваши улучшения, так что всё общество выиграет от этого (свобода 3). Доступ к исходным текстам является необходимым условием.
Лицензия GNU General Public License 2.0 накладывает обязательство на то, что производные работы также должны распространяться на условиях этой лицензии
Linux включает набор утилит и программ GNU, такие как Bash или GNU Compiler Collection, которые тоже являются свободным ПО
Linux распространяется не только в виде ядра, но и в виде дистрибутивов - готовых комплектов программного обеспечения, включающих ядро, системные утилиты, менеджер пакетов, установщик и часто графическую среду. Сейчас популярные дистрибутивы - это Debian, Ubuntu, Fedora, Arch Linux и другие
Дистрибутивы Linux бесплатные, но не все. Так, например, Red Hat Enterprise Linux распространяется по платной модели, имея открытый код, но за плату предлагается расширенная корпоративная поддержка и сервис
Ключевые отличия свободного ПО и проприетарного ПО заключаются:
-
В доступу к исходному коду
-
В модели поддержки. В свободном ПО поддержка часто осуществляется сообществом или сторонними компаниями, а в проприетарном ПО - официальным производителем
-
В поиске и исправлении уязвимостей. Открытый код позволяет независимый аудит безопасности, тогда как при использовании проприетарного ПО пользователь вынужден доверять разработчику
-
В гибкости и кастомизации. Свободное ПО можно модифицировать под конкретные нужды, проприетарное, как правило, нет
Долгое время наиболее популярной настольной операционной системой остаётся Microsoft Windows. Рассмотрим ключевые концептуальные отличия Linux от Windows:
-
Работа с файлами
В Linux все объекты, в том числе файлы, сетевые сокеты, устройства, каналы, - это файловые дескрипторы, поэтому взаимодействие с ними осуществляется через файловую систему
В Windows пользователь чаще взаимодействует с действиями и приложениями, а не с абстрактными объектами файловой системы
-
Иерархия файловой системы
Linux использует единую иерархию каталогов, начинающуюся с корня
/, тогда как в Windows используется несколько корней: дискиC:,D:и так далее -
Права доступа
В Linux строгая модель прав доступа: владелец, группа и остальные; В Windows используется модель NTFS-разрешений, менее прозрачная для пользователя.
-
Обновления и установка ПО
В Linux программное обеспечение обычно устанавливается из централизованных репозиториев через менеджеры пакетов. В Windows чаще используются отдельные установщики для каждого приложения
Лекция 2. Файлы и права доступа
В Linux и других Unix-подобных системах все объекты являются файловыми дескрипторами, то есть все действия совершаются через универсальный интерфейс
Файловый дескриптор - это идентификатор, за которым закреплен определенный поток ввода и вывода. Через файловые дескрипторы в Linux можно работать:
- с устройствами
- с процессами
- с файлами и каталогами в памяти хранилища
- и с другими объектами
Получаем единый набор операций с файловым дескриптором: открытие, чтение, запись и закрытие
Всего можно выделить 7 типов файлов:
-
Регулярный файл
Регулярный файл - это файл в обычном его понимании, то есть именованная область памяти хранилища, которая структурирована иерархически
По умолчанию, Linux рекомендует использовать файловую систему ext4, которая использует индексные дескрипторы. Поэтому на диске файл представлен индексным дескриптором в начале блочного устройства
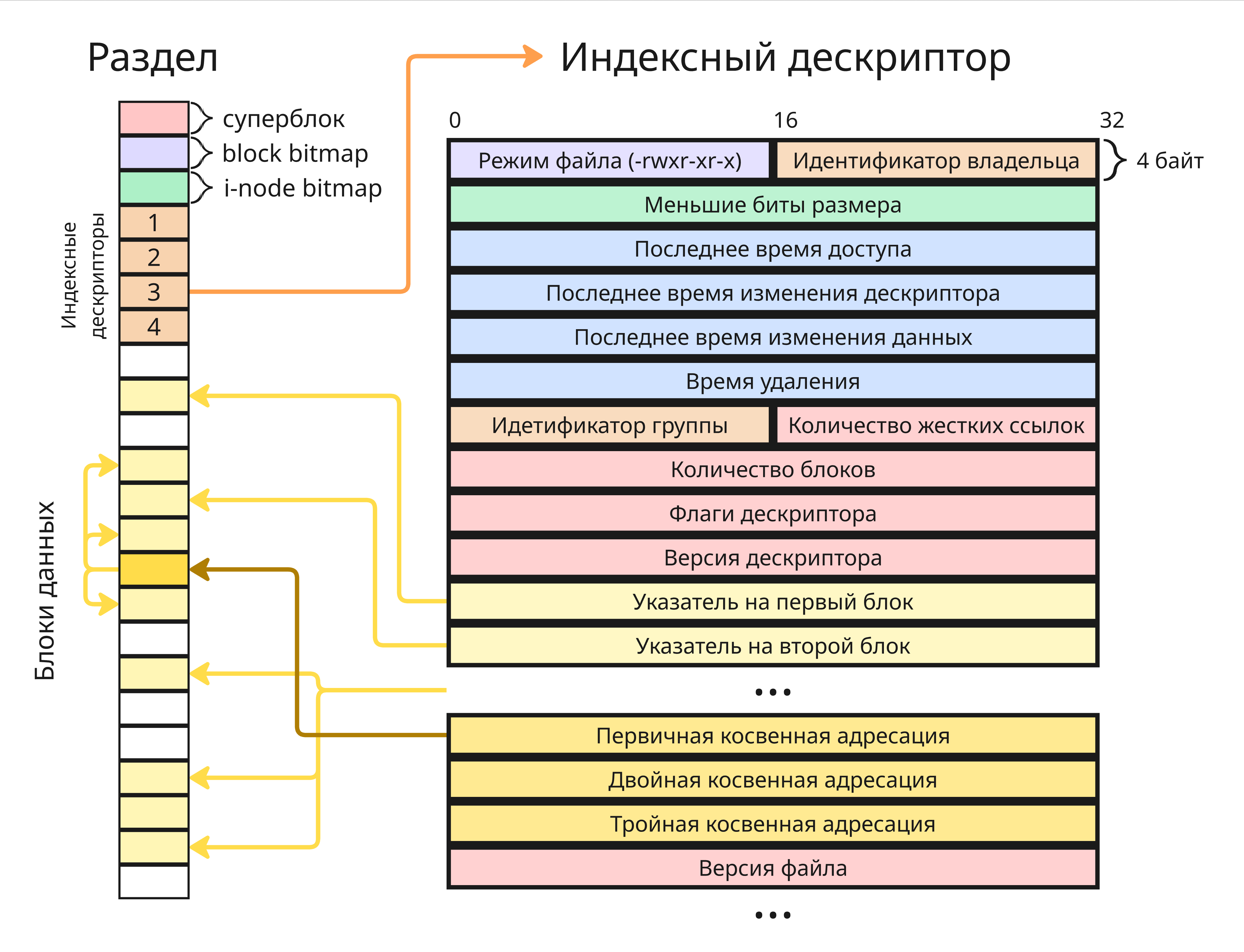
Когда файл создается, в таблице индексных дескрипторов появляется индексный дескриптор файла. При записи операционная система выделяет новые блоки на блочном устройстве и добавляет ссылки на эти блоки в индексном дескрипторе, а при удалении удаляется индексный дескриптор
При этом файл в Linux не хранит свое имя - это ответственность каталога
-
Каталог
Каталог - это таблица, содержащая имя файла, его индексный дескриптор и опционально другие данные. В разных операционных системах применяет разная терминология, в Windows применяется офисный термин “папка” (folder), а в Linux каталоги называются директориями (directory)
Каталоги позволяют задавать иерархическую структуру на блочном устройстве. Так как это таблица, где ключ - это имя файла или каталога, нельзя создать в одном каталоге файл и каталог с одним и тем же именем
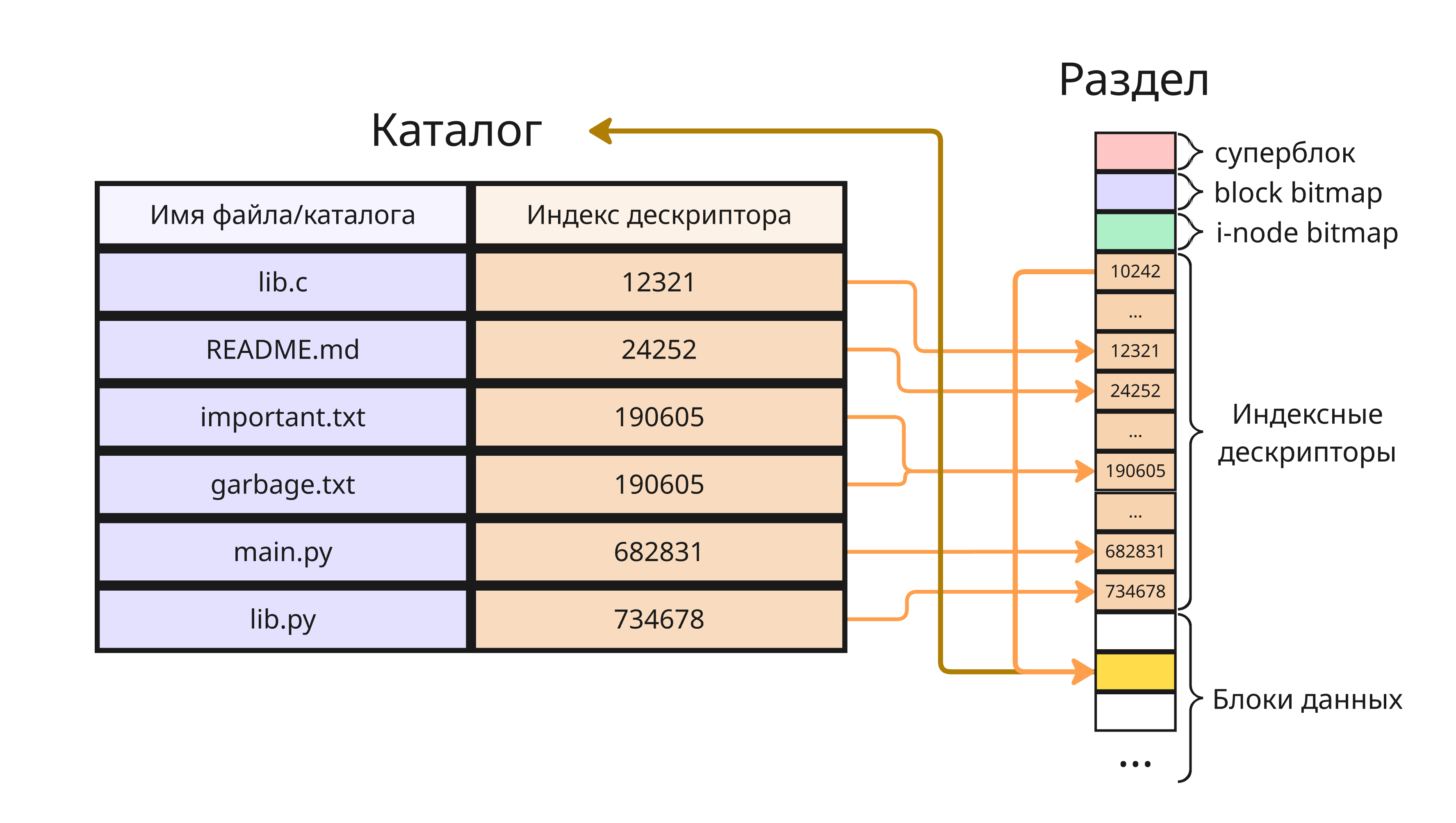
Linux позволяет создавать не просто файлы в каталоге, а жесткие ссылки на файлы в каталоге. При создании жесткой ссылки:
ln исходный_файл новый_файлФайлы
исходный_файлиновый_файлбудут иметь те же содержимое и индексный дескриптор, однако храниться в разных каталогах одновременно. Удаление одного из них не приведет к потери ссылок на блоки, где хранятся данные. Чтобы удалился сам индексный дескриптор, нужно, что бы счетчик жестких ссылок достиг нуляЖесткие ссылки нельзя создавать:
- на каталоги, так как в этом случае может получиться циклическая зависимость, из-за чего рекурсивные алгоритмы для работы с файловым деревом ломаются
- в каталогах, находящихся в разных файловых системах (то есть в разных разделах или устройствах), так как они имеют разные таблицы с индексными дескрипторами или же не иметь вовсе таковой (как, например, в системе FAT)
-
Символическая (или мягкая) ссылка
Символическая ссылка (symlink или softlink) - это еще один тип файла, который внутри хранит путь до другого файла в файловой системе. При обращении путь к ссылке подменяется операционной системой на содержащийся внутри путь файла, что позволяет обойти ограничения, связанные с жесткой ссылкой
Символическая ссылка может быть сломанной или битой, если она указывает на файл или каталог, который не существует
Символическую ссылку можно сделать с помощью команды
ln:ln -s исходный_файл имя_ссылки -
Файлы-дырки
Файлы-дырки (filehole, или специальные файлы) не хранят ничего на жестком диске компьютера непосредственно, однако с помощью них осуществляется доступ к подключенным устройствам и объектам операционном системы
Файлами-дырками могут быть:
- сокеты - объекты для сетевой коммуникации компьютеров
- именованные каналы (также пайп) - очереди символов для передачи данных между процессами
- блочные устройства - устройства, в которых данные хранятся блоками, например жесткие диски, флешки, DVD и так далее
- символьные устройства - такие устройства, как мышь, консоль и другие
Особое место занимает каталог
/dev/. В нем содержатся все устройства, в том числе виртуальные, к которым операционная система имеет доступ. Есть два типа организации этого каталога:- Статическая - в этом случае список подключаемых устройств известен заранее, поэтому ядро имеет все нужны драйвера, а системный администратор вручную заводит файловый дескриптор в
/dev/для каждого устройства - Динамическая - в этом случае ядро автоматически загружает необходимый драйвер для устройства и создает файловый дескриптор, по сути аналог Plug-and-Play от Microsoft
Так
/dev/содержит:/dev/console- консоль для вывода системных сообщений при запуске и завершении системы/dev/tty- консоль текущего процесса/dev/tty1,/dev/tty2, … - виртуальные консоли, доступные через Ctrl+Alt+F1 и так далее/dev/sda(аналогично/dev/sd+буква) - жесткий диск, подключенный через SATA/dev/nvme0n1(аналогично/dev/nvme0n+цифра) - твердотельный накопитель с технологией NVMe, в данном случаеnvme0- это номер PCIe-шины-
/dev/nvme0n1p1- первый раздел на этом накопителе /dev/fb0- буфер кадра в видеопамяти графического процессора/dev/mouse0- мышь/dev/null- канал, в который можно перевести символьный поток (например, вывод процесса), чтобы уничтожить его/dev/zero- поток, который генерирует нули/dev/random- поток, который генерирует рандомные символы/dev/full- поток, который возвращает ошибку “Недостаточно места”
Каждый процесс (кроме демонов) при создании получает 3 символьных файловых дескриптора: стандартный поток ввода с номером
0, стандартный поток вывода с номером1и стандартный поток ошибок с номером2. На них есть символические ссылки/dev/stdin,/dev/stdoutи/dev/stderr
Используя команду ls -l, можно посмотреть на информацию о файлах в каталоге, например:
crw-r--r-- 1 root root 10, 235 Feb 13 17:59 autofs
drwxr-xr-x 2 root root 180 Feb 13 17:59 block
crw-rw---- 1 root disk 10, 234 Feb 13 17:59 btrfs-control
drwxr-xr-x 3 root root 60 Feb 13 17:59 bus
drwxr-xr-x 2 root root 4920 Feb 13 17:59 char
crw------- 1 root root 5, 1 Feb 13 17:59 console
lrwxrwxrwx 1 root root 11 Feb 13 17:59 core -> /proc/kcore
drwxr-xr-x 14 root root 280 Feb 13 17:59 cpu
crw------- 1 root root 10, 259 Feb 13 17:59 cpu_dma_latency
Первый столбец обозначает тип файла и его модификаторы доступа. Первая буква - это тип файла, так:
-- это регулярный файлd- это директория (от directory)l- это символическая ссылка (от link)s- это сокет (от socket)b- это блочное устройство (от block)c- это символьное устройство (от character)p- это именованный канал (от pipe)
Следующие 9 букв задают права доступа для файла. В Linux действует ролевая модель доступа, поэтому есть такие понятия:
- Пользователь файла (User) - его непосредственный владелец, тот, кто создал файл
- Группа владельца файла (Group) - другие пользователи, входящие в ту же группу
- Все остальные пользователи в системе (Other)
Так модификаторы доступа делятся на три тройки букв, каждая тройка из которых показывает права для определенной выборки пользователей
- Буква
r- право на чтение файла или чтение имен файлов внутри каталога - Буква
w- право на запись в файл - Буква
x- право на исполнение файла или чтение свойств файлов внутри каталога
Так -rwxr-xr-x означает регулярный файл, читать и исполнять который могут все, а записывать только владелец
Права доступа проверяются слева направо. Так, если файл имеет права ----r-xr-x, то его владелец не сможет с ним ничего сделать, несмотря на то, что он находится в группе файла
Помимо этих 9 модификаторов есть еще 3 скрытых:
- SUID (Set User ID upon execution) - пользователи, которые могут запустить выполнение файл, запускают его с правами владельца. Для каталогов этот флаг ничего не делает. В
ls -lобозначается как--s------(если установленxдля владельца) или--S------ -
SGID (Set Group ID upon execution) - пользователи, которые могут запустить выполнение файл, запускают его с правами группы владельца. Для каталог этот флаг означает то, что новые файлы создают с той же группой, которая привязана к каталогу, а не основной группой для пользователя. В
ls -lобозначается как-----s---(если установленxдля пользователей группы) или-----S---Биты SUID и SGID полезны для осуществления особых ограничений на файлы. Например, если в системе зарегистрированы пользователи, чьи пароли хранятся в недоступном ими файле, то можно сделать скрипт с битом SUID, которым владеет суперпользователь, и который только изменяет пароль в файле пользователя, который его вызвал
-
T-бит или липкий бит (Sticky Bit) - файлы в каталоге, имеющем липкий бит, могут быть удалены или переименованы только владельцем файла. В
ls -lобозначается как--------t(если установленxдля остальных пользователей) или--------TВ ранних версиях ядра липкий бит использовался на исполняемых программах. Тогда было непозволительно долго ждать, когда программа, закончившая исполнение пару минут назад, снова загружалась в оперативную память. Поэтому программы с липким битом при первом исполнении загружались в оперативную память, а после завершения память не высвобождалась, благодаря чему при следующем исполнении ядро могло назначить эту область память процессу и не загружать программу повторно
Права можно установить для файла с помощью команды chmod (от change mode):
chmod права файл
Права указываются:
- В двоичном формате, так,
101101000означаетr-xr-x---, при этом 10-ый бит предназначен для T-бита, 11-ый бит - для SGID, 12-ый бит - для SUID - В восьмеричном формате, например,
754означаетrwxr-xr--,2555означаетr-xr-sr-x - В символьном формате, то есть
rwxr-xr-- -
С указанием выборки пользователей. Например:
chmod u+x fileдобавляет право на исполнение файла владельцуchmod u+w,o-w fileдобавляет право на запись владельцу и убирает право на запись пользователям вне группыchmod g+s fileдобавляет флаг SGIDchmod o+s fileдобавляет флаг Sticky Bitchmod g=rx fileустанавливает права на чтение и запись группе вместо тех права, что были до этого
Второй столбец - это число жесткий ссылок на файл
Третий столбец из вывода ls -l указывает на владельца файла, а четвертый - на группу владельца (так как пользователь может состоять в нескольких группах). Сменить владельца можно с помощью команды chown (от change owner):
# меняет владельца на pelmeshke
chown pelmeshke /var/log/mylogs/app.log
# меняет владельца на pelmeshke и группу на supercoolusers
chown pelmeshke:supercoolusers /var/log/mylogs/app.log
# меняет владельца на pelmeshke рекурсивно
# для всех файлов и каталогов в /var/log/mylogs
chown -R pelmeshke /var/log/mylogs/
По умолчанию, при создании пользователя в Linux ядро создает группу с таким же именем. Для смены группы файла есть команда chgrp (от change group):
# меняет группу на supercoolusers
chgrp supercoolusers /var/log/mylogs/app.log
Лекция 3. Файловые системы
Файловая система - это способ организации информации на носителе данных
Файловая система выполняет такие функции:
- Организацию хранения данных
- Управление доступом
- Учет и распределение дискового пространства
- Обеспечение целостности
- Поддержка операций ввода-вывода
Файловая система является посредником в общении между пользователем, использующим ОС, и жестким диском
Позднее число файловых систем стало настолько большим, что в архитектуре операционных систем стала появляется виртуальная файловая система - стандартизованный интерфейс между системными вызовами и конкретной файловой системой
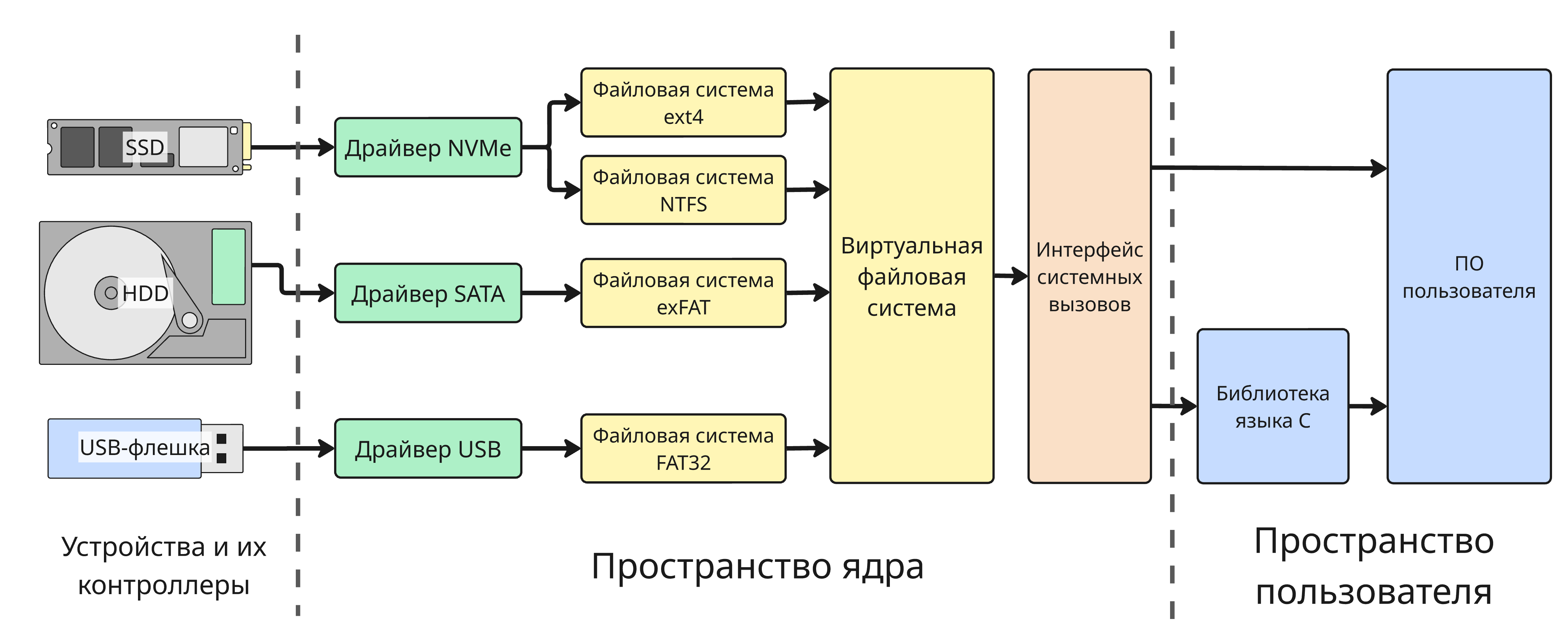
Файловые системы могут использовать множество методов организации:
- Линейное размещение
- Связный список
- Таблица аллокаций файлов
- Индексные дескрипторы
Подробнее об этом описано в курсе “Операционные системы”
Современные операционные системы используют файловые системы с индексными дескрипторами для дисков, на которых установлена система. Так, Windows использует NTFS (New Technology File System), а для Linux рекомендуется ext4 (от Fourth Extended, Четвертая расширенная файловая система)
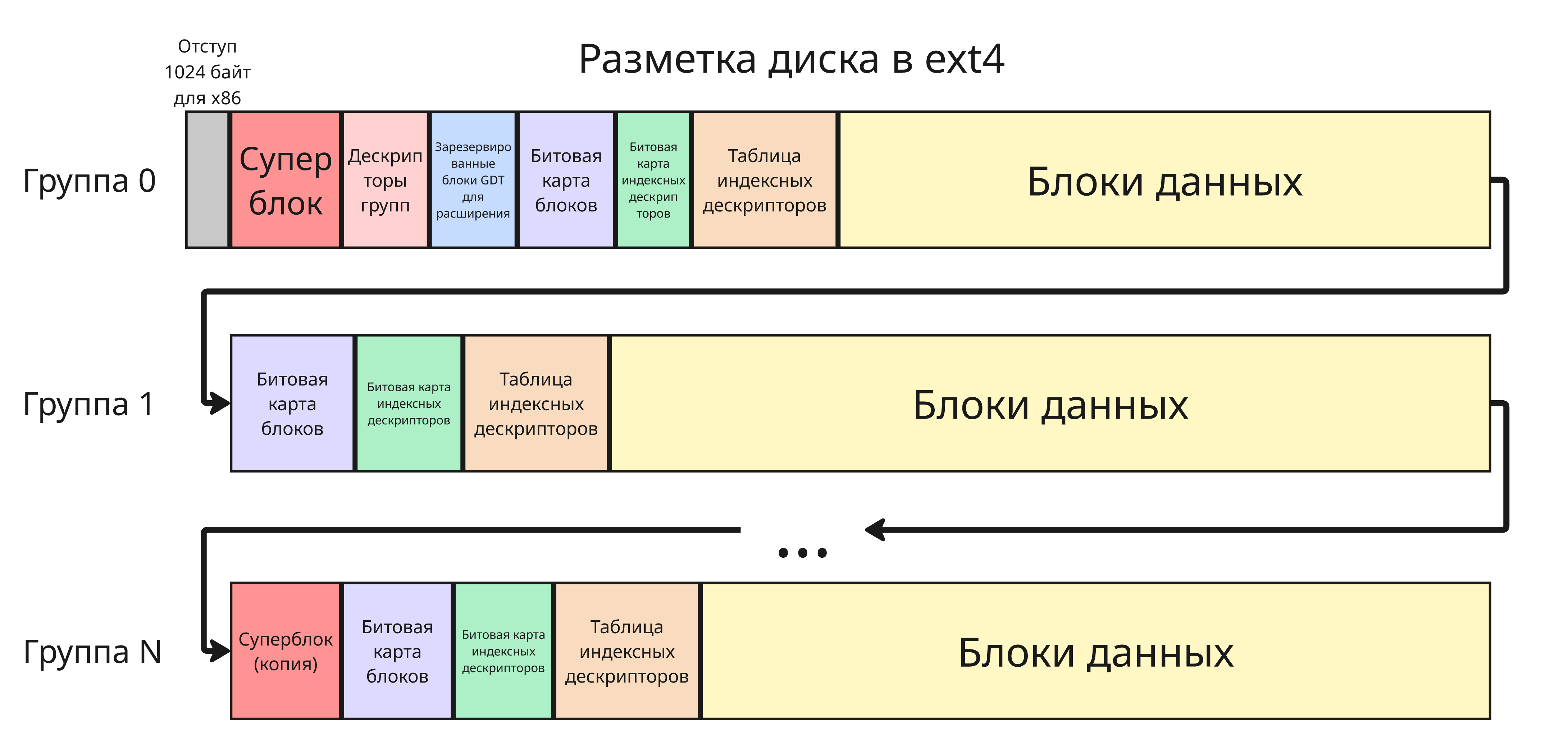
В файловой системе ext4 в начале блочного устройства есть участок с названием суперблок (Superblock). Суперблок - это структура, состоящая из данных, которые определяют организацию данных:
| Поле | Тип данных | Назначение |
|---|---|---|
s_inodes_count |
__le32 |
Общее количество индексных дескрипторов |
s_blocks_count_lo |
__le32 |
Общее количество блоков (младшие 32 бита) |
s_r_blocks_count_lo |
__le32 |
Зарезервированные блоки (младшие 32 бита) |
s_free_blocks_count_lo |
__le32 |
Свободные блоки (младшие 32 бита) |
s_free_inodes_count |
__le32 |
Количество свободных индексных дескрипторов |
s_first_data_block |
__le32 |
Первый блок данных |
s_log_block_size |
__le32 |
Логарифм размера блока в килобайтах по основанию 2 |
s_log_cluster_size |
__le32 |
Логарифм размера кластера в килобайтах по основанию 2 |
s_blocks_per_group |
__le32 |
Блоков в группе |
s_clusters_per_group |
__le32 |
Кластеров в группе |
s_inodes_per_group |
__le32 |
Индексных дескрипторов в группе |
s_mtime |
__le32 |
Время последнего монтирования |
s_wtime |
__le32 |
Время последней записи |
s_mnt_count |
__le16 |
Счётчик монтирований после проверки диска |
s_max_mnt_count |
__le16 |
Максимальное число монтирований, после который нужна проверка диска |
s_magic |
__le16 |
Магическое число, для ext4 - это 0xEF53 |
s_state |
__le16 |
Состояние файловой системы |
s_errors |
__le16 |
Поведение при ошибках |
s_minor_rev_level |
__le16 |
Минорная версия |
s_lastcheck |
__le32 |
Время последней проверки |
s_checkinterval |
__le32 |
Интервал проверки |
s_creator_os |
__le32 |
Операционная система, создавшая раздел (Linux - это 0x0000, FreeBSD - это 0x0003) |
s_first_ino |
__le32 |
Первый незарезервированный индексный дескриптор |
s_inode_size |
__le16 |
Размер индексного дескриптора (обычно 256 байт) |
s_block_group_nr |
__le16 |
Номер группы (для копии суперблока) |
s_uuid |
__u8[16] |
UUID файловой системы |
s_volume_name |
char[16] |
Имя тома |
… и много других
Здесь __le16, __le32 - беззнаковые целые числа, записанные в Little-endian, размером 16 бит и 32 бита соответственно, __u8[16] - 16-байтный массив беззнаковый 8-битных чисел, а char[16] - символьная последовательность
Источник: https://docs.kernel.org/next/filesystems/ext4/super.html
Со временем появилась идея размещать блоки больших файлов рядом друг с другом, чтобы уменьшать движение читающей головки жесткого диска по секторам
Для решения этого появились группы блоков. Группы содержат свои битовые карты, таблицы индексных дескрипторов и блоки данных
Первая группа под индексом 0 хранит суперблок и таблицу дескрипторов блочных групп (Block Group Descriptors) - структуры с данными полями:
| Поле | Тип данных | Назначение |
|---|---|---|
bg_block_bitmap_lo |
__le32 |
Номер блока битовой карты блоков (младшие 32 бита) |
bg_inode_bitmap_lo |
__le32 |
Номер блока битовой карты дескрипторов (младшие 32 бита) |
bg_inode_table_lo |
__le32 |
Первый блок таблицы индексных дескрипторов (младшие 32 бита) |
bg_free_blocks_count_lo |
__le16 |
Количество свободных блоков в группе |
bg_free_inodes_count_lo |
__le16 |
Количество свободных дескрипторов в группе |
bg_used_dirs_count_lo |
__le16 |
Количество каталогов в группе |
bg_flags |
__le16 |
Флаги состояния группы |
bg_exclude_bitmap_lo |
__le32 |
Блок битовой карты снимков исключения (Exclusion Snapshot) |
bg_block_bitmap_csum_lo |
__le16 |
Контрольная сумма битовой карты блоков |
bg_inode_bitmap_csum_lo |
__le16 |
Контрольная сумма битовой карты дескрипторов |
bg_itable_unused_lo |
__le16 |
Количество неинициализированных индексных дескрипторов |
bg_checksum |
__le16 |
Контрольная сумма дескриптора группы |
… и другие поля
Последующие группы могут хранить также избыточные копии суперблока и таблицы дескрипторов групп, но система будет обращаться к ним в том случае, если начало диска было повреждено
Источник: https://docs.kernel.org/next/filesystems/ext4/group_descr.html
Далее идет битовая карта блоков (Block Bitmap). В ней один бит, равный 1, обозначает, занят ли конкретный блок с тем же индексом
Затем расположена подобная битовая карта для индексных дескрипторов (Inode Bitmap), где бит 1 обозначает, занят ли индексный дескриптор в таблице дескрипторов
Источник: https://docs.kernel.org/next/filesystems/ext4/bitmaps.html
После этого расположена сама таблица индексных дескрипторов. Таблица представляет собой массив дескрипторов, где индекс - это номер индексного дескриптора
Для специальных индексных дескрипторов выделены особые индексы:
0для дескриптора, который не существует1для списка бракованных блоков2для корневого каталога/3для пользовательской квоты-
4для квоты группКвоты хранят информацию о том, сколько разрешено максимально иметь дескрипторов и/или блоков пользователям и группам
5для загрузчика. Сейчас он редко используется, так как рекомендуется устанавливать загрузчик на другой раздел диска6для каталога восстановления7для зарезервированной группы дескрипторов для увеличения количества дескрипторов файловой системы8для журнала, чтобы обеспечивать надежность данных во время сбоя
9-ый и 10-ый дескрипторы зарезервированы и используются для функций, который обозначены ? в документации, а 11-ый дескриптор - первый не зарезервированный, но обычно используется для каталога /lost+found/, который предназначен для восстановленный утилитой fsck файлов после сбоя
Источник: https://www.kernel.org/doc/html//latest/filesystems/ext4/special_inodes.html
Наконец, после таблицы индексных дескрипторов дальше идут сами блоки данных
В файловой системе ext3 добавилась система журналирования - способ восстановления данных в результате нештатной работы ОС или диска
Всего есть три типа журналов в ext3:
- Journal - самый медленный, но самый надежный журнал. Сначала в журнал пишутся блоки данных, потом они копируются в нужное место, а дескриптор изменяется
- Ordered - метаданные записываются в журнал до записи данных на диск, но сами данные на диск отправляются до подтверждения метаданных в дескрипторе
- Writeback - сначала пишем весь файл, а потом изменяем все метаданные в дескрипторе и журнале
В системе ext4 добавилось много новых функций, которые убирали ограничения старых версий системы:
-
Экстенты вместо блочной адресации
Вместо хранения списка отдельных блоков используются экстенты, что уменьшает фрагментацию и ускоряет работу с большими файлами
- Поддержка больших файлов (до 16 Тб в стандартной конфигурации) и файловой системы (теоретически до 1 Эб)
- Отложенное выделение блоков - блоки выделяются не сразу при записи, а позже, что улучшает размещение данных и снижает фрагментацию
- Контрольные суммы журнала уменьшают риск повреждения данных при сбоях
- Возможность дефрагментации без размонтирования файловой системы
- Можно увеличить размер файловой системы во время работы диска
- Предварительное выделение места для файлов
- Метки времени с точностью до наносекунд, тогда как в ext3 только до секунд
- Индексация больших каталогов с использованием хеш-дерева
Хорошей практикой является разделение диска на 6 разделов:
- Раздел для EFI (Extensible Firmware Interface), который хранит загрузчики (например, GRUB) и отформатирован в файловую систему FAT
- Раздел для каталога
/boot/, хранящий ядро иinitramfs - Раздел для корневого каталога
/ - Раздел для файла подкачки
- Раздел для домашнего каталога
/home/ - И раздел для каталога
/var/, содержащего изменяемые файлы
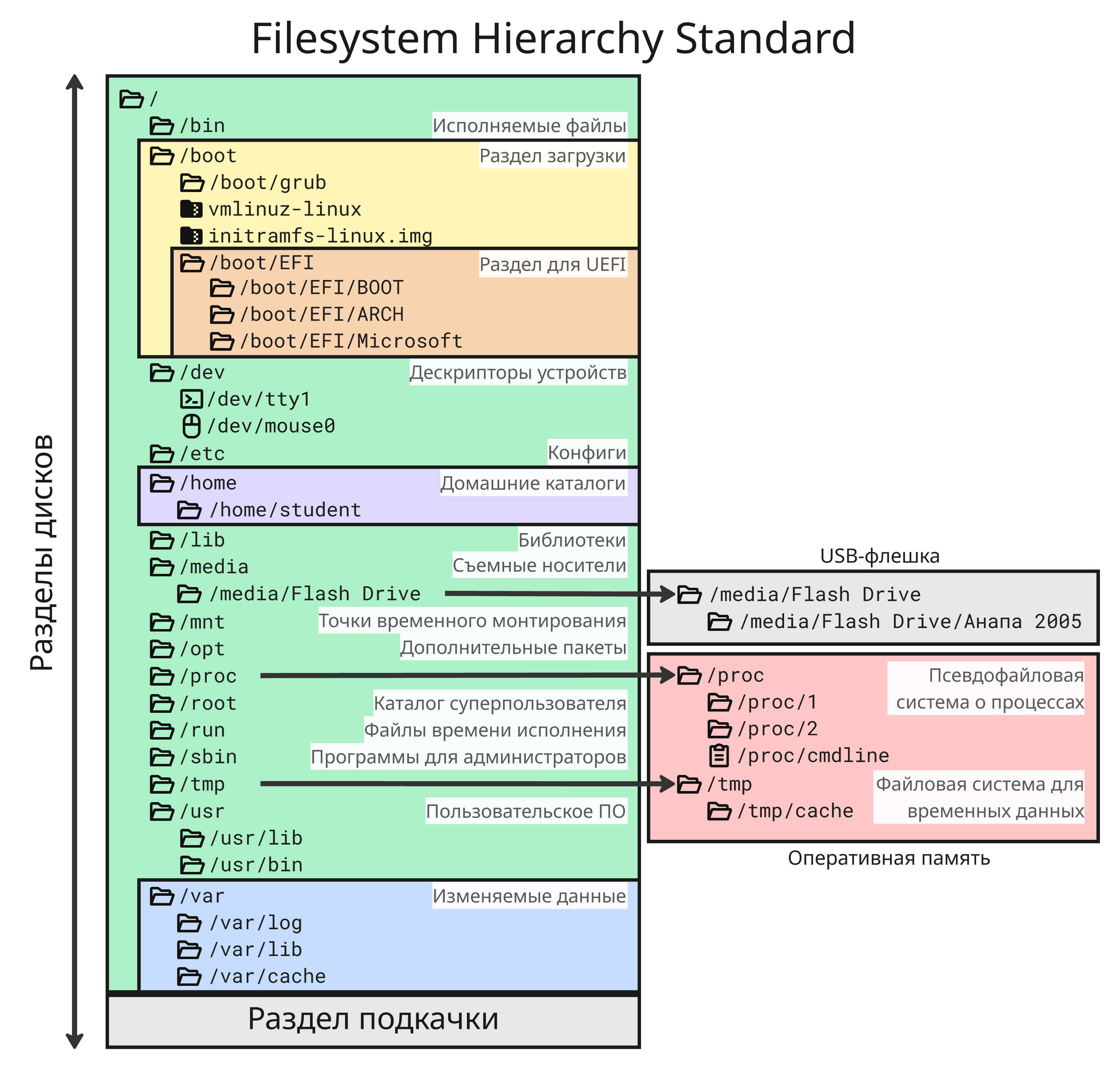
В корневом каталоге Linux создает множество подкаталогов для работы системы, структура которых подчиняется стандарту (FHS) Filesystem Hierarchy Standard:
/bin/- каталог с готовыми к исполнению основными программами (например,/bin/bash). Оболочки, такие как bash, ищут исполняемые файлы с именем там/sbin/- системные исполняемые файлы для администрирования (например,fsck,mount), которые обычно предназначены для суперпользователя/boot/- файлы, необходимые для загрузки системы: ядро Linux,initramfs, конфигурация загрузчика/dev/- файловые дескрипторы устройств-
/etc/(от Editable Text Configuration или Extended Tool Chest) - системные конфигурационные файлы такие, как настройки служб, сети, пользователей и всей системы /home/- домашние каталоги обычных пользователей-
/root/- домашний каталог суперпользователя /lib/,/lib64/- системные библиотеки, необходимые для работы программ из/bin/и/sbin//media/- точки монтирования съемных носителей/mnt/- временное монтирование файловых систем администратором/opt/- дополнительные пакеты/proc/- виртуальная файловая система с информацией о процессах и ядре, создающаяся динамически/sys/- виртуальная файловая система с информацией о устройствах и драйверах./run/- временные данные времени выполнения, например, текущие вошедшие пользователи или запущенные демоны-
/tmp/- временные файлы, которые очищаются после перезагрузки. В некоторых случаях каталог/tmp/может храниться непосредственно в оперативной памяти -
/usr/- пользовательские программы и данные (большинство установленного ПО):/usr/bin- программы/usr/lib- библиотеки/usr/src/- исходный код/usr/share- общие данные, которые не зависят от архитектуры
/var/- изменяемые данные, такие как:/var/log/- логи/var/lib/- персистентная информация программ (например, базы данных)/var/lock/- блокировки ресурсов/var/cache/- кэш/var/spool/- очереди печати, почтовых запросов и так далее/var/mail/- данные почтовых серверов/var/tmp/- временные файлы, которые нужно сохранить после перезагрузки
Лекция 4. Процессы, часть I
Процесс - совокупность набора исполняемых команд, ассоциированных с ним ресурсов и контекста исполнения, находящиеся под управлением операционной системы
Сам же процесс в Linux хранится структурой task_struct с множеством полей, таких как:
- Идентификатор процесса (PID, Process ID)
- Идентификатор группы потоков (TGID, Thread Group ID). Для главного потока равен идентификатору процесса
- Указатель на структуру родительского процесса, который породил этот процесс
- Имя исполняемого файла
- Идентификаторы пользователя и группы пользователя, создавшего процесс
- Состояние (об этом позже)
- Указатель на таблицы страниц памяти
- Рабочая директория
- Таблица открытых файловых дескрипторов
- Контекст процессора, то есть регистры, указатель на стек, номер инструкции и так далее
В Linux процессы порождаются с помощью других процессов, таким образом, образуя дерево
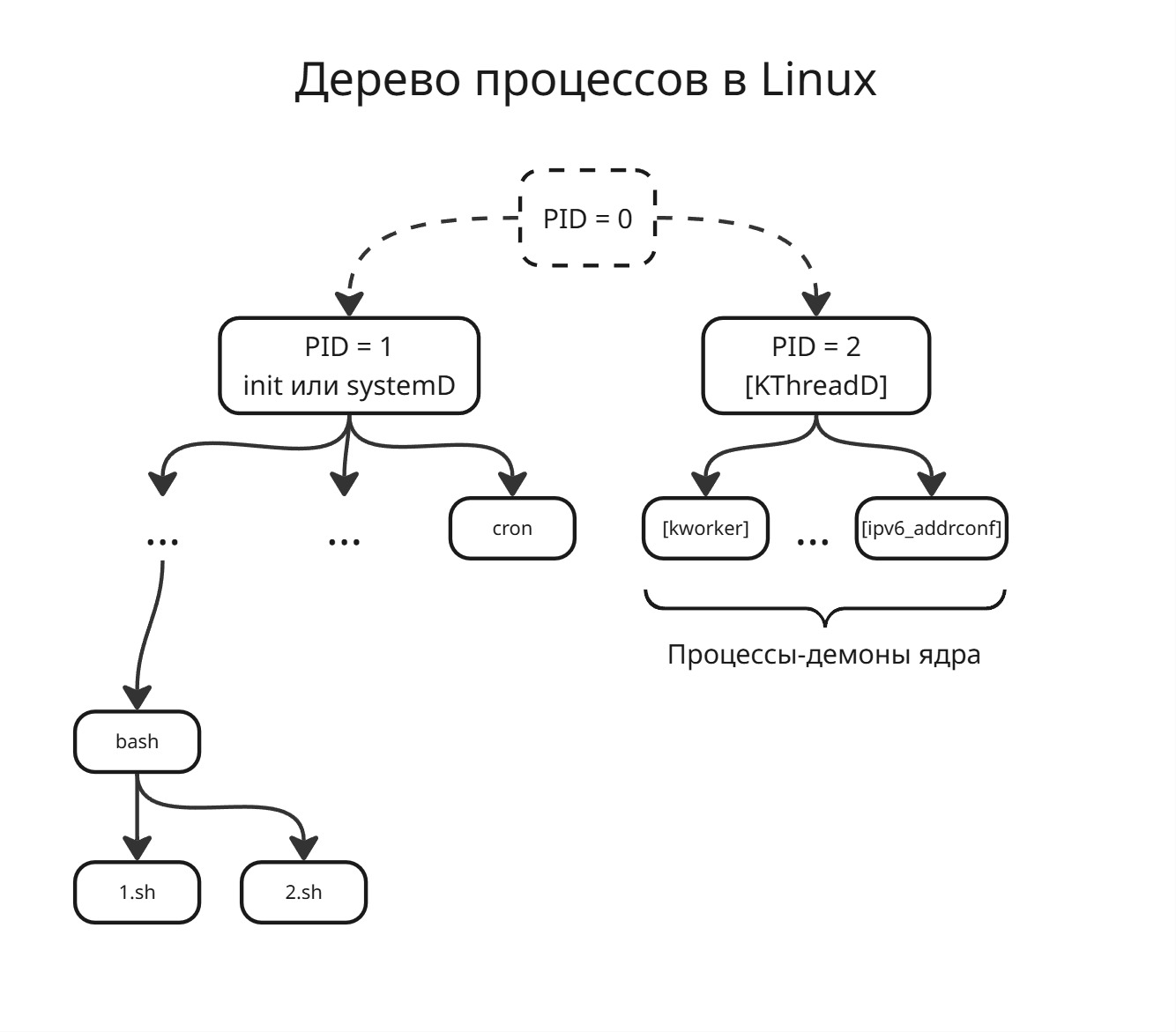
Дерево как структура было выбрано по нескольким причинам:
-
Процессы имеют только одного создателя - структура уже выходит иерархической, поэтому дерево самое подходящее отображение такой структуры
-
Обработка ошибок
Когда дочерний процесс умирает по своей причине или из-за исключения, кто-то должен прочитать его код выхода, сделать дамп памяти и другое, чтобы пользователь узнал, что не так случилось в ходе работы
-
Распространение сигналов
Для общения между процессами используются сигналы. Дерево позволяет сделать отправку одного сигнала группе процессов намного проще, например, сигнала
SIGHUP(от SIGnal Hang UP) для завершения процесса и их детей
Первый процесс - это процесс init или systemD, который является корнем одного поддерева процессов
Создание процесса
Для создания процессов могут использоваться три системных вызова:
-
pid_t fork(void)делает копию процесса. Новый процесс имеет те же указатель на таблицу страниц память (то есть ту же память, что и родитель), те же файловые дескрипторы, те же обработчики сигналов, и те же права доступа, что и родитель, но получает новый идентификаторДля того, чтобы не копировать все адресного пространство, копируют лишь таблицы, а сами страницы помечают флагом “только для чтения”. При попытке записи родителем или ребенком конкретной страницы, возникнет прерывание отказа страницы, вследствие которого ядро скопирует страницу для ребенка. Такой подход называется “копия при записи” (Copy-on-Write)
fork()возвращает-1, если копирование не удалось,0, если процесс является родителей, и идентификатор дочернего процесса в другом случае:pid_t pid = fork(); switch (pid) { case -1: perror("Копия не удалась"); case 0: puts("Этот процесс - ребенок"); default: puts("Этот процесс - родитель"); printf("PID дочернего процесса - %jd\n", (intmax_t) pid); }Источник: https://www.man7.org/linux/man-pages/man2/fork.2.html
-
exec- семейство вызовов, которые заменяют код программы текущего процесса на выбранный в параметрах и удаляет память этого процесса (по сути дает новый указатель на таблицу страниц)Обычно вызов
execделают сразу же послеforkВсего в этом семействе есть 7 системных вызовов:
int execl(const char *path, const char *arg, ... /*, (char *) NULL */)int execlp(const char *path, const char *arg, ... /*, (char *) NULL */)int execle(const char *file, const char *arg, ... /*, (char *) NULL, char *const envp[] */)int execv(const char *path, char *const argv[]);int execvp(const char *file, char *const argv[]);int execvpe(const char *file, char *const argv[], char *const envp[]);int execve(const char *path, char *const _Nullable argv[], char *const _Nullable envp[])
Буквы после
execобозначают тип принимаемых значений:l- аргументы принимаются как список указателей, оканчивающийся нуль-терминаторомv- аргументы принимаются как указатель на массив указателей, оканчивающийся нуль-терминаторомe- новые переменные окружения для процесса указаны в аргументеenvpp- если указанный путь до исполняемого файла не содержит/, то он ищется в директориях, указанных в переменной окруженияPATH
Все эти вызовы, кроме
execve, являются обертками надexecveexecve("/bin/ls", newargv, newenviron); /* Если ошибки не возникло, то исполнение * не перейдет на строки ниже */ puts("Ошибка");Источник: https://www.man7.org/linux/man-pages/man2/execve.2.html
-
clone()- более мощная версияfork(), которая дает больше контроля над тем, что разделяют родительский процесс и ребенок. Сигнатура уclone()такая:int clone(typeof(int (void *_Nullable)) *fn, void *stack, int flags, void *_Nullable arg, ... /* pid_t *_Nullable parent_tid, void *_Nullable tls, pid_t *_Nullable child_tid */ );Здесь передает указатель на функцию
fn(процесс уничтожается, если функция возвращает значение), указатель на стекstackдля дочернего процесса, флагиflags- результат побитового “ИЛИ” константСреди интересных есть флаги:
CLONE_PARENT- делает родителем нового процесса родителя текущего процесса, таким образом, делая их братьямиCLONE_SIGHAND- делает так, что ребенок и родитель имеют одну таблицу обработчиков сигналовCLONE_STOPPED- делает так, что ребенок находится в состоянии “Остановлен”CLONE_VM- делает так, что ребенок и родитель разделяют между собой адресное пространствоCLONE_THREAD- делает так, что ребенок помещен в ту же группу потоков, что и родитель
Как можно заметить, системный вызов
clone()делает создание потоков намного прощеВ результате
clone()возвращает идентификатор потока в случае успехаПомимо
clone()есть также вызов__clone2()для архитектуры IA64 (на ней основана линейка процессоров Intel Itanium) иclone3(), принимающий структуруcl_args, благодаря которой возможно более гибкое создание процессаИсточник: https://www.man7.org/linux/man-pages/man2/clone.2.html
Жизненный цикл процесса
У процесса в Linux есть состояние в зависимости от того, исполняется ли он прямо сейчас, ждет потока ввода/вывода или находится вне оперативной памяти. Состояние помогает при управлении планировании исполнения процессов:
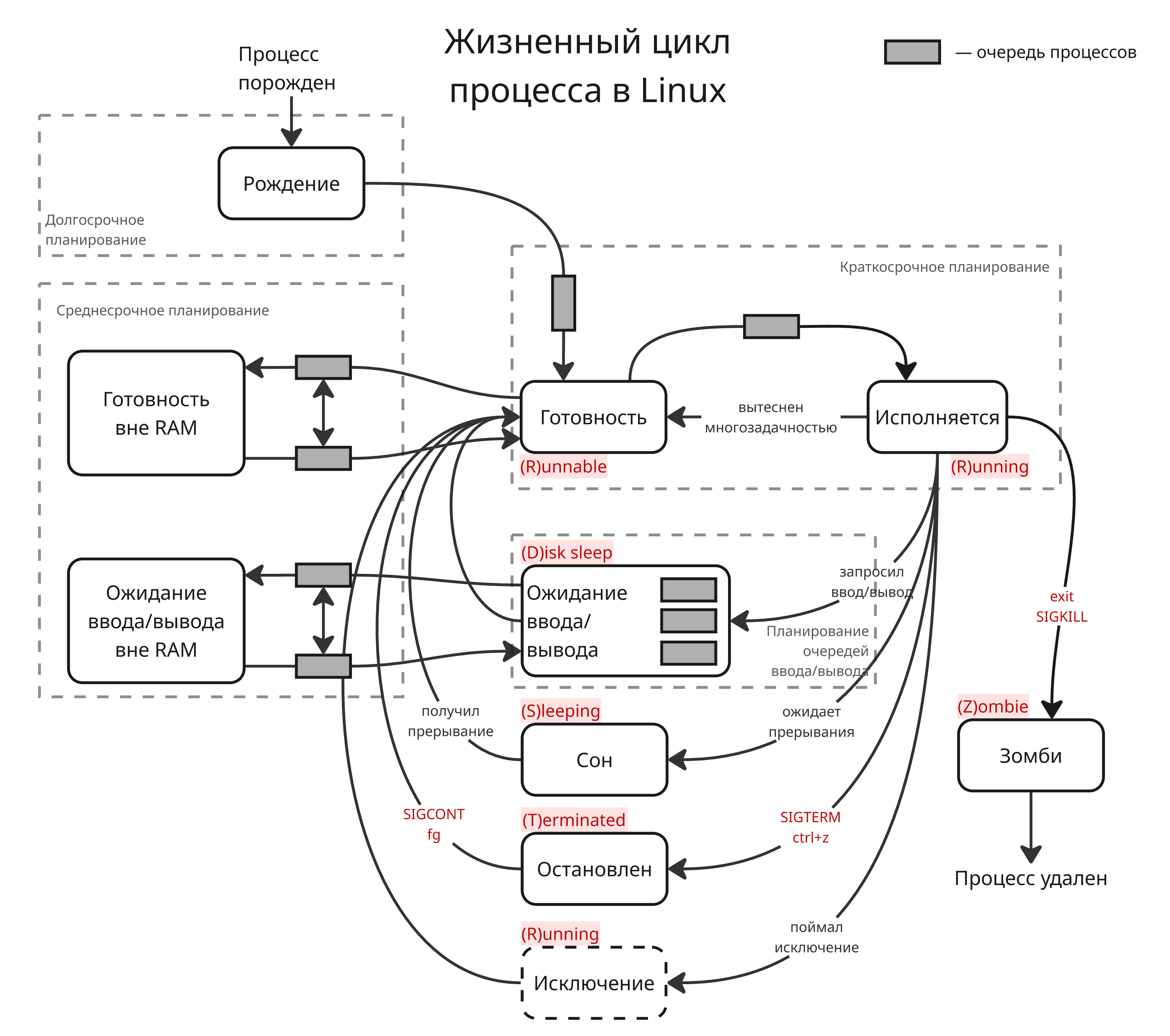
Подробнее о состояниях процессов описано в курсе “Операционные системы”
Завершение процесса
После того, как процесс окончил исполнения (то есть вызвал системный вызов _exit(status_code)), процесс переходит в состояние “Зомби”. В нем он будет находится до тех пор, пока родительский процесс не прочитает код выхода процесса. Родитель может сделать это несколькими способами:
-
Синхронно с помощью системных вызовов
wait,waitid,waitpidЭти системные вызовы приостанавливают исполнение до тех пор, пока дочерний процесс не окончит исполнение.
waitждет смерти любого дочернего процесса, в вызовеwaitpidможно выбрать идентификатор дочернего процесса, аwaitidпозволяет обрабатывать смену некоторых состояний дочернего процессаИсточник: https://www.man7.org/linux/man-pages/man2/wait.2.html
-
Асинхронно с помощью обработчика сигнала
SIGCHLD:signal(SIGCHLD, handler); void handler(int sig) { int status; waitpid(-1, &status, WNOHANG); }
Демоны
Отдельное место в Linux занимают демоны. Демон (Daemon) - это фоновый процесс, который работает непрерывно и независимо от пользовательской сессии. Он ожидает событий или запросов и обрабатывает их без участия пользователя
Название “демон” происходит из греческой мифологии — демон был фоновым духом, действующим от имени других
Стандартные потоки ввода, вывода и ошибок у демонов перенаправлены в /dev/null. Вместо них демоны используют системный журнал или собственный файл с логами. Также демоны записывают свои идентификаторы процессов, чтобы другие процессы знали, как к ним обратиться
Первый демон, появляющийся при запуске Linux, - это поток [kthreadd] с идентификатором 2. Он является корнем поддерева фоновых потоков ядра, таких как [kswapd0] - демон для страничного обмена, [migration/0] - демон для переноса процессов между ядрами и так далее
Для создания демонов можно:
-
В терминале остановленный процесс (например, с помощью
Ctrl+Z) можно обратно вывести в “Готовность” с помощью командыfg(от foreground), а можно вывести в “Готовность” в качестве демона с помощью командыbgАльтернативно терминал позволяет запустить процесс в фоновом режиме, если после команды написать
&:python3 script.py &В таком случае у демона будет стандартный поток вывода, который перенаправлен в терминал
Также после закрытия терминала дочерние фоновые процессы также завершаются. Чтобы этого избежать, можно применить команду
disown:python3 script.py & disown %1Или команду
nohup(от no hang up):nohup python3 script.py & -
На языке C можно:
- Создать копию процесса с помощью
fork() - В родительском процессе сделать
_exit() - В дочернем процессе отсоединиться от терминала с помощью
setsid() - Переопределить обработчик сигнала
SIGHUPна пустой - Создать новый процесс с помощью
fork()и завершить текущий - В третьем процессе выдать нужные права с помощью
umask(), сменить директорию на кореньchdir("/"), закрыть наследованные файловые дескрипторы и перенаправить стандартные потоки в/dev/null
- Создать копию процесса с помощью
-
Более современный способ состоит из создания службы - демона, управляемого другим процессом
В большинстве дистрибутивах (Ubuntu, Debian, Fedora, Arch Linux, CentOS, Red Hat Enterprise Linux) роль менеджера служб играет система
systemdЧтобы создать демон, управляемый
systemd, нужно создать файл объявления:# /etc/systemd/system/myapp.service [Unit] Description=My Application After=network.target # запустить после запуска демона networkd [Service] Type=simple User=myappuser # запустить от имени myappuser ExecStart=/usr/bin/myapp # исполняемый файл Restart=on-failure # перезапустить при падении StandardOutput=journal # записывать логи в журнал systemdДалее он управляется с помощью команд:
systemctl start myapp # запустить сейчас systemctl stop myapp # остановить systemctl enable myapp # запускать при старте системы systemctl status myapp # статус службы systemctl restart myapp # перезапуститьКритика вокруг
systemdзаключается в том, что кодовая базаsystemdчересчур большая, система нарушает философию Unix “одна программа делает одно дело”, так какsystemdпишет логи, занимается монтированием и так далее. Поэтому используют альтернативы:SysV init, использующийся в Unix и дистрибутиве Slackware, является простой системой, но демоны запускаются последовательноrunit- минималистичная система, где сервис создается символической ссылкой/etc/sv/myapp/runна исполняемый файл, используется в Void Linux и Docker-контейнерахOpenRC- улучшенныйSysV init, используется в Gentoo Linux и Alpine Linux
Лекция 5. Процессы, часть II
Сигнал
В операционной системе процессы имеют изолированное адресное пространство, изолированное исполнение, изолированное планирование и не могут повлиять на другие процессы. Поэтому для общения процессы помимо файловой системы могут использовать сигналы
Сигнал - это сообщение, которое процесс получает от операционной системы или другого процесса. С точки зрения процесса сигнал выглядит как прерывание
Согласно стандарту POSIX, сигналы делятся на стандартные и сигналы реального времени
В Linux всего 31 стандартный сигнал. Рассмотрим самые распространенные из них:
| Имя | Код | Назначение | Действие по умолчанию |
|---|---|---|---|
SIGHUP (от hang up) |
1 | Процесс завершается, а дочерние процессы получает этот сигнал, чтобы тоже завершиться. Ранее использовался для обозначения прерывания телефонной связи между терминалом и пользователем (дословно “положить трубку”) | 🛑 |
SIGINT (от interrupt) |
2 | Прерывание выполнения команд от клавиатуры (в терминале вызывается по комбинации Ctrl+C) | 🛑 |
SIGQUIT |
3 | Прерывание с дампом ядра (обычно Ctrl+\), посылается всем процессам группы | 🛑📦 |
SIGILL (от illegal) |
4 | Сигнал, посланный ядром, который означает, что выполнявшаяся инструкция является неправильной с точки зрения архитектуры процессора | 🛑📦 |
SIGFPE (от floating point exception) |
8 | Ошибочная арифметическая операция | 🛑📦 |
SIGKILL |
9 | Немедленное принудительное завершение процесса | 🛑 |
SIGUSR1 и SIGUSR2 |
10 и 12 | Сигналы, определенные пользователем | 🛑 |
SIGSEGV (от segmentation fault) |
11 | Нарушение доступа к памяти, например, доступ к еще невыделенной странице | 🛑📦 |
SIGPIPE |
13 | Процесс написал в именованный канал, но нет процесса, который мог бы прочитать это | 🛑 |
SIGTERM (от terminate) |
15 | Сигнал завершения | 🛑 |
SIGCHLD, также SIGCLD (от child) |
17 | Дочерний процесс завершился, был остановлен или продолжил исполнение | 🙈 |
SIGCONT (от continue) |
18 | Процесс продолжает исполнение | ▶️ |
SIGSTOP |
19 | Перевод процесса в состояние “Остановлен” | ⏸️ |
SIGTSTP |
20 | Сигнал остановки с терминала по комбинации Ctrl+Z | ⏸️ |
По умолчанию каждый процесс имеет таблицу обработчиков сигналов, наследованную от первого процесса (init или systemd). Такие обработчики обычно могут совершать такие действия:
- 🛑 - завершение исполнение процесса (🛑📦 - завершение с сохранением памяти процесса в момент получения сигнала)
- ⏸️ - процесс останавливает исполнение
- 🙈 - игнорирование сигнала
- ▶️ - продолжение исполнения
Здесь код сигнала указан для архитектур x86 и ARM. В других архитектурах (например, MIPS или SPARC) код сигнала может отличаться
Среди этих все, кроме SIGKILL и SIGSTOP, можно перехватить и переопределить обработчики, например, назначить на SIGINT правильной завершение процесса. На сигналы SIGKILL и SIGSTOP операционная система принудительно убивает или переводит процесс в состояние “Остановлен” соответственно
Сигналы реального времени используются для обычных программ. Они не имеют определенного значения, и всего их может быть до 33 – они определены интервалом от SIGRTMIN (чаще всего 34 или 35) и SIGRTMAX (64). Так как разные имплементации потоков библиотеки glibc используют первые 1 или 2 сигнала для своих задач, рекомендуется использовать SIGRTMIN + 3 вместо 37 или 38
Гарантируется, что сигналы реального времени придут процессу в том же порядке, что они были отправлены. Также, если такой сигнал был послан функцией sigqueue, то процесс-приемник может получить число или указатель на дополнительные данные
Источник: https://www.man7.org/linux/man-pages/man7/signal.7.html
Планирование процессов
Подробнее про планирование процессов описано в курсе “Операционные системы”
За время развития операционной системы Linux существовало множество планировщиков:
- O(n) scheduler, использовавшийся в версиях ядра с 2.4 до 2.6
- O(1) scheduler, использовавшийся в версиях ядра с 2.6 до 2.6.23
- Completely Fair Scheduler (CFS, Полностью справедливый планировщик), использовавшийся долгое время (16 лет) в версиях ядра с 2.6.23 до 6.6
- Earliest eligible virtual deadline first (EEVDF, “С самого раннего подходящего для виртуального дедлайна”), использующийся с версии ядра 6.6
В Linux можно выделить 2 типа процессов:
-
Процессы реального времени - обычно, это демоны ядра. Их выполнение приоритетно, так как от их работы зависит работа остальных процессов, поэтому система выполняет сначала их
Для их исполнения используются алгоритм “Первым пришел - первым обслужен” (FCFS) или циклический алгоритм (Round Robin)
-
Пользовательские процессы. У каждого такого процесса есть собственный приоритет исполнения (значение nice), поэтому для них используются более изощренные алгоритмы, такие как CFS и EEVDF
Рассмотрим, как работает Completely Fair Scheduler
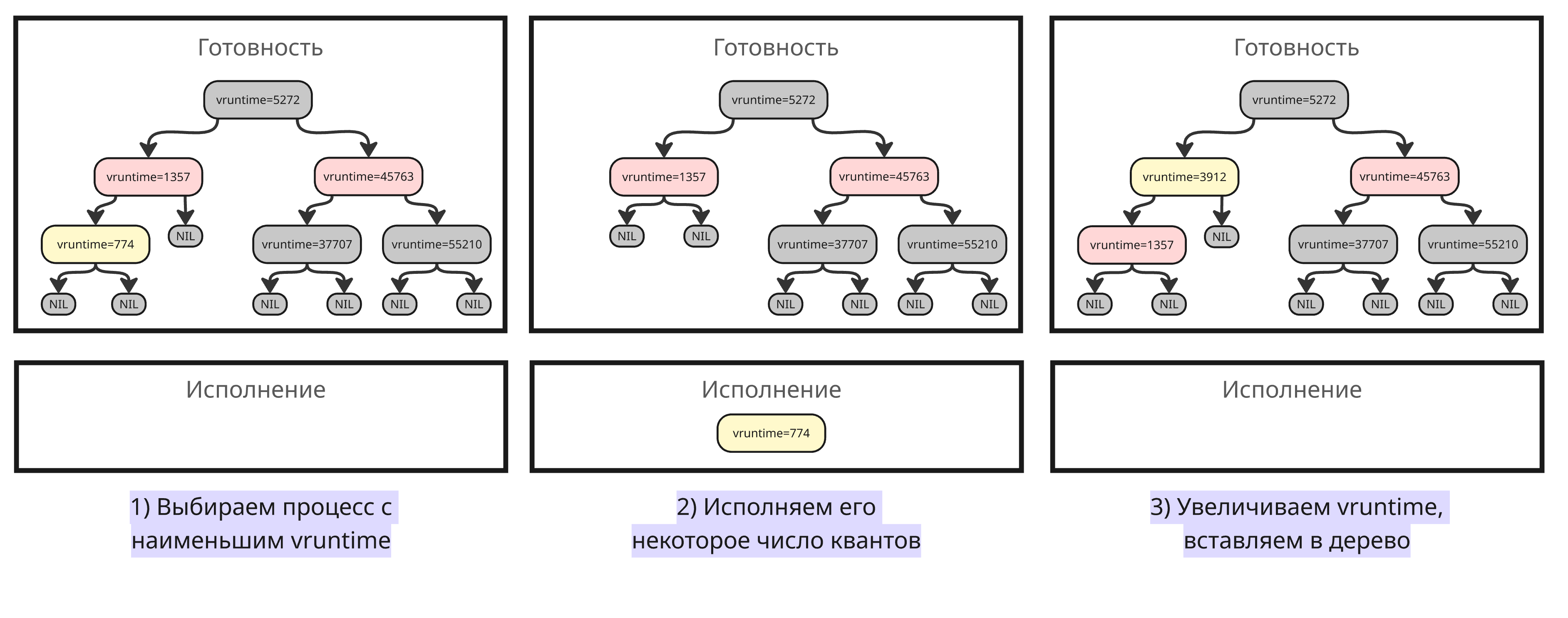
Ключевая идея планировщика - каждый процесс должен получать долю процессорного времени, пропорциональную её весу (то есть приоритету). Вместо фиксированных очередей планировщик CFS использует виртуальное время vruntime для каждой задачи
- Когда процесс порождается другим, его виртуальное время
vruntimeустанавливается таким же, как и у его родителя -
После того, как другой процесс исполнялся некоторое число квантов, планировщик находит процесс с наименьшим
vruntimeи начинает его исполнение. Его исполнение заканчивается, если:- Он был остановлен, завершил исполнение или перешел в ожидание ввода/вывода
- Появилась другая задача с меньшим
vruntime - Время его исполнения превысилось некоторое число квантов исполнения (условных единиц). Это число зависит от веса процесса и текущего множества готовых к исполнению процессов
-
После исполнения
delta_execсекунд планировщик обновляетvruntimeпо такой формуле:vruntime += delta_exec * weight / lw.weightЗдесь
weight- вес текущего процесса (примерно1024 / (1.25 ^ nice_value),nice_value- это значение параметра nice), аlw.weight- вес опорной сущности, например, вес для процесса с nice=0 или установленный вес для группы процессов - Выбирается следующий процесс с минимальным
vruntimeи так далее
Сами процессы с vruntime должны где-то храниться, причем операции добавления удаления должны быть быстрыми. По этой причине выбрали красно-черное дерево - процессы отсортированы по величине vruntime, а само дерево является самобалансирующимся, то есть в любой момент времени его высота примерно равна log N, а все операции имеют сложность O(log N)
Подробнее про CFS: https://www.kernel.org/doc/html/latest/scheduler/sched-design-CFS.html, https://developer.ibm.com/tutorials/l-completely-fair-scheduler/
Исходный код CFS: https://github.com/torvalds/linux/blob/v6.5/kernel/sched/fair.c
Completely Fair Scheduler полагался на множество эвристик и параметров, чтобы корректно работать с интерактивными и фоновыми задачами
Новый алгоритм Earliest eligible virtual deadline first вместо этого имеет математический подход. В нем есть три понятия:
- Виртуальное время выполнения, как и в CFS
- Лаг - разница между тем, сколько процессорного времени задача должна была получить (согласно своему приоритету), и тем, сколько она реально получила
- Виртуальный дедлайн - момент времени, к которому задача должна получить свое процессорное время
На каждом шаге EEVDF:
- Находит задачи с положительным лагом. Такие задачи называются подходящими (eligible)
- Среди них выбирает ту, у которой самый ранний виртуальный дедлайн (earliest virtual deadline)
Однако процессы могут кратковременно засыпать, чтобы повышать свой лаг, что делает планировщик несправедливым. Чтобы бороться с этим, планировщик не убирает такие задачи из очереди “Готовность”, а также меньше уменьшает их лаг
Статья про EEVDF: https://citeseerx.ist.psu.edu/document?doi=805acf7726282721504c8f00575d91ebfd750564&repid=rep1&type=pdf
Документация про EEVDF: https://docs.kernel.org/scheduler/sched-eevdf.html
Псевдофайловая система /proc/
Для доступа к сведениям процессов есть псевдофайловая система /proc/, которая представляет из себя набор файлов для каждого процесса. При чтении одного из файлов в этом подкаталоге данные достаются не из диска, а из оперативной памяти
Директория /proc/ содержит множество поддиректорий вида /proc/<PID> с числовыми названиями. Это число представляет из себя идентификатор процесса, а поддиректория хранит информацию о процессе, а именно:
- файл
/proc/<PID>/cmdline- полная командная строка запуска процесса - символьная ссылка
/proc/<PID>/exeна исполняемый файл. Иногда команда запуска может быть видаnano test.sh, где программаnanoможет быть в/bin/nano, а может быть другой утилитой из другого места - символьная ссылка
/proc/<PID>/cwdна текущий каталог, относительного которого процесс исполняется (от current working directory) -
файл
/proc/<PID>/environ, содержащий переменные окружения процесса -
файл
/proc/<PID>/status, содержащий общую информацию о процессе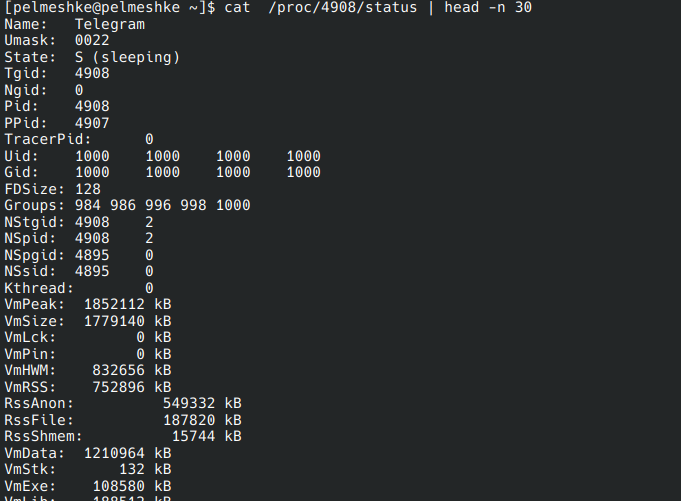
Также есть файл
/proc/<PID>/stat, содержащий статистику в машиночитаемом виде -
файл
/proc/<PID>/io, содержащий статистику операциям хранилища в таком виде:rchar: 131804676 wchar: 1467923 syscr: 30982 syscw: 40879 read_bytes: 296783872 write_bytes: 1097728 cancelled_write_bytes: 8192 -
файл
/proc/<PID>/maps, содержащий информацию о выделенных страницах памяти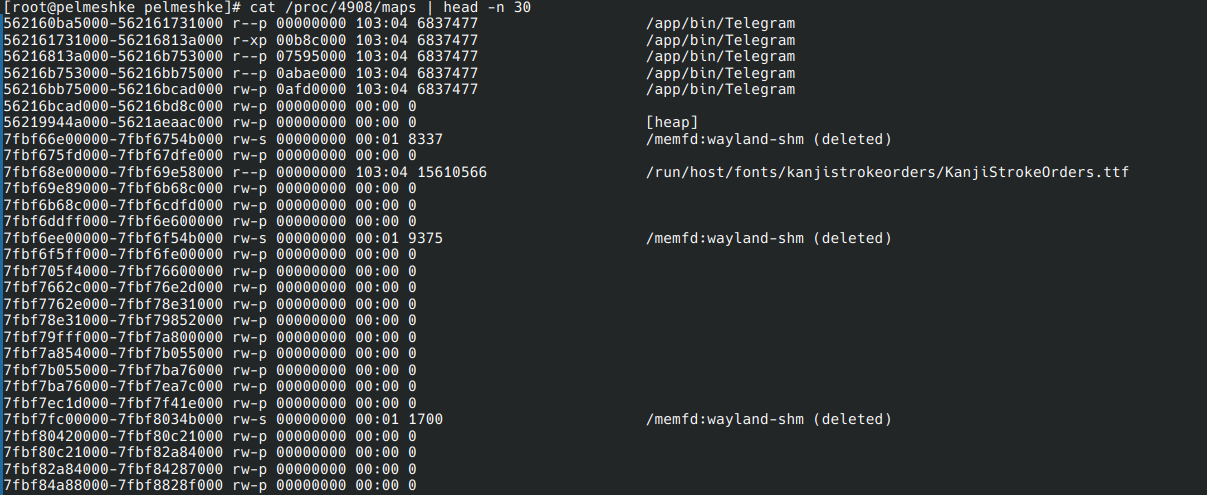
Вместе с ним есть файл
/proc/<PID>/pagemap, который содержит 64-битные числа, представляющие каждую страницу в машиночитаемом виде -
файл
/proc/<PID>/statm, хранящий информацию о размерах структуры памяти процесса в 7 числах. Например:440853 192627 48735 27145 0 300709 0Здесь:
440853- общий размер программы192627- размер резидентной части (та часть используемой памяти, которая находится в ОЗУ)48735- размер разделенной памяти, которая используется несколькими программами27145- размер сегмента, отведенного под код программы0- размер библиотек, не используется с версии ядра 2.6300709- размер данных и стека0- размер грязных страниц, не используется с версии ядра 2.6
-
файл
/proc/<PID>/sched, содержащий статистику планировщика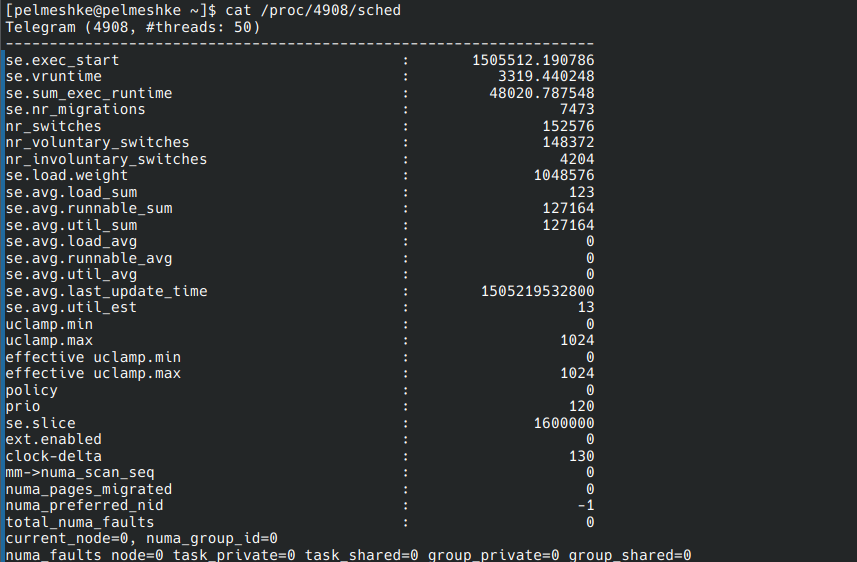
-
директория
/proc/<PID>/fd, содержащая информацию об открытых файловых дескрипторах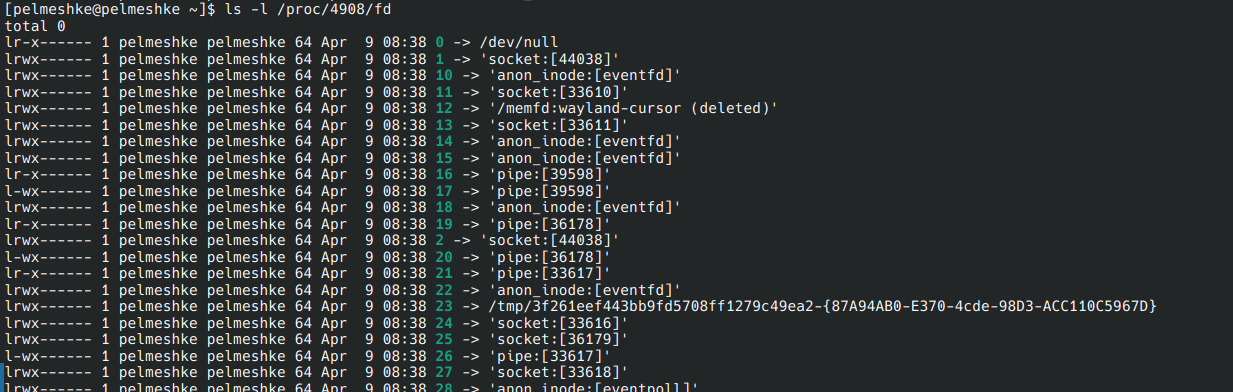
Помимо информации для каждого процесса /proc/ хранит общую информацию об операционной системе
-
Файл
/proc/cmdline- аргументы запуска ядра, например:BOOT_IMAGE=/vmlinuz-linux-zen root=UUID=90811ff5-ecb7-4e78-8406-1be8785fe758 rw loglevel=3 quiet -
Файл
/proc/cpuinfo, содержащий информацию о процессорах: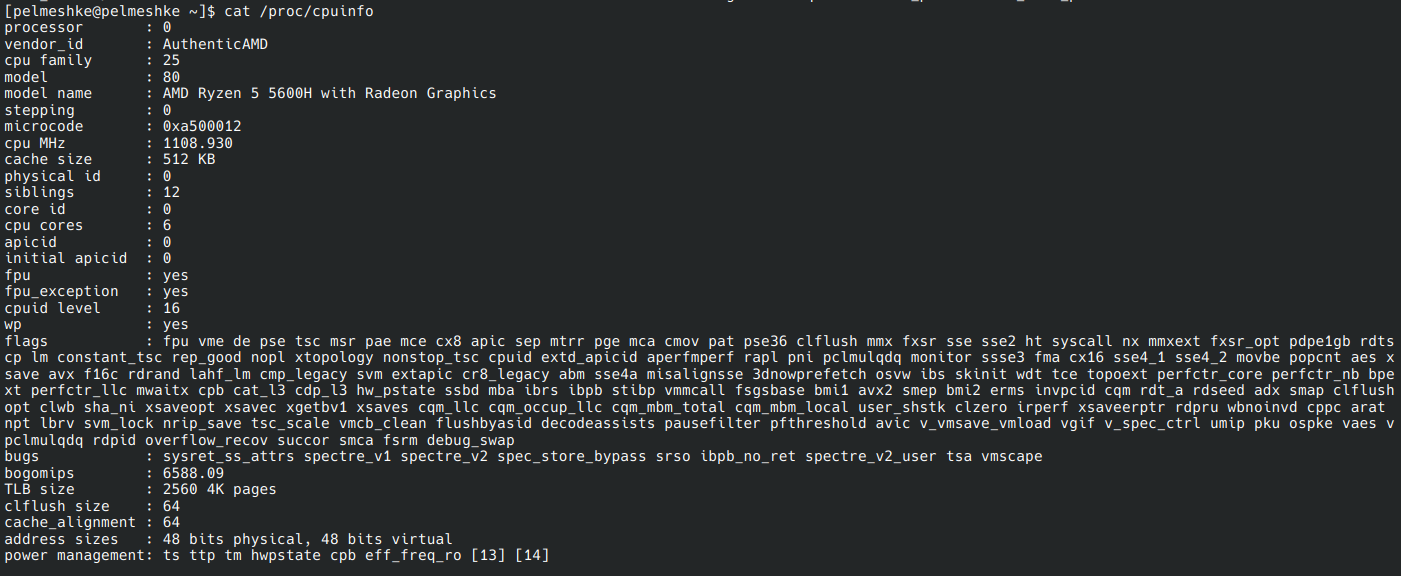
Здесь можно узнать модель процессоров и поддерживаемые инструкции и технологии
- Файл
/proc/diskstats, содержащий статистику операций со всеми дисками -
Файл
/proc/meminfo, содержащий сведения об оперативной памяти: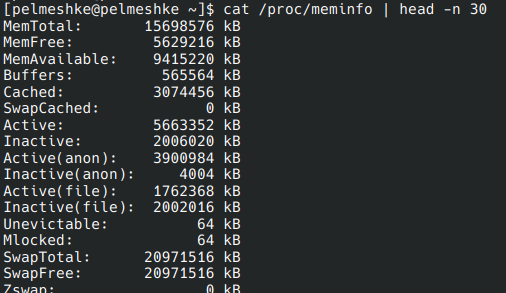
- Файл
/proc/devices- список устройств - Файл
/proc/mounts- список смонтированных файловых систем - Файл
/proc/modules- список загруженный модулей ядра - Файл
/proc/filesystem- список поддерживаемых ядром файловых систем - Файл
/proc/swaps- список разделов подкачки - Файл
/proc/version- версия ядра и дата сборки - Каталог
/proc/sys/kernel/- изменяемые параметры ядра
Лекция 6. Загрузка ОС Linux
Каждый раз, когда пользователь нажимает кнопку питания своего компьютера, до того, как система полностью будет загружена, происходят несколько ключевых этапов:
- Загрузка BIOS/UEFI
- Работа загрузчика
- Загрузка ядра и его инициализация
Загрузка BIOS/UEFI
Сначала запускается BIOS - Basic Input/Output System (Базовая система ввода/вывода). BIOS не является полноценной операционной системой: это прошивка материнской платы, которая выполняет начальную инициализацию оборудования и передает управление загрузчику. В начале запуска компьютера BIOS проводит процедуру POST (Power-On Self-Test) - проверяет работоспособность оборудования (процессора, ОЗУ и так далее)
BIOS узнает о загрузочном коде напрямую из таблицы MBR (Master Boot Record, Главная загрузочная запись), которая расположена в начале любого диска, с которого можно загрузится (или через PXE - Preboot eXecution Environment)
Master Boot Record занимает первый 512 байт (первый сектор на диске) и содержит:
- 440 байт под код загрузчика
- 4 байта под сигнатуру диска
- 2 байта под нули
- 16 байт на каждый из четырех разделов
- 2 байта под сигнатуру
0x55AA
Сейчас же вместо BIOS повсеместно используется UEFI - Unified Extensible Firmware Interface (Единый расширяемый интерфейс прошивки). UEFI - это более современная прошивка, которая поддерживает графический интерфейс, управление мышью и обычно работает с таблицей разделов GPT (GUID Partition Table)
Программный код BIOS и UEFI расположены непосредственно на микросхеме на материнской плате компьютера
Загрузчик GRUB
Далее рассмотрим загрузку Linux в BIOS. BIOS загружает выбранный исполняемый код, который находится в MBR, в ОЗУ, и процессор исполняет его. Для загрузки Linux используют особой компонент - загрузчик. Сейчас самый используемый - это GNU GRUB (GRand Unified Bootloader) версии 2
BIOS
Код из Master Boot Record содержит 1 фазу загрузчика GRUB boot.img - он занимает 440 байт, что недостаточно для полноценной загрузки
boot.img далее запускает фазу 1.5 загрузчика - core.img. Он находится между MBR и первым разделом диска, в нем расположен код базового набора драйверов для файловых систем (ext4, xfs и так далее), для работы с массивом RAID или LVM (Logical Volume Manager, менеджер логических томов). Как правило, размер core.img составляет от 30 до 40 Кб (как правило 62 сектора на диске, максимальный размер - 458 240 байт)
После этого core.img уже может читать файлы из раздела загрузчика (после загрузки он монтируется как /boot/grub и как правило, находится на другом разделе, чем /). core.img загружает код загрузчика из /boot/grub, который прочитывает файл grub.cfg, где находится выбор ОС (в случае Linux это выбор ядра или его версии) - так начинается фаза 2. GRUB запускает графическое меню, где можно выбрать ядро и его параметры:
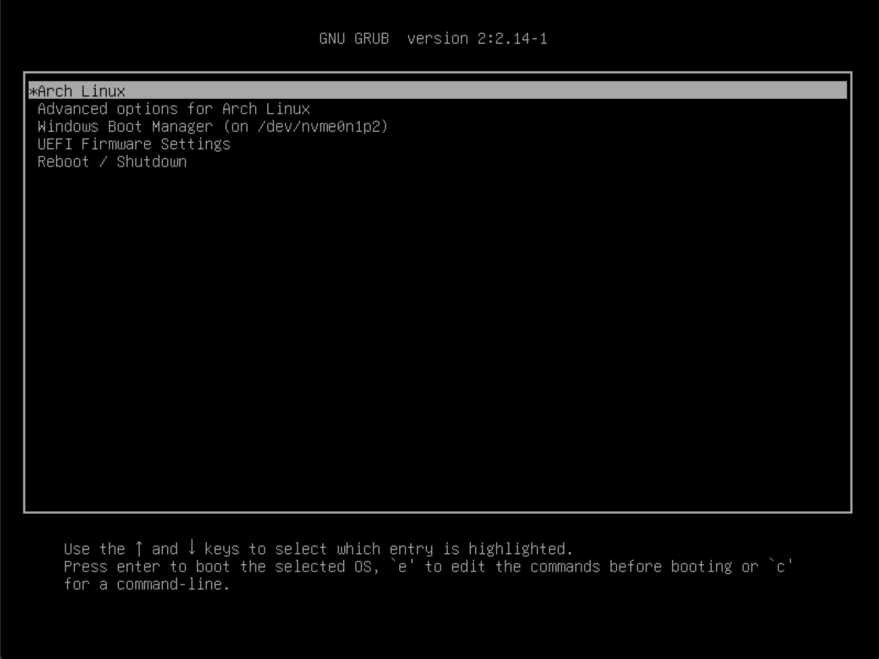
UEFI
Для компьютеров с UEFI все намного проще. UEFI является намного более умным, чем BIOS, и его память на материнской плате содержит драйвера для работы с дисками (в частности для файловых систем FAT16 и FAT32), устройствами USB и сетью
Также UEFI хранит загрузочные записи - они хранят идентификатор GUID раздела и путь до кода загрузчика в специальном разделе ESP (EFI System Partition)
Далее при запуске UEFI ищет на диске этот скрытый раздел ESP, который отформатирован в FAT16 или FAT32. На этом разделе хранятся загрузчики разных ОС и другие инструменты (например, для проверки памяти или для отладки ядра)
При загрузке Linux этот раздел монтируется в /boot/EFI. Структура этого каталога выглядит примерно так:
/boot/EFI
├── ARCH
│ └── grubx64.efi
├── BOOT
│ ├── BOOTIA32.EFI
│ ├── BOOTX64.EFI
│ ├── fbia32.efi
│ └── fbx64.efi
├── Microsoft
│ ├── Boot
│ │ ├── bootmgfw.efi
│ │ ├── bootmgr.efi
│ │ ├── boot.stl
│ │ ├── memtest.efi
│ │ ├── SecureBootRecovery.efi
│ │ └── ...
│ └── Recovery
│ └── ...
└── systemd
└── systemd-bootx64.efi
Главный загрузчик для Windows, Windows Boot Manager, находится в файле Microsoft/bootmgfw.efi. Для Linux (в данном случае дистрибутива Arch Linux) загрузчик расположен в ARCH/grubx64.efi. В BOOT лежит загрузчик по умолчанию: операционная система сначала создает свой загрузчик в BOOT, затем копирует его в отдельную директорию и создает запись в памяти UEFI
Сам файл grubx64.efi представляет собой код из core.img - набор базовый модулей, необходимый для чтения раздела в ext4, конфигурационного файла grub.cfg и загрузки дополнительных модулей
Помимо этого UEFI еще может загружаться через сеть. Для этого он, предварительно получив IP-адрес по протоколу DHCP, скачивает по протоколу TFTP файл bootx64.efi и запускает его
Загрузка ядра
После выбора записи загрузчик GRUB помещает в память образ ядра Linux vmlinuz и образ начальной файловой системы initramfs, а затем передает управление ядру
Для управления загрузкой используется строка аргументов (та, что в последствии находится в /proc/cmdline). В командной строке ядра можно указать путь до vmlinux, путь до корневого раздела (в том числе можно указать UUID диска), режимы загрузки (например, однопользовательский), настройки оборудования, ограничения ресурсов (таких как ОЗУ или ядра ЦПУ) и подобное. Например, строка:
linux /vmlinuz-5.15.0 root=/dev/sda1 ro quiet splash
запускает ядро из /vmlinuz-5.15.0, корневой раздел с диска /dev/sda1, который доступен только в режиме для чтения, с подавлением большинства сообщений ядра (“тихий режим”) и с графическим экраном загрузки
Сам файл vmlinuz - это сжатый образ ядра. Исторически название расшифровывают как vm (virtual memory, виртуальная память) + linu (linux) + z (zipped - сжатый образ). В оперативной памяти ядро распаковывается, переходит в защищенный режим работы процессора, настраивает таблицы страниц, обработчики прерываний, планировщик и начинает обнаружение устройств
На этом этапе ядро еще не может сразу смонтировать настоящую корневую файловую систему /, потому что для этого часто нужны дополнительные модули и драйверы
Именно поэтому вместе с ядром загружается initramfs (от Initial RAM Filesystem) - небольшой архив, который распаковывается в оперативную память и превращается во временную корневую файловую систему
Внутри initramfs обычно находятся:
- утилиты для начальной загрузки
- необходимые модули ядра
- сценарии поиска настоящего корневого раздела
- средства для расшифровки диска, активации массива RAID и менеджер логических томов
Раньше до версии ядра 2.6 вместо initramfs использовался initrd (Initial RAM Disk), который монтировался как блочное устройства
Обычно дальше идут такие процессы:
- Ядро распаковывает
initramfsв память - Запускается ранняя пользовательская программа
/init./initзагружает нужные модули ядра и подготавливает устройства - Находится и монтируется настоящий корневой раздел. Затем выполняется переключение корня из
initramfs, который находится в ОЗУ, в файловую систему раздела на диске - Управление передается уже обычной системе в корневом разделе
Если корневой раздел недоступен, система часто попадает в аварийную оболочку из initramfs, где администратор может вручную диагностировать проблему
Система инициализации
Когда настоящее корневое дерево каталогов уже доступно, ядро запускает первый пользовательский процесс с идентификатором PID = 1. Исторически это была программа init, а в современных дистрибутивах чаще всего таким процессом становится systemd
Процесс PID = 1 - это особый процесс, так как:
- Он является предком почти всех остальных процессов в системе
- Он отвечает за запуск пользовательского пространства
- Он “усыновляет” процессы, потерявшие родителя
- Он участвует в корректном завершении работы системы
Если ядро не может запустить процесс с PID = 1, загрузка прекращается с паникой ядра
SysV init
Классическая система инициализации init, которая появилась в UNIX System III и получила развитие в UNIX System V (сейчас такой init называют SysV init), использовала набор sh-скриптов из каталогов вида /etc/rc*.d/. Они запускались последовательно в соответствии с выбранным уровнем выполнения (так называемым runlevel), который описаны в /etc/inittab.Формат строк в /etc/inittab такой:
<идентификатор>:<уровни исполнения>:<действие>:<командная строка запуска>
В System V уровни выполнения в init были такими:
0- остановка системы1- однопользовательский режим2- многопользовательский режим без доступа в Интернет3- многопользовательский режим4- не используется или переопределяется администратором5- многопользовательский графический режим6- перезагрузка
В распространенных дистрибутивах, таких как Debian, уровни означали другое:
0- остановка системы1- режим восстановления2,3,4- частичный режим, где не все службы запущены5- полноценный режим6- перезагрузка
Уровень 1 обычно предназначен для загрузки ОС и ее восстановления
В файле /etc/inittab поле <действие> определяет режим запуска процесса, например:
wait- запустить и ждать завершения, до тех пор не продолжать запуск других процессовrespawn- перезапускать после завершенияsysinit- выполнить на раннем этапе загрузкиonce- запустить и продолжитьctrlaltdel- запустить, если нажата комбинация Ctrl+Alt+Deloff- если процесс выполняется, то он будет принудительно завершенpowerfall- процесс запускается, еслиinitполучил сигналSIGPWR(проблема с питанием)boot- процесс запускается при загрузке системы до перехода на любой уровень выполненияbootwait- процесс запускается при загрузке системы, аinitдожидается его завершения
Сам файл /etc/inittab может выглядеть так:
# Уровень выполнения по умолчанию
id:5:initdefault:
# Скрипт, выполняемый при загрузке системы (до уровней выполнения)
si::sysinit:/etc/rc.d/rc.sysinit
# Запуск скриптов для конкретного уровня выполнения
l0:0:wait:/etc/init.d/rc 0
l1:1:wait:/etc/init.d/rc 1
l2:2:wait:/etc/init.d/rc 2
l3:3:wait:/etc/init.d/rc 3
l4:4:wait:/etc/init.d/rc 4
l5:5:wait:/etc/init.d/rc 5
l6:6:wait:/etc/init.d/rc 6
# Действие при нажатии Ctrl+Alt+Del - перезагрузка
ca::ctrlaltdel:/sbin/shutdown -t3 -r now
# Действие при кратковременном сбое питания (перезагрузка через 2 минуты)
pf::powerwait:/sbin/shutdown -f -h +2 "Power Failure; System Shutting Down"
# Запуск виртуальной консоли
1:2345:respawn:/sbin/mingetty tty1
Здесь /etc/init.d/rc - скрипт, который запускает другие скрипты из каталога /etc/rc<уровень>.d. Уровень - это первый аргумент вызова /etc/init.d/rc
В каталоге /etc/rc.d/rc<уровень>.d скрипты обычно имеют такое наименование: K<NN><имя_сервиса> или S<NN><имя_сервиса>. Буква K означает, что сервис нужно остановить при выходе из уровня, а S означает, что его нужно запустить при переходе в этот уровень
Другая команда, sysinit, выполняется один раз перед переходом в любой уровень исполнения. Ее задачи:
- монтирование
/proc,/sys,/dev - проверка и монтирование корневой файловой системы
- настройка переменных окружения
- загрузка модулей ядра (из
/etc/modules) - установка системных часов
- и так далее
В большинстве современных дистрибутивов сейчас вместо SysV init используется systemd. Он запускает службы параллельно, использует декларативные файлы вида и умеет отслеживать зависимости между компонентами системы
О нем подробно описано в разделе systemd
Подытоживая, загрузку ОС Linux можно описать так:
- BIOS/UEFI выполняет начальную инициализацию оборудования и находит загрузчик
- Загрузчик GRUB считывает конфигурацию, позволяет выбрать ОС или ядро и загружает
vmlinuzиinitramfs - Ядро Linux инициализирует память, процессор, драйверы и базовые подсистемы
initramfsпомогает ядру найти и смонтировать настоящий корневой раздел- После переключения на основную файловую систему ядро запускает первый процесс
- Процесс с
PID = 1(initилиsystemd) запускает службы и переводит систему в рабочее состояние
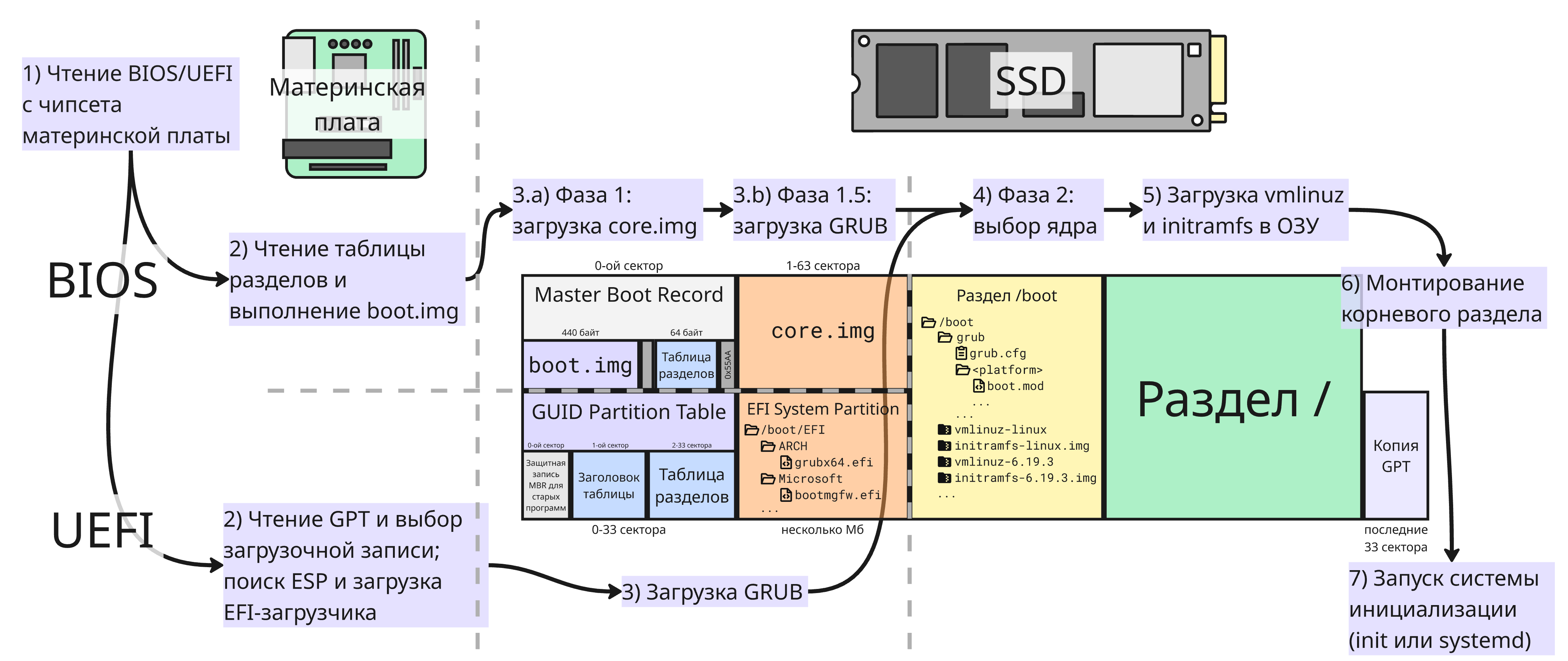
Последовательность загрузок разных частей операционной системы расширяет функционал до тех пор, пока система может взаимодействовать с оборудованием, и решает проблему “курицы и яйца”
X. Программа экзамена 2025/2026
- Отличия ОС семейства GNU/Linux от других ОС с точки зрения администрирования.
- Понятие файла в операционных системах GNU/Linux. Типы файлов. Атрибуты файлов.
- Управление правами доступа к файлам и директориям.
- Организация файловых систем в ОС GNU/Linux: особенности файловых систем ext2, ext3, ext4.
- Структуры данных файловых систем ext3, ext4: структура группы блоков; структура суперблока; структура индексного дескриптора.
- Монтирование файловых систем. Ручное и автоматическое монтирование.
- Понятие процесса в GNU/Linux. Рождение процесса.
- Процессы-демоны. Сигналы.
- Отображение структур данных о процессе в псевдофайловую систему /proc/
- Загрузка операционной системы Linux: Организация работы загрузчика. Загрузка ядра. Стартовый виртуальный диск.
- Загрузка операционной системы GNU/Linux по модели System V: стандартный процесс init: структура файла inittab, условия выполнения команд, уровни выполнения, скрипты sysinit и rc.
- Запуск ОС GNU/Linux по моделям UpStart и SystemD.
- Установка пользовательского программного обеспечения в операционных системах GNU/Linux. Способы установки, их отличия и области применения.
- Установка пользовательского ПО из исходного кода.
- Пакетная установка пользовательского ПО: внутреннее устройство пакетов Debian.
- Пакетная установка пользовательского ПО: внутреннее устройство пакетов RPM.
Extra 1. Современные системы инициализации
Данный конспект был основан на записи лекции №9 (*тык*) с канала А. В. Маятина
Система инициализации init из UNIX System V в своей архитектуре имела недостаток: скрипты установленного уровня выполнения исполнялись последовательно единожды непосредственно после загрузки ОС. Из-за этого:
- Скрипты нельзя запускать параллельно
- SysV init не умеет реагировать на события, например, с подключенными во время работы ОС устройствами. Для таких сценариев требовались отдельные механизмы
- Такой последовательный список зависящих друг от друга скриптов трудно изменять: если скрипт A зависит от B и C, то его имя должно быть в лексикографическом порядке дальше, чем B и C
- SysV init после запуска скриптов далее не наблюдала за ним, из-за чего ответственность на перезапуск упавшего сервиса перекладывалась на администратора системы
Upstart
В 2006 году компания Canonical, которая поддерживает дистрибутив Ubuntu, разработала замену - систему Upstart
Upstart был основан на событиях, которые заменили уровни исполнения. Такими событиями были:
- Изменения в аппаратной части, например, подключение флешки
- Состояния системы, такими как доступность новой файловой системы или сетевой части
- Состояния сервисов. Завершение одного сервиса может привести к запуску другого
Такой асинхронный подход позволяет сервисам запускаться параллельно, если это возможно. Помимо этого Upstart был обратно совместимым с SysV init, что позволяло легко мигрировать на Upstart
Upstart стал системой инициализации в Ubuntu в 2006, в Fedora и Red Hat Enterprise Linux в 2010
Сама же система Upstart работает так: есть список заданий (job), которые как правило либо сервисы, либо краткосрочные задачи. Само описание заданий хранится в конфигурационных файлах /etc/init/<задание>.conf. Upstart постоянно отслеживает изменения в этих файлах
- При старте демон
init(из/sbin/init) читает все описания заданий из/etc/init/ - Загруженное задание находится в цели
stopи состоянииwaitingи ждет наступления указанного в нем события - Как только событие происходит, цель задания меняется на
start, и оно последовательно проходит стадии:starting->pre-start->spawned->post-start->running - Когда наступает событие для остановки, цель меняется на
stop, и задание переходит в цепочку состояний:pre-stop->stopping->killed->post-stop->waiting
Само описание может выглядеть так:
# Описание сервиса
description "Мой сервис"
# Условия запуска: когда система переходит на "обычный" уровень
# и когда сетевые интерфейсы подняты
start on (runlevel [23] and net-device-up IFACE=eth0)
# Условия остановки: когда система выключается или перезагружается
stop on runlevel [!23]
# Команда, выполняемая при запуске сервиса
exec /usr/bin/my-server
# Перезапуск при падении
respawn
Несмотря на это, Upstart имел много недостатков:
- Upstart построен на событиях, вместо простых зависимостей, что не позволяло реализовывать сложные случаи
- Upstart использовал системный вызов
ptraceдля отслеживания состояния процессов, но этот метод конфликтовал с другими инструментами и считался небезопасным - Upstart не имел достаточного функционала “из коробки”, такого как журналирование, таймеры или запуск при первом обращении к сокету
В 2010 появилась система инициализации systemd. Далее с 2015 года systemd поставлялась во всех дистрибутивах, заменив Upstart и SysV init. Это привело к прекращению разработки Upstart в сентябре 2014 года
systemd
В конце 2009 года инженеры Леннарт Пёттеринг и Кей Зиверс из компании Red Hat сформулировали основные принципы будущей системы, которая бы заменила SysV init и Upstart. Тогда архитектор Леннарт Пёттеринг заметил, что:
-
Как правило, процессы общаются через сокеты, и общаются они не сразу же после создания. Тогда, если сервис A зависит от сервиса B, можно сразу запускать сервис B. По мере того, как сервис A начнет что-то писать в сокет, новая система может передать уже открытый сокет сервису, который ещё не запущен, чтобы тот начал обрабатывать поступившие соединения
Такой подход ускоряет загрузку и упрощает перезапуск зависимых служб, но существует риск того, что при сбое потеряются важные данные
-
Монтирование файловых систем происходит непосредственно после запуска ОС, однако сама файловая система используется через некоторое время
Тогда запросы к файловой системе можно забуферизовать, подключить файловую систему и выполнить их в тот момент, когда файловая система готова
-
Классический
initпри запуске обычной системы много раз задействовал тяжеловесные утилиты, а именно: 77 разgrep, 92 разаawk, 74 разаsed, 23 разаcatи так далееВ половине случаев возможности этих утилит были избыточны для их применения, но в память загружался и выгружался весь код утилит
Поэтому приняли решение вместо них использовать готовые функции на C
Все эти недочеты были учтены в новой системе - systemd
Также systemd заменила уровни выполнения на цели. Цели представляли целевые состояния ОС, такие как многопользовательский режим или режим с графической подсистемой
Вместо заданий в systemd появились юниты. Юниты описывались текстовыми файлами в каталоге /usr/lib/systemd/system/, а расширение указывало на тип юнита:
.service- сервис, который запускает демон.socket- сокет, к которому можно было настроить свой обработчик.device- устройство, к которому можно было настроить свой обработчик.mount- точка монтирования при загрузке ОС.automount- точка монтирования по требованию (загружается при первой обращении).target- цель. Помимо этого systemd позволяет строить иерархию целей из зависимостей, например, можно сделать так, чтобы переход в графический режим был невозможен без перехода в многопользовательский режим.timer- таймер- и другие
Внутри текстовый файл содержит ее описание. Например, простой сервис может выглядеть так:
[Unit]
Description=My Application
After=network.target # нужна цель `network`
[Service]
User=myappuser # запустить от имени myappuser
ExecStart=/usr/bin/myapp # исполняемый файл
Restart=on-failure # перезапустить при падении
StandardOutput=journal # записывать логи в журнал systemd
В секции [Unit] указывались зависимости сервиса:
Requires- жесткая зависимость, если зависимость не запустилась, текущий юнит тоже не запуститсяWants- мягкая зависимость, неудача запуска юнита не повлияет на состояние текущегоRequisite- проверка состояния, если указанный юнит не активен, то текущий юнит не запускаетсяConflicts- останавливает указанный юнит, если он запущен, и не позволяет работать параллельноAfter- запускает текущий юнит после указанногоBefore- запускает текущий юнит до указанного
В секции [Install] можно указать обратные зависимости:
WantedBy- обратныйWantsRequiredBy- обратныйRequires
При загрузке systemd читает конфигурацию, монтирует файловые системы, поднимает сеть, запускает системные службы и доводит систему до нужного целевого состояния, например до multi-user.target (многопользовательский режим) или graphical.target (режим с графической оболочкой)
Также systemd предоставляет инструменты для управления юнитами
systemctl start my-serviceзапускает сервисmy-service.servicesystemctl stop my-serviceостанавливает сервисsystemctl enable my-serviceвключает автозапуск, но не запускает сервисsystemctl disable my-serviceотключает автозапуск-
systemctl set-default my-targetустанавливает цель (по сути эта команда делает символическую ссылку/etc/systemd/system/default.targetна/usr/lib/systemd/system/my-target.target)Текущую цель можно посмотреть через
systemctl get-default systemctl status my-service- посмотреть состояние сервиса и последние логиsystemctl restart my-service- перезапустить сервисjournalctl -u my-service- посмотреть логи конкретного сервиса (journalctl -f- слежка в реальном времени)
Кроме этого вместо привычного названия процесса init появилось /usr/lib/systemd/systemd, что критиковалось многими консерваторами
Но у systemd есть недостатки:
- Нарушение философии Unix - вместо простого демона systemd превратился в огромный фреймворк, включающий множество компонентов для журналирования, управления сетью и другого
- Критики опасались, что компания Red Hat получит слишком большой контроль над экосистемой Linux
- В отличие от простоты SysV init, systemd критиковали за излишнюю сложность и связанность компонентов
Тем не менее сейчас почти все популярные дистрибутивы используют systemd
Другие системы инициализации
Помимо популярного systemd немногие дистрибутивы используют менее громоздкие решения
-
runit
runit была создана для замены SysV init как легковесная и кроссплатформенная система. runit придерживается философии Unix “программа должна делать что-то одно, но делать это хорошо” и занимается исключительно инициализацией системы и контролем за сервисами, не беря на себя другие функции, как это делает systemd
Каждый сервис в runit - это просто папка с файлом
run, который запускает процесс в фонеrunit очень быстрая и экономичная система, что делает её популярной в контейнерах и встраиваемых системах
-
OpenRC
OpenRC была создана разработчиками Gentoo для замены набора скриптов инициализации этого дистрибутива, но сейчас доступна и в других системах
В отличие от SysV init, OpenRC понимает зависимости между сервисами и, где возможно, запускает их параллельно, ускоряя загрузку
OpenRC не заменяет
initцеликом, а работает поверх него, что позволяет ей быть очень гибкой и не требовать кардинальной перестройки системы. -
launchd
Система launchd была создана компанией Apple в 2005 году для Mac OS X 10.4 Tiger. До версии 10.4 операционная система Mac OS X (которая является ответвлением от ОС BSD) использовала SysV init
Процессы в launchd могут быть запущены только тогда, когда они действительно нужны - то, что потом переняла система systemd
Конфигурация каждого сервиса в launchd хранится в простых XML-файлах формата
.plist. Для работы с launchd используется командаlaunchctlВ 2006 году дистрибутив Ubuntu Linux рассматривался с использованием системы launchd, но тогда такое решение было отклонено, так как launchd лицензировалась под Apple Public Source License, что могло создать проблемы. Сейчас же launchd лицензируется под проприетарной лицензией
Extra 2. Механизмы контейнеризации
Контейнеризация - это метод виртуализации на уровне операционной системы, позволяющий запускать приложения в изолированных окружениях, которые называют контейнерами
В отличие от виртуальных машин, которые эмулируют аппаратное обеспечение, контейнеры используют ядро хостовой системы, что делает их значительно более легковесными и быстрыми в запуске
В операционной системе Linux контейнеризация возможна с помощью этих механизмов:
- Пространства имён (Namespaces) отвечают за изоляцию процессов, создавая иллюзию того, что контейнер владеет собственным экземпляром системы
- Контрольные группы (cgroups) отвечают за ограничение и учёт ресурсов, потребляемых группой процессов
- И других, таких как объединённые файловые системы
Пространства имён
Пространства имён - это механизм ядра, который изолирует и виртуализирует глобальные системные ресурсы. Процессы внутри одного пространства имён видят свой собственный изолированный набор этих ресурсов и не могут влиять на процессы в других пространствах имён или видеть их
Linux поддерживает несколько типов пространств имён, каждый из которых изолирует определённый аспект системы:
- Cgroup - изолирует корневую директорию контрольных групп, чтобы процесс в контейнере видел свою иерархию контрольных групп.
- IPC (от Inter-Process Communication) - изолирует ресурсы для межпроцессного взаимодействия (такие как очереди сообщений или разделяемая память)
- Network - изолирует сетевые устройства, стеки, порты и таблицы маршрутизации
- Mount - изолирует точки монтирования файловых систем
- PID (от Process ID) изолирует пространство идентификаторов процессов. Процесс внутри контейнера видит только свои процессы и считает, что его идентификатор равен 1, а не реальному идентификатору на хосте
- Time - изолирует системное время, позволяя контейнеру иметь своё представление о времени (появилось в Linux 5.6)
- User - изолирует идентификаторы пользователей и групп, что позволяет процессу в контейнере быть пользователем
rootвнутри контейнера - UTS (от UNIX Time-Sharing System) - изолирует имена хоста и домена NIS (Network Information Service, системы для распространения конфигурации между несколькими узлами)
Самый простой способ создать пространств имён - это использовать утилиту unshare. Она запускает программу в новых, изолированных пространствах имён. Например, для создания пространства UTS используется команда:
sudo unshare --uts /bin/bash
Далее командой hostname <новое имя хоста> можно задать другое имя. Для создания других пространств используются флаги --ipc, --mount, --net, --pid, --uts, --user, --cgroup, --time
Важно заметить, что для создания пространства PID нужно использовать флаг --fork, иначе просто изменится псевдофайловая система /proc
Контрольные группы
Контрольные группы позволяют ограничивать, приоритизировать и учитывать использование таких ресурсов, как центральный процессор, память, ввод/вывод диска и сеть
Существует две версии контрольных групп:
- Cgroups v1 - исторически первая версия, где каждый контроллер управлялся отдельно и мог иметь свою собственную иерархию
- Cgroups v2 - современная и рекомендуемая версия, которая использует единую унифицированную иерархию для всех контроллеров
Начиная с Linux 5.10, вторая версия является предпочтительной, и многие современные дистрибутивы используют её по умолчанию
Все операции с контрольными группами второй версии производятся через псевдофайловую систему cgroup2, которая обычно смонтирована в /sys/fs/cgroup
Далее, чтобы создать контрольную группу, нужно:
-
Создать директорию для новой группы:
sudo mkdir /sys/fs/cgroup/my-groupСозданная директория наполнится нужными файлами. Группы могут выстраивать иерархию с наследованием ограничений
-
Настроить лимиты в нужных файлах
-
Запустить процесс и поместить его в группу - для этого нужно записать идентификатор процесса в файл
cgroup.procs:echo $APP_PID | sudo tee /sys/fs/cgroup/my-group/cgroup.procs
Всего контроллеров во второй версии контрольных групп девять:
cpu- контроллер для ограничения выделяемого процессорного времениcpuset- контроллер для привязки процессов к определенным ядра ЦПУfreezer- контроллер для временной остановки всех процессов в группеhugetlb- контроллер для ограничения лимита на использование больших страниц памяти ОЗУ (они бывают по 64 Кб (только для ARM), 2 Мб и 1 Гб)io- контроллер для ограничения доступа к блочным устройствам ввода/выводаmemory- контроллер для ограничения выделяемой оперативной памяти (в том числе раздела подкачки)perf_event- контроллер для сбора статистики потребляемых ресурсов группы процессовpids- контроллер для ограничения количества созданных в группе процессовrdma- контроллер для ограничения доступа ресурсов, связанных с RDMA (Remote Direct Memory Access), технологией доступа к памяти удаленного узла
Список доступных контроллеров можно узнать в файле /sys/fs/cgroup/cgroup.controllers. Чтобы добавить контроллер, можно воспользоваться командой:
echo "+cpu" | sudo tee /sys/fs/cgroup/cgroup.subtree_control
Управлять списком контроллеров можно в каждой группе, выстраивая иерархию. Контроллер создает нужные файлы в каталоге группы, например:
cpu.max- верхнее ограничение процессорного временmemory.max- верхнее ограничение выделяемой памяти,memory.swap.max- верхнее ограничение для раздела подкачкиpids.max- ограничение на количество процессов в группе
Другие механизмы изоляции
По умолчанию контейнер, созданный с изолированным сетевым пространством имён, будет полностью отрезан от сети. Чтобы обеспечить связь, необходимо создать виртуальные сетевые интерфейсы
Для этого используют veth (Virtual Ethernet) - пару виртуальных сетевых интерфейсов, которые действуют как туннель
Обычно один конец пары veth1 помещается в сетевое пространство имён контейнера, а другой veth0 остаётся на хосте или подключается к сетевому мосту
Чтобы контейнер имел доступ к внешней сети, на хосте необходимо настроить трансляцию адресов - это позволит контейнеру выходить в интернет через IP-адрес хоста
Для изоляции файловой системы внутри используются два основных системных вызова:
-
chroot- он изменяет корневую директорию для текущего процесса. Процесс и его потомки будут видеть указанную директорию как/Однако
chrootне изменяет окружение полностью и не предотвращает выход из изолированной среды -
pivot_root- более совершенный механизм, который перемещает корневую файловую систему текущего процесса в другую директорию, а на её место монтирует новуюЭтот системный вызов предпочтительнее для контейнеров, так как он позволяет корректно размонтировать старую корневую файловую систему и обеспечивает более строгую изоляцию
Для оптимизации дискового пространства используют объединенную файловую систему - она позволяет создать иллюзию того, что содержимое нескольких каталогов объединено в один, не изменяя при этом исходные файлы в этих каталогах
Одна из первых реализаций была UnionFS. Сейчас используют OverlayFS, которая устроена через три слоя:
- Нижний слой
lowerdir- один или несколько каталогов, доступных только для чтения. Они составляют файлы, из которых состоит контейнерный образ. - Верхний слой
upperdir- один каталог, доступный для чтения и записи. Сюда записываются все изменения, которые контейнер вносит в процессе работы. - Точка объединения
merged- виртуальный каталог, который видит процесс в контейнере. Он представляет собой результат объединения нижнего и верхнего слоя
Для обеспечения атомарности операций используется 4-ый каталог workdir
Когда процесс читает файл из merged, OverlayFS сначала ищет его в upperdir. Если его там нет, то файл ищется в lowerdir. Все операции записи (создание, изменение, удаление) всегда происходят только в upperdir
Создать объединенную файловую систему можно с помощью команды mount:
sudo mount -t overlay overlay \
-o lowerdir=$HOME/overlayEX/lower,upperdir=$HOME/overlayEX/upper,workdir=$HOME/overlayEX/work \
$HOME/overlayEX/merged
Сейчас на практике используют Docker - платформу контейнеризации, которая упрощает работу с пространствами имён, контрольными группами и объединёнными файловыми системами
Extra 3. Установка ПО, пакетные менеджеры
Данный конспект был основан на записи лекций №10 (*тык*), №11 (*тык*), №12 (*тык*) с канала А. В. Маятина
Скомпилированное ядро поставляется в виде сжатого образа vmlinuz, который содержит ПО, нужные модули для управления аппаратным обеспечением и интерфейс системных вызов для взаимодействия с ядром. Ядро не содержит:
- Оболочку, для взаимодействия с пользователей, такую как bash или графическую среду
- Компилятор
- И базовые утилиты, такие как
lsилиgrep
Само ядро также не умеет устанавливать стороннее ПО, а именно загружать пакеты с готовыми исполняемыми файлами, разрешать зависимости и делать так, чтобы установленная программа была доступна пользователю
Из-за этого установка ПО совершается кодом из пользовательского пространства системы. Ключевые проблемы появления программ, которые устанавливают ПО, это:
-
Разрешение зависимостей, то есть установка нужных библиотек и компонентов нужных версий, которые нужны для устанавливаемого ПО
Очень важно, чтобы зависимости были совместимы c конкретной версией ядра, с конкретным аппаратным обеспечением и с конкретной программой, которую мы устанавливаем
Также библиотеки не должны избыточно повторяться в системе, то есть по возможности несколько программ должны использовать один экземпляр библиотеки
-
Процедуры пред- и постустановки
Множество программ дополнительно требуют совершить действия перед или после их установки, например, добавление этой программы как сервис
systemd -
Удаление и очистка
Как правило, установленное ПО может записывать журналы, иметь базу данных, а также зависимости, которые нужны только этому ПО. Удаление исполняемого файла не очистить то, что эта программа породила
-
Стандартизация и воспроизводимость
При установке ПО библиотеки могут находиться в разных местах и иметь разные версии, из-за чего установка может давать разные результаты. Единая система установки позволяет добиваться воспроизводимой установки, используя согласованный набор версий пакетов
Всего есть 3 способа:
- Установка из исходного кода - пользователь скачивает архив с исходным кодом, далее пользователь сам находит нужные зависимости и компилирует программу
-
Установка из локального пакета
Пакет отличается от архива с исходным кодом тем, что содержит вместо кода готовый исполняемый файл и информацию о программе (версия, автор, зависимости). Также пакет содержит нужные скрипты, которые сами устанавливают нужные зависимости, решают конфликты других пакетов и их версий, а также добавляют программу в
/usr/binПользователю нужно лишь найти и скачать нужный пакет, вместо того, чтобы мучиться с установкой зависимостей
Эволюцией таких скриптов стал пакетный менеджер - специальная программа, которая хранит базу данных установленных пакетов, из-за чего может управлять зависимостями. Тогда пакету достаточно хранить всего лишь список нужных библиотек. Например, при удалении одного пакета менеджер может удалять его зависимости, но только те, которые не нужны другим установленным пакетам
-
Установка из удаленного репозитория
Современные пакетные менеджеры умеют скачивать пакеты из удаленных репозиториев. Удаленные репозитории представляют базы данных, которые хранят все версии пакетов, загруженных разработчиком, и полный список зависимостей. Также репозиторий гарантирует, что в нем окажутся все зависимости любого пакета
Удаленные репозитории также отвечают за безопасность предоставляемого ПО. Разработчик может криптографически подписать пакет своим приватным ключом. Далее при отправки репозиторий проверяет, что этот пакет действительно от этого разработчика
Современные дистрибутивы поставляют свои пакетные менеджеры:
- С дистрибутивами Ubuntu и Debian идет пакетный менеджер
dpkg(от Debian Package), который управляется черезapt(Advanced Package Tool) - С дистрибутивами Fedora и Red Hat Enterprise Linux идет
rpm(RPM Package Manager, ранее Red Hat Package Manager), который управляется через утилитуdnf(от Dandified YUM, буквально “изысканная вкуснятина”). Ранее вместоdnfиспользовалась утилитаyum(от Yellowdog Updater, Modified) - С дистрибутивом Arch Linux идет пакетный менеджер
pacman(сокращение от package manager)
- С дистрибутивами Ubuntu и Debian идет пакетный менеджер
Как правило последний способ самый удобный, так как, введя всего лишь одну команду (например, apt install fastfetch), можно установить программу и пользоваться. Но, чтобы пакет попал в удаленный репозиторий, он должен пройти нужные проверки, в том числе проверку на востребованность - затратно поддерживать пакет, который почти не востребован и к тому же усложняет граф зависимостей
Помимо этого дистрибутивов Linux очень много, поэтому делать пакеты для каждого дистрибутива осмелиться не каждый разработчик
По этой причине в Linux существуют все 3 способа
Помимо этих трех способов можно применить контейнеризацию, которая позволяет решить конфликты зависимостей и помогает более изолировать процессы, но такой подход сильно требует вычислительных ресурсов
Установка ПО из исходного кода
Как правило, исходный код хранится в архиве с расширением .tar.gz. Сначала каталог с файлами:
- преобразуется в несжатый архив с расширением
.tarс помощью утилиты tar, - а затем сжимается утилитой gzip, получая расширение
.tar.gz
Этот архив распаковывается в каталог. В каталоге есть скрипт, который указывает, как эту программу нужно собрать
В случае проектов на языке C используется утилита Make. Тогда в каталоге будет файл Makefile, в нем, как правило, указаны действия для 4 целей:
install- установка, то есть сборка программы и перенос программы в каталог/usr/binuninstall- деинсталляция программы, то есть удаление из/usr/binи ее зависимостейclean- очистка результатов и промежуточных файлов компиляцииdistclean- делает то, что иclean, но и удаляет конфигурацию- и другие цели по усмотрению разработчика
Также как правило архив содержит скрипт configure - этот скрипт создает конфигурацию и Makefile под эту систему. Дело в том, что установленный в системе библиотеки могут располагаться в разных местах. configure распознает, где установлены библиотеки, и создает нужный Makefile. Также configure позволяет управлять установкой, например, выбрать место установленной программы
Поэтому установка такой программы может быть выполнена тремя командами:
./configure # создание конфигурации
make # компиляция
make install # установка
Установка ПО из пакета
Если для выбранного ПО существует пакет под нужный дистрибутив, то можно установить его вместо сборки исходного кода
Исторически сложилось так, что разные дистрибутивы имеют разный формат пакетов, которые несовместимы между собой. Разница форматов появилась из-за различия архитектурных особенностей
Принципиально пакеты разных форматов ничем не отличаются, кроме организации файлов: пакет содержит исполняемый файл, метаинформацию о пакете, скрипты для конфигурации и постустановки. Поэтому такие утилиты, как alien, позволяют совершать конвертацию пакетов, но без гарантии результата
Рассмотрим два распространенных формата
Пакет формата deb
Такой формат используется в дистрибутивах Ubuntu, Debian, Linux Mint и других производных
Пакет формата deb представляет архив с расширением .deb (архивация происходит через утилиту ar). В этом архиве есть 3 файла в таком порядке:
- файл
debian-binary, который содержит версию формата пакета (сейчас это2.0) - архив
control.tar.gz - архив
data.tar.xz(расширение зависит от утилиты архивации)
В архиве control.tar.gz находятся файлы, которые не устанавливаются в систему напрямую, а используются пакетным менеджером dpkg для управления установкой. Ключевые файлы в нем:
-
control- основной файл с информацией о пакетеЗдесь хранятся название пакета, версия, архитектура, описание, а также зависимости, без которых программа не будет работать. Например,
controlдля бинарного пакета выглядит так:Package: fastfetch Version: 2.62.1+dfsg-1 Architecture: amd64 Maintainer: Hiago De Franco <hiago@defranco.dev.br> Installed-Size: 1915 Depends: libc6 (>= 2.38), libyyjson0 (>= 0.12.0+ds) Section: utils Priority: optional Multi-Arch: foreign Homepage: https://github.com/fastfetch-cli/fastfetch Description: neofetch-like tool for fetching system information Fastfetch is a neofetch-like tool for fetching system information and displaying them in a pretty way. It is written mainly in C, with performance and customizability in mind.Здесь:
Architecture- архитектура процессораDepends- зависимостиSection- раздел репозиторияPackage- уникальное имя пакетаVersion- версия программыMaintainer- контакты разработчика, который занимается упаковкой программыDescription- описаниеInstalled-Size- примерный размер, который пакет займет на диске после установки (в килобайтах)Priority- приоритет пакета для системы, в порядке убывания важности:Required,Important,Standard,Optional,Extra(упразднен)Homepage- ссылка на официальный сайт проекта
md5sums- контрольные суммы для каждого файла из архива данных для проверки файлов на повреждения или подмену- Всяческие опциональные скрипты обслуживания (обычно на языка Shell, но допустимы любые исполняемые файлы), такие как:
preinstзапускается перед установкойpostinstзапускается после установки (например, может запустить службу в systemd)prermзапускается перед удалениемpostrmзапускается после удаления
conffiles- список файлов, которые считаются конфигурационными. При обновлении пакетаdpkgне будет их просто перезаписывать, а задаст вопрос, что делать с изменениями
В другом архиве data.tar.gz содержатся файлы, которые будут скопированы в файловую систему: исполняемые файлы, библиотеки, документация и так далее. Пути к файлам внутри архива указываются относительно корня файловой системы. Содержимое архива может выглядеть так:
usr
├── bin
│ └── flashfetch
└── share
├── fastfetch
│ └── presets
│ └── ...
├── man
│ └── man1
│ └── fastfetch.1
└── ...
Таким образом, программа dpkg:
- распаковывает внешний архив
- читает
control.tar.gzи проверяет зависимости из файлаcontrol - выполняет скрипт
preinst - извлекает файлы из
data.tar.gzв соответствующие места в системе (в примере выше добавятся/usr/bin/fastfetch, страницы для утилитыmanи другое) - выполняет скрипт
postinst
Источник: https://manpages.debian.org/unstable/dpkg-dev/deb.5.en.html
Помимо создания пакетов с готовыми программами, формат предполагает создание пакетов с исходным кодом. Такой пакет состоит из 3 частей:
<пакет>_<версия>.dsc(Debian Source Control) - текстовый файл с метаданными исходного пакета. Он содержит короткую версиюcontrol, контрольные суммы архивов ниже и подпись разработчика<пакет>_<версия>.orig.tar.xz- архив с немодифицированным исходным кодом программы-
<пакет>_<версия>-<ревизия>.debian.tar.xz- архив, содержащий все файлы, добавленные мейнтейнером этого пакета для Debian, содержащий только папкуdebianВ этой папке есть свой
debian/control, и выглядит он так:Source: fastfetch Section: utils Priority: optional Maintainer: Hiago De Franco <hiago@defranco.dev.br> Uploaders: Carlos Henrique Lima Melara <charlesmelara@riseup.net>, Maytham Alsudany <maytham@debian.org>, Rules-Requires-Root: no Build-Depends: cmake, debhelper-compat (= 13), directx-headers-dev, libchafa-dev, ... Standards-Version: 4.7.2 Homepage: https://github.com/fastfetch-cli/fastfetch Vcs-Browser: https://salsa.debian.org/debian/fastfetch Vcs-Git: https://salsa.debian.org/debian/fastfetch.git Package: fastfetch Architecture: any Multi-Arch: foreign Depends: ${shlibs:Depends}, ${misc:Depends}, Description: neofetch-like tool for fetching system information Fastfetch is a neofetch-like tool for fetching system information and displaying them in a pretty way. It is written mainly in C, with performance and customizability in mind.Здесь:
Source- имя исходного пакета, из которого будут собраны один или несколько бинарных пакетовUploaders- сопровождающие, имеющие право загружать пакет в архив DebianBuild-Depends- зависимости, необходимые для сборки исходного пакета в бинарныеStandards-Version- версия политики Debian, которой соответствует пакетVcs-BrowserиVcs-Git- ссылки на репозиторий пакета в системе контроля версий Debian
Дальше идут блоки, начинающиеся с
Package, - они описывают готовые после сборки пакеты (тут таковой один)Также эта папка содержит:
debian/rules- правила сборки (обычно это файл для утилиты Make)debian/copyright- информация о правообладателя кодаdebian/changelog- журнал изменений- опциональные скрипты
debian/preinst,debian/postinst,debian/prerm,debian/postrm - опционально
debian/install- инструкция для утилитыdh_install, которая сообщает, какие файлы из исходников нужно скопировать в бинарный пакет debian/source/format- версия формата пакета, сейчас это3.0 (quilt)для пакетов, где дистрибутив не важен, и3.0 (native)для пакетов, которые есть только в Debian (в них нет архива.orig.tar.xz)- опционально
debian/configиdebian/templates- скрипт и шаблоны диалогов для системыdebconf, которая позволяет задавать пользователю вопросы в процессе установки пакета и сохранять ответы для последующей настройки
Дальше из этих двух архивов с помощью утилиты dpkg-buildpackage собирает готовый пакет .deb
Пакет формата rpm
Такой формат используется в дистрибутивах Red Hat Enterprise Linux, Fedora, CentOS, AlmaLinux, openSUSE, Oracle Linux и других
Пакет формата rpm - не просто архив ar, а архив с расширением .rpm со своими полями:
- Заголовок (Lead), 96 байт, содержит магическое число (которое идентифицирует архив как
rpm), версию формата и указание на то, является ли пакет бинарным или исходным Сейчас распространены две версии формата:V4, более стабильная версия, иV6, более продвинутая - Подпись (Signature) разработчика, которая гарантирует, что пакет не был поврежден или подменен злоумышленником
- Заголовок метаданных (Header) содержит проверки зависимостей, разрешения конфликтов, определения, куда и какие файлы устанавливать, и выполнения скриптов до и после установки
- Полезная нагрузка (Payload) - содержимое пакета в виде архива (обычно сжатый утилитой
cpio), содержащий все файлы, которые будут установлены в систему Чтобы извлечь содержимое, можно использовать утилитуrpm2cpio
Сама полезная нагрузка содержит файлы, которые будут скопированы в файловую систему, наподобие как сделано в пакетах формата deb, например:
usr
├───bin
│ fastfetch
├───lib
│ └───...
└───share
├───doc
│ └───fastfetch
│ README.md
├───fastfetch
├───man
│ └───man1
│ fastfetch.1.gz
└───...
Исходный пакет, который содержит исходный код программы и имеет расширение .src.rpm, устроен иначе, в нем вместо одного архива в полезной нагрузки есть:
- файл
<пакет>.spec - архив
<пакет>-<версия>.tar.gz, содержащий исходный код программы
Здесь проявляется ключевое отличие пакета rpm от пакета deb: вместо множества файлов в пакете rpm вся информация хранится в файле <пакет>.spec. Этот файл может выглядеть так:
Name: fastfetch
Version: 2.61.0
Release: 1%{?dist}
Summary: Fast neofetch-like system information tool
License: MIT
URL: https://github.com/fastfetch-cli/fastfetch
Source0: %{url}/archive/%{version}/%{name}-%{version}.tar.gz
BuildRequires: cmake
...
BuildRequires: yyjson-devel
Recommends: hwdata
Suggests: libXrandr
...
Suggests: elfutils-libelf
ExcludeArch: %{ix86}
%description
fastfetch is a neofetch-like tool for fetching system information and
displaying them in a pretty way. It is written in c to achieve much better
performance, in return only Linux and Android are supported. It also uses
mechanisms like multithreading and caching to finish as fast as possible.
%prep
%autosetup -p1
%build
%cmake -DBUILD_TESTS=ON -DENABLE_SYSTEM_YYJSON=ON -DBUILD_FLASHFETCH=OFF
%cmake_build
%check
%ctest
%install
%cmake_install
%files
%license LICENSE
%doc README.md
%{_bindir}/%{name}
%{_datadir}/%{name}/
%{_mandir}/man1/fastfetch.1*
%{_datadir}/bash-completion/completions/%{name}
%{_datadir}/fish/vendor_completions.d/%{name}.fish
%{_datadir}/zsh/site-functions/_%{name}
%changelog
<журнал изменений>
Сначала идет преамбула. Она содержит метаданные самого пакета:
Name- имяVersion- версияRelease- релизSummary- краткое описаниеLicense- лицензияURL- страница проектаGroup- группа репозитория (по сути категория)- а также перечисление
Source(исходные файлы) иPatch(патчи), они могут быть указаны как локальный архив или архив на удаленном сервере BuildRequires- зависимости сборки программыRequires- зависимости самой программыObsoletes- пакеты, которые заменяет этот пакетConflicts- пакеты, которые конфликтуют с этим пакетомExclusiveArch- зависимость от архитектуры процессора
На основе этих тегов формируется стандартное имя пакета: Name-Version-Release.Architecture.rpm
Потом идет тело файла, которое состоит из серии секций, каждая из которых отвечает за свой этап сборки. Основные из них это:
%description- подробное описание программы%prep- подготовка исходного кода (распаковка архива, применение патчей)%build- компиляция и сборка исходного кода%install- установка скомпилированных файлов Как правило, секцию%installпишут так, чтобы операции в ней были обратимыми, поэтому секции%uninstallнет%check- запуск тестов для проверки работоспособности собранного ПО%post- скрипты, выполняющиеся после установки%clean- очистка после сборки%preun- подготовка перед удалением установленной программы%postun- скрипты, выполняющиеся после удаления установленной программы%files- важный список всех файлов и директорий, которые должны попасть в итоговый бинарный пакет%changelog- журнал изменений
Сам пакет формата rpm устанавливается утилитой rpm. Эта утилита умеет только устанавливать пакет из уже скачанного файла. Чтобы загружать зависимости и пакеты из удаленного репозитория, существуют другие утилиты:
- Утилита
yum(от Yellowdog Updater, Modified), написанная на Python, из-за чего обход графа зависимостей (а следовательно установка пакета) работает медленно -
Утилита
dnf(от Dandified YUM, буквально “изысканная вкуснятина”), написанная на C++dnfбыстрее работает, имеет хорошую документацию, и аккуратно убирает зависимости
Сейчас из-за проблем с совместимостью yum все еще поставляется с дистрибутивами
Extra 4. Графические подсистемы
Данный конспект был основан на записи лекций №13 (*тык*) и №14 (*тык*) с канала А. В. Маятина
Ключевым отличием операционной системы Linux от систем Windows и macOS для рядового пользователя - это различия во взаимодействии пользователя с системой. В Windows и macOS преимущественно используется графический интерфейс или GUI (Graphical User Interface), тогда как в Linux исторически и архитектурно используется интерфейс командной строки или CLI (Command Line Interface)
Рассмотрим, как устроен графический интерфейс в Windows от компании Microsoft. Предком современной системы Windows была система MS-DOS (от MicroSoft Disk Operating System), в нем в качестве интерфейса была командная строка
Это не мешало отдельным программам иметь текстовый интерфейс (TUI, Text User Interface) или графический интерфейс (например, в играх):
Однако при запуске пользователя встречала командная строка. Позднее в 1985 году вышла Windows 1.0 - система, которая представляла графическую оболочку и базовые приложения для MS-DOS. После нее выходили Windows 2.0, Windows 3.0 и другие. Так выглядела Windows For Workgroups 3.11:
В те времена пользователи отдельно покупали MS-DOS и версию Windows. Вплоть до Windows 3.2 система Windows была надстройкой для MS-DOS, но в Windows 95 графический оболочка была полностью встроена в ядро (несмотря на это MS-DOS остался для поддержки обратной совместимости):
С тех пор графический интерфейс в Windows является главным интерфейсом для взаимодействия с системой
В Unix и Unix-подобных системах, стоявших у истоков универсальных операционных систем, главным интерфейсом была командная строка
Когда речь зашла о разработке графической оболочки для обычных пользователей, решили выбрать клиент-серверную архитектуру
Так появился X Window System - базовый протокол, описывающий взаимодействие между программами, которые хотят отрисовать свое содержимое, и графической оболочкой. В X Window System:
- Сервер (он же X-сервер) - это программа, которая управляет локальными ресурсами, то есть монитором, клавиатурой, мышью и прочим. Сервер принимает входные данные с мыши и клавиатуры и отрисовывает полученное содержимое на монитор
- Клиент (он же X-клиент) - это прикладная программа, которая хочет что-то отобразить (например, браузер)
Сервер и клиент общаются через сокеты, что обеспечивает сетевую прозрачность: сервер и клиент могут находится на разных компьютерах, предоставляя тем самым удаленный доступ
Альтернативой X Window System является протокол Wayland - о нем рассказано позже
История X Window System
X Window System появилась внутри Массачусетского института технологий. Разработкой руководили Боб Шайфлер и Джим Геттис, а первый публичный релиз состоялся 19 июня 1984 года
После этого в 1986 году, появилась версия X10, которая быстро распространялась среди пользователей Unix. В сентябре 1987 года вышла 11-ая версия протокола - X11. Протокол был насколько хорошо спроектирован, что с тех пор его базовая версия практически не менялась, а новые возможности добавлялись через расширения
После выхода реализации протокола X11R2 (здесь R - это от “релиз”) в январе 1988 года управление проектом перешло от MIT к консорциуму X MIT (MIT X Consortium), который финансировали компании DEC и IBM. Эта и будущие реализации публиковались под лицензией MIT
Параллельно независимые разработчики адаптировали код X11R4 для работы с графическими картами с VGA на IBM-совместимых компьютерах, что привело к появлению в 1991 году реализации X386 1.1 - название отражало 32-битный процессор Intel 386 на архитектуре x86, который использовался в IBM-совместимых компьютерах. Позднее это ответвление было переименовано в XFree86
В 1993 году была образована некоммерческая корпорация X Consortium, Inc., которая продолжила выпуск новых версий X11R6 и X11R6.1
Далее произошел релиз XFree86 2.0 в 1994 году и последующие версии, такие как XFree86 3.x, активно развивались и к концу 1990-х годов стали фактическим стандартом X-сервера для Linux и многих других Unix-подобных систем
31 декабря 1996 года X Consortium, Inc. прекратил свое существование, и все права на X Window System перешли к The Open Group
В феврале 2004 года вышла реализация XFree86 4.4.0, где была изменена лицензия на менее свободную XFree86 License 1.1. В результате этого в апреле 2004 года был основан фонд X.Org Foundation. 6 апреля 2004 года вышла реализация X11R6.7.0, которая стала первым сервером от X.Org. Сейчас же последний релиз - это X11R7.7, который вышел в 2012 году
Большинство дистрибутивов выбрало сервер от X.Org, и с тех пор X.Org Foundation управляет развитием и поддержкой X Window System и выпускает ее эталонную реализацию под лицензией MIT
Сейчас X.Org Server имеет другую нумерацию, и последняя версия 21.1.14 вышла в 2024 году
Архитектура X Window System
Как уже было подмечено, в Linux графический интерфейс устроен по клиент-серверной архитектуре: приложения-клиенты отправляют данные о том, что отрисовывать на реализацию сервера, который поддерживает протокол X11 (например X.Org Server)
Для упрощения разработки приложения используют библиотеку Xlib, которая реализует протокол X11 на стороне клиента и позволяет приложениям общаться с X-сервером
Сам протокол состоит из 4 видов сообщений:
- Запрос приложения-клиента серверу, например, создать новое окно
- Ответ сервера приложению-клиенту, например, позиция курсора
- Событие, произошедшие на сервере, такие как нажатие клавиши
- Ошибка в ответ на запрос
Протокол устроен асинхронно, то есть клиент и сервер не дожидаются ответа перед тем, как послать новое сообщение, что делает графический интерфейс приложений отзывчивым. Для явной синхронизации используется специальный метод библиотеки Xlib
Для подключения клиенты используют переменную среды DISPLAY. Она состоит из строки в формате [хост]:номер_дисплея[.номер_экрана], в которой:
хост- IP-адрес машины, где запущен X-сервер (если не указан, значит клиент подключается к сервере на том же компьютере)номер_дисплея- номер виртуального терминала, где запущен X-сервер (обычно0)номер_экрана- номер монитора, подключенного к компьютеру (если не указан, то клиент подключается к основному экрану)
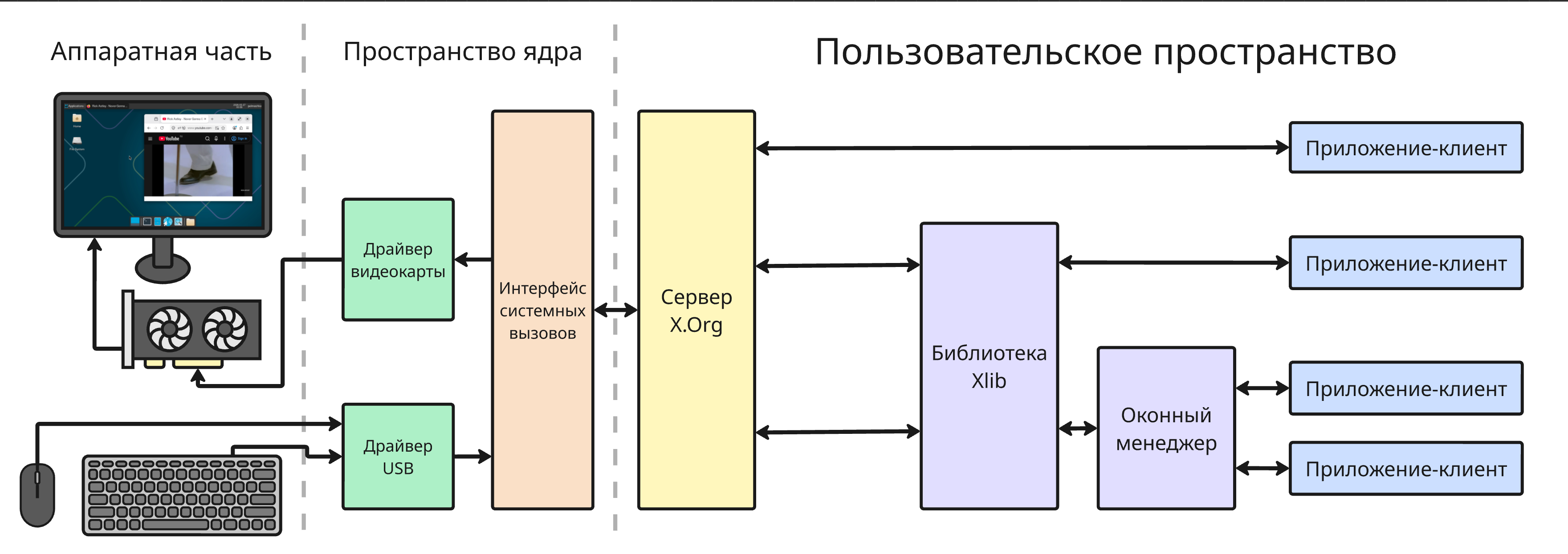
Чтобы запустить сервер X.Org из терминала, нужно:
- Запустить графическую сессию с помощью команды
startx, которая является оберткой над программойxinit - Далее
startxзапускает скрипт в файле~/.xserverrc, где указан X-сервер (по умолчанию это X.Org). Сервер переводит монитор в графический экран - После этого
startxзапускает скрипт в файле~/.xinitrc(если его нет, то используется файл/etc/X11/xinit/xinitrc) для запуска первого главного приложения-клиента - При выходе из приложения-клиента X-сервер автоматически останавливается, и оболочка переходит в режим консоли
Таким клиентом может быть программа xterm - эмулятор терминала для графического режима. xterm стал первым приложением, которое показало работоспособность протокола X Window System
Оконный менеджер
Сам протокол X11 и сервер, реализующий его, не описывают стратегии размещения окна. При запуске сервер X.Org рисует “корневое окно”, состоящее из одноцветного фона (обычно черного) и курсора в форме креста. Такой режим полезен для компьютеров, выполняющих функцию киоска
Расположением окон управляет оконный менеджер (Window Manager). Оконный менеджер позволяет запускать несколько приложений в графическом режиме и управлять положение и размерам их окон. Всего различают три типа оконных менеджеров:
- Мозаичные менеджеры представляют окна в виде непересекающихся областей, что делает их нетребовательными к ресурсам
- Стековые менеджеры позволяют размещать окна так, что одно из них пересекает другое, из-за чего часть рабочей области этого окна не видна
- Композитные менеджеры позволяют задать тени или частичную прозрачность окон
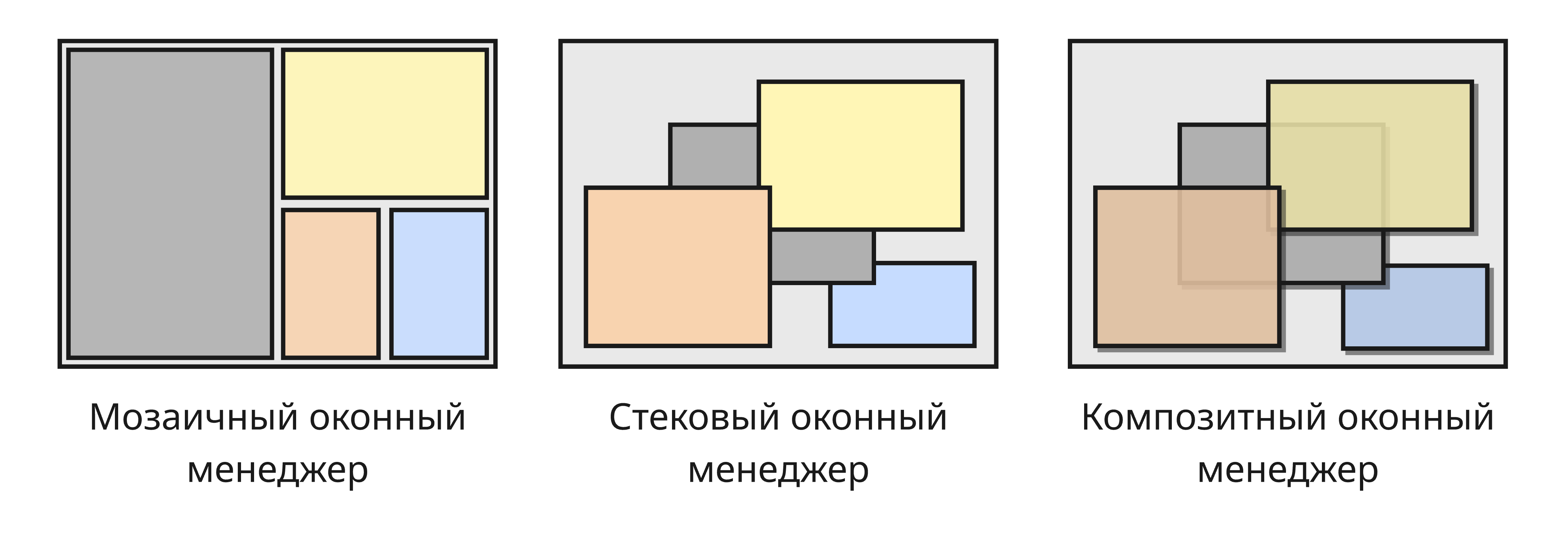
Такие оконные менеджеры могут добавлять дополнительные элементы интерфейса к окнам программ, например, рамку с заголовком программы и кнопками “Закрыть”, “Свернуть”, “Развернуть” или панель задач, где указаны запущенные программы
Оконный менеджер для startx можно указать в файле ~/.xinitrc
Расширенные графические среды
Эволюцией оконных менеджеров являются расширенные графические среды (Extended Graphical Environment, XGE)
Расширенная графическая среда (или среда рабочего стола, Desktop Environment) предоставляет свой оконный менеджер и набор базовых программ для работы внутри среды, таких как проигрыватель, файловый менеджер и так далее
В Linux распространены две графических среды:
-
KDE Plasma (от K Desktop Environment)
Сообщество KDE было основано в ходе разработки графической среды. Среда от KDE представляет из себя один из крупнейших проектов с открытым исходным кодом, содержащий миллионы строк кода
Среда KDE основана на фреймворке Qt, написанном на языке C++, который предоставляет широкий инструментарий для создания графических интерфейсов, например, классы элементов интерфейса, классы виджетов, классы для работы с сетевыми протоколами, классы для работы с интерфейсом OpenGL. Также Qt предоставляет множество инструментов для разработки и локализации приложений
KDE также предоставляет оконный менеджер KWin и базовый набор приложений:
- Amarok - проигрыватель
- Dolphin - файловый менеджер
- Kdeadmin - инструменты для администрирования
- KDevelop - среда разработки приложений для KDE
- Konqueror - веб-браузер (сейчас используется Falkon - браузер на основе Chromium)
- Konsole - эмулятор терминала
- Kontact - клиент электронной почты и менеджер контактов
- KDE Connect - приложение для интеграции телефона с компьютером
- и много других, включая игры и приложения для обучения
Как можно заметить, приложения KDE имеют в названии букву K
-
GNOME (от GNU Network Object Model Environment)
Когда KDE начала свое развитие, среда использовала версию фреймворка Qt, которая распространялась под проприетарной лицензией. Поэтому как альтернатива была создана среда GNOME, которая использует код только под открытой лицензией
GNOME использует графическую библиотеку GTK (от GIMP ToolKit), созданную для программы GIMP и написанную на языке C, которая использует низкоуровневую библиотеку GLib
GNOME использует менеджер окон Mutter (до этого использовался Metacity) и предоставляет свой набор программ:
- Totem - проигрыватель
- Nautilus - файловый менеджер
- GnomeSystemTools - инструменты для администрирования
- Web - веб-браузер
- GNOME Terminal - эмулятор терминала
- Evolution - менеджер контактов
Эти среды являются довольно ресурсозатратными, поэтому есть множество других менее распространенных и легких графических сред:
-
Xfce - легковесная среда, компоненты которой следуют философии Unix. Использует GTK
-
Cinnamon - среда, основанная на GNOME и появившаяся в ответ на изменения в GNOME 3. Используется в Linux Mint
-
Mate - среда, являющаяся форком GNOME 2
Для конечного пользователя среды предоставляют схожий набор программ, поэтому у части дистрибутивов нет конкретного выбор графических сред, например, Fedora поставляется в двух изданиях - с KDE и с GNOME
Графические среды тем временем представляют риск безопасности системы:
- Запускать от пользователя
rootсреду нельзя, так как вредные программы или злоумышленник, имеющие физический доступ к компьютеру, могут завладеть компьютером - Механизм
sudo, запущенный от лица пользователя, дает полные и неограниченные права суперпользователя в системе, что крайне опасно
Поэтому разработчики из Red Hat во главе с Дэвидом Цойтеном предложили принципиально иной подход, который и был реализован в библиотеке PolicyKit
Основная идея PolicyKit - это не давать приложению права суперпользователя, а предоставлять только те полномочия, которые необходимы для выполнения конкретного действия. Процесс остается непривилегированным, но может попросить специальный системный демон polkitd выполнить за него высокорискованную операцию. В отличие от sudo, который повышает привилегии для всего процесса, PolicyKit авторизует одно действие в рамках уже запущенной программы
Также PolicyKit вводит понятие централизованной политики - администратор системы может с помощью простых правил (обычно в XML-файлах) определить, кто и при каких условиях может выполнять то или иное действие
Дисплейный менеджер
При запуске системы Linux по умолчанию показывает текстовое приглашение входа в консоли, что затем позволяет пользователю запустить X-сервер и графическую среду. Такой подход не является дружелюбным, поэтому появились дисплейные менеджеры
Дисплейный менеджер решает проблему ручного запуска графической сессии. Он сразу после загрузки:
- Предоставляет графический интерфейс для ввода имени пользователя и пароля
- Позволяет выбрать сеанс, то есть графическую среду, например, GNOME на Wayland или KDE Plasma
- После аутентификации запускает сеанс от имени пользователя, а сам работает с привилегиями
При запуске:
- Система загружается, запускается
systemd - Включается графическая цель
graphical.target, которая запускает сервис дисплейного менеджера - Дисплейный менеджер поднимает X-сервер (или Wayland) на виртуальном терминале
- Появляется экран входа. После успешного входа дисплейный менеджер запускает сеанс пользователя:
- Для X11 записывает
DISPLAY=:0и запускает оконный менеджер или среду - Для Wayland запускает композитор
- Для X11 записывает
Сейчас популярные дисплейные менеджеры это:
- GDM (GNOME Display Manager), используется в Ubuntu, Fedora
- SDDM (Simple Desktop Display Manager), написан на Qt и используется в KDE
- LightDM, легковесный и гибкий, используется в Xubuntu, Lubuntu
- XDM, идет в составе X.Org
Wayland
Несмотря на успешность X11, со временем накопилось несколько фундаментальных проблем:
- Любой X-клиент может читать ввод с клавиатуры и содержимое других окон, нет изоляции
- При отрисовке контента данные часто копируются несколько раз
- Двойная буферизация и устранение разрывов кадров реализованы через расширения
В 2008 году Кристиан Хогсберг (работавший над X-сервером в Red Hat) начал разработку Wayland - новое протокола графического сервера. Главная идея была в том, что сервер не рисует сам, а только управляет поверхностями, клиенты же рисуют напрямую через буферы, передавая их серверу для компоновки
Архитектура Wayland включает композитор Wayland. Композиторы Wayland - это одновременно оконные менеджеры и серверы
Ключевые особенности Wayland:
- Композитор имеет доступ только к тем буферам, которые отправил клиент. Нельзя перехватить ввод другого окна без явной поддержки протокола
- Клиент может использовать OpenGL/Vulkan и рисовать прямо в разделяемую память, минуя лишние копирования
- Композитор всегда ждёт вертикальной синхронизации, что убирает разрывы кадров
Сейчас большинство дистрибутивов (Fedora, Ubuntu, Debian и другие) используют Wayland в основных редакциях
Для обратной совместимости с существующими X-клиентами запускается XWayland - X-сервер, который рисует не на реальном экране, а в окно Wayland
Несмотря на это, Wayland имеет свои недостатки:
- Некоторые программы, зависящие от особенностей X11 работают только через XWayland с ограничениями
- Сетевой прозрачности в Wayland нет “из коробки”